Уроки 48 - 49
§2.3. Системы оптического распознавания символов
Содержание урока
Оптическое распознавание символов
Алгоритмы оптического распознавания
Оптическое распознавание документов
Оптическое распознавание изображений
Мультиязычность систем оптического распознавания
Системы оптического распознавания форм
Системы распознавания рукописного текста
Практическая работа 2.7 Оптическое распознавание документов в формате изображений
Практическая работа 2.7
Оптическое распознавание документов в формате изображений
Аппаратное и программное обеспечение. Компьютер с установленной операционной системой  Windows или
Windows или  Linux с подключенным сканером.
Linux с подключенным сканером.
Цель работы. Научиться распознавать документы в формате изображений с использованием системы распознавания ABBYY FineReader в операционной системе Windows и системы распознавания Коока в операционной системе Linux.
Задание. Распознать документы в формате изображений с использованием системы распознавания ABBYY FineReader в операционной системе Windows и системы распознавания Коока в операционной системе Linux.
Распознавание с использованием системы распознавания ABBYY FineFeader
1. В операционной системе Windows запустить систему распознавания ABBYY FineReader.
2. В появившемся диалоговом окне FineReader получить графическое изображение документа путем сканирования (щелкнуть по кнопке Сканировать), либо путем открытия готового графического файла (щелкнуть по кнопке Открыть).
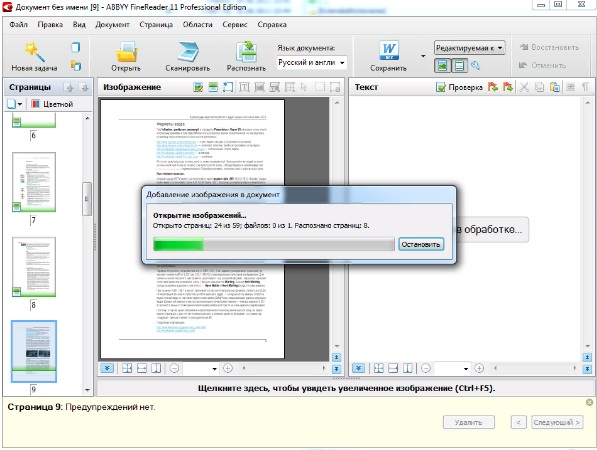
3. Для преобразования графического изображения документа в текстовый формат щелкнуть по кнопке Распознать.
В правой части окна FineReader появится текстовый документ.
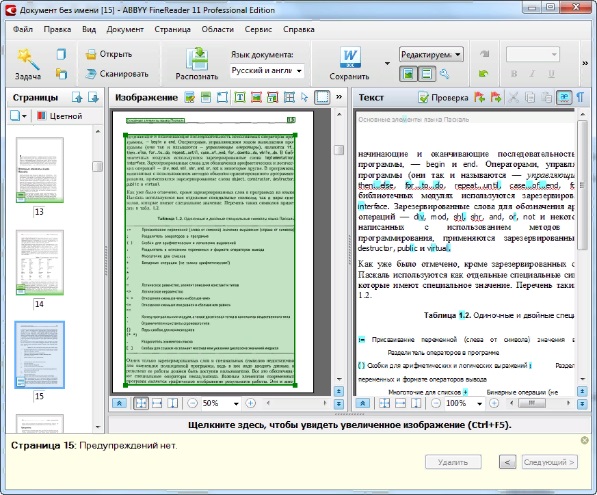
4. Для сохранения отсканированного и распознанного текстового документа в определенном приложении выбрать из списка это приложение (например, Microsoft Word). Для выбора формата сохраняемого текстового документа щелкнуть по кнопке Форматы и в появившемся диалоговом окне Форматы выбрать формат.
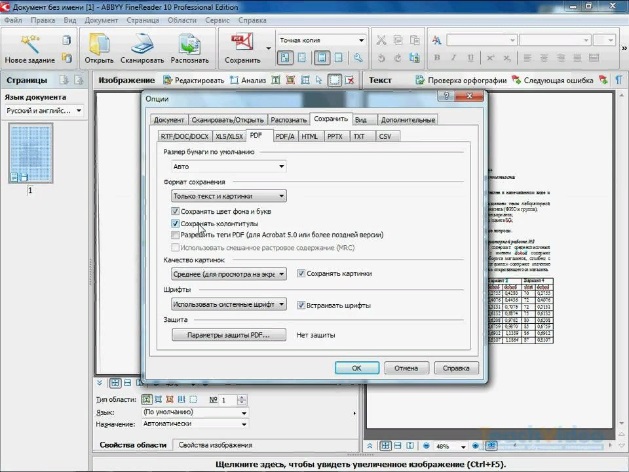
Распознавание с использованием системы распознавания Коока
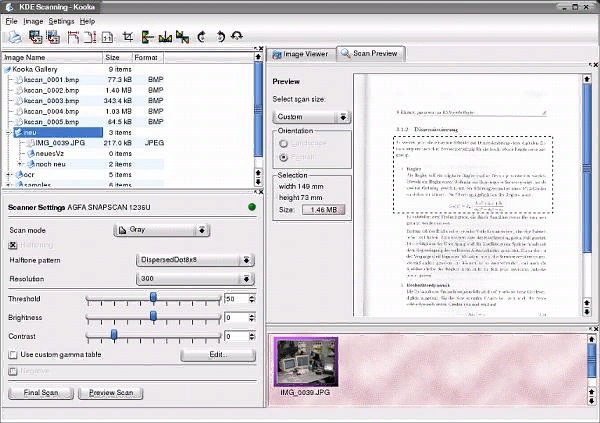
1. В операционной системе Linux запустить систему распознавания Коока.
2. В левой части диалогового окна Коока с помощью ползунков Разрешение, Scan speed, Brightness и Contrast установить подходящие для данного изображения текста значения.
С помощью раскрывающегося списка Scan mode выбрать нужный тип сканирования.
Щелкнуть по кнопке Сканировать, в правой части диалогового окна Kooka появится отсканированное изображение документа.
Ввести команду [Изображение-Распознать текст из всего изображения...].
Появится окно, содержащее распознанный текст документа.
Следующая страница  Оптическое распознавание символов
Оптическое распознавание символов
Cкачать материалы урока
