Практическая работа № 21
«Сканирование и распознавание текста»
Содержание урока
1. Подготовьте бумажную страницу с печатным текстом, которую вы собираетесь сканировать.
2. Выполните сканирование в черно-белом режиме (оттенки серого) с разрешением 300 ppi и глубиной кодирования цвета 8 бит на пиксель (256 оттенков серого).
3. С помощью программы или онлайн-сервисов (например, http://en.pdf24.org/onlineConverter.html) преобразуйте полученную картинку в формат PDF.
4. Найдите в Интернете информацию о формате DjVu.
5. Используя сервис http://any2djvu.djvuzone.org/, преобразуйте картинку в формат DjVu. Сравните качество и размеры полученных PDF-файла и DjVu-файла.

6. Выполните распознавание текста с помощью программы (например, CuneiForm) или онлайн-сервисов, например:
http://www.newocr.com/
http://www.free-ocr.com/
http://www.ocronline.com/
http://www.onlineocr.net/
http://finereader.abbyyonline.com/
7. Сохраните результат распознавания в виде документа в формате DOC и исправьте ошибки распознавания, если они были. Затем преобразуйте документ в формат PDF.
8. Преобразуйте полученный PDF-документ в формат DjVu (с помощью сервиса http://any2djvu.djvuzone.org/) и сравните размеры полученных файлов, заполнив таблицу:
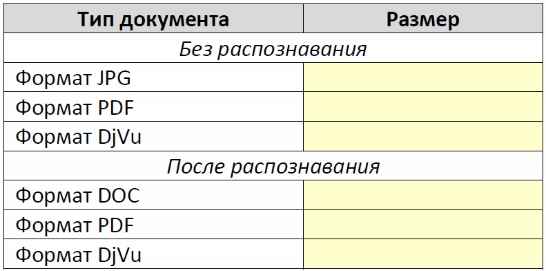
9. Отсканируйте ту же страницу с разрешениями 200 ppi, 150 ppi и 100 ppi, и проверьте, как изменяется качество распознавания. Сделайте выводы.
10. Попробуйте отсканировать и распознать страницу документа, содержащего рисунки, таблицы и формулы. Сделайте выводы.
