Системный кэш
Системный кэш (system cache) вносит значительный вклад в повышение
производительности современных РС. Кэш представляет собой буфер между очень
быстрым процессором и относительно медленной системной памятью, которая
обслуживает процессор. Заметим, что память совсем не медленная, но все же ее
быстродействие уступает скорости процессора. Наличие кэша позволяет процессору
выполнять операции, обращаясь к памяти намного реже, чем при отсутствии кэша.
Отметим, что в прошлом кэш часто назывался сверхоперативным запоминающим
устройством.
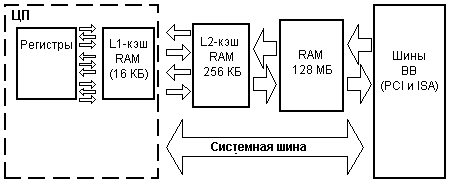
В современных РС фактически есть несколько уровней (level), или слоев
(layer), кэша. Обычно без специального уточнения слово кэш подразумевает
кэш второго уровня
(Level 2, L2), или вторичный кэш (secondary cache), который находится
между процессором и системным RAM. Далее рассматриваются все уровни кэша, но
основное внимание уделяется вторичному кэшу.
Уровни кэша
В современном РС имеется несколько уровней кэша. В них не включаются кэши, имеющиеся в некоторых периферийных устройствах, например в жестких дисках. Каждый уровень ближе к процессору и быстрее того уровня, который находится ниже его. Каждый уровень кэширует находящиеся ниже его уровни благодаря своему более высокому быстродействию:
Уровень |
Кэшируемые устройства |
Кэш уровня 1 |
Кэш уровня 2, системная память RAM, жесткий диск и CD-ROM |
Кэш уровня 2 |
Системная память RAM, жесткий диск и CD-ROM |
Системная память RAM |
Жесткий диск и CD-ROM |
Жесткий диск и CD-ROM |
-- |
Вот что происходит в процессе работы РС. Процессор запрашивает фрагмент информации. Прежде всего он обращается к самому быстрому L1-кэшу. Если он находит там нужную информацию (это называется попаданием - hit), процессор использует ее почти без задержки. Если же информации в L1-кэше нет (это называется промахом - miss), происходит поиск в L2-кэше. Когда нужная информация имеется в L2-кэше (попадание), она считывается с относительно небольшой задержкой. В противном случае (промах в L2-кэше) процессор вынужден обращаться к системной памяти RAM. В свою очередь, RAM либо содержит запрашиваемую информацию, либо должно получить ее с еще более медленного жесткого диска или CD-ROM. Отметим, что фактически памятью и кэшем управляет чипсет.
Важно отчетливо представлять себе, насколько некоторые устройства медленнее процессора. Даже самые быстрые жесткие диски имеют время обращения порядка 10 мс, поэтому ожидая 10 мс процессор с частотой 200 МГц впустую расходует два миллиона тактов синхронизации! А накопители CD-ROM примерно в десять раз медленнее жестких дисков. Поэтому применение кэшей, позволяющих избежать обращений к медленным устройствам, значительно повышает производительность РС.
Фактически кэширование выходит за рамки аппаратных средств. Например, в
web-броузере реализовано два уровня кэширования. Поскольку загрузка страницы из
Internet производится довольно медленно, броузер сохраняет ранее просмотренные
страницы для ускорения их повторной загрузки. Броузер вначале проверяет свой кэш
в памяти, а затем кэш на жестком диске, не содержат ли они копию запрашиваемой
страницы. Только при отсутствии страницы в кэше броузер считывает ее из
Internet.
L1-кэш, или первичный кэш
Ll-кэш, или первичный кэш (primary cache) является самой быстрой памятью
в РС, поскольку он встроен в сам процессор. Емкость этого кэша невелика, обычно
от 8 до 64 Кбайт, но быстродействие очень велико, так как он работает с такой же
скоростью, что и процессор. Ситуация, когда процессор запрашивает информацию и
находит ее в L1-кэше, оказывается наиболее благоприятной с точки зрения
производительности, так как ожидать ее не нужно. Подробнее L1-кэш рассмотрен в
главе о процессорах.
L2-кэш, или вторичный кэш
L2-кэш является вторичным кэшем по отношению к L1-кэшу; он имеет большую емкость
обычно от 64 КБ до 4 МБ, но действует несколько медленнее. L2-кэш применяется
для "захвата" недавних обращений, которые не "захвачены" L1-кэшем. Вторичный кэш
находится на материнской плате или на дочерней плате (daughterboard), которая
вставляется в материнскую плату. В процессоре Pentium Pro L2-кэш размещен в
одном и том же корпусе, что и процессор (хотя и не на одном кристалле с
процессором и L1-кэшем); такой кэш работает значительно быстрее L2-кэша на
материнской плате. В процессорах Pentium II кэш работает с половинной скорости
процессора.
L3-кэш (TriLevel Cache)
При проектирования подсистемы кэша действует общее правило: большой и быстрый
кэш обеспечивает более высокую производительность компьютера. Компания AMD
разработала новейшую архитектуру кэша, значительно расширяющую возможности РС,
базирующихся на платформе Super7. Реализованная в процессоре AMD-K6-III новая
технология трехуровневого кэша (TriLevel Cache) значительно улучшает
производительность компьютера за счет самого большого из применяемых сейчас
кэша, емкость которого в четыре раза превышает емкость кэша процессоров Pentium
III.
Дисковый кэш
Дисковый кэш (disk cache) представляет собой область системной памяти, которая используется для кэширования операций считывания и записи жесткого диска. В некоторых отношениях он является наиболее важным кэшем в РС из-за огромной диспропорции скоростей системной памяти RAM и жесткого диска. Хотя системная память RAM несколько медленнее L1-кэша и L2-кэша, жесткий диск намного медленнее системной памяти RAM.
В отличие от памяти L1-кэша и L2-кэша, которая полностью отводится для
кэширования, системная память RAM используется не только для кэширования, но и
для других целей. Обычно дисковый кэш реализуется специальными программами,
например SmartDrive.
Периферийный кэш
Аналогично жесткому диску и другие устройства можно кэшировать с помощью
системного RAM. Например, практически всегда кэшируются накопителя CD-ROM, что
объясняется очень медленным начальным обращением в десятки миллисекунд.
Фактически иногда накопители CD-ROM кэшируются на жесткий диск, так как жесткий
диск намного быстрее накопителя CD-ROM.
Назначение и работа системного кэша
В этом разделе обсуждаются принципы организации кэша и подробно рассматривается работа L2-кэша. Внутренний L1-кэш во многом похож на L2-кэш по ассоциативности, организации, определению попаданий и др. Однако в деталях реализации эти два типа кэшей различаются.
Примечание: Здесь излагаются довольно сложные вопросы,
поэтому рекомендуется читать материал по-порядку и вначале изучить работу
системной памяти.
Как работает кэш
Кэш представляет собой удивительное образование. L2-кэш емкостью 512 КБ, кэширующий системную память 64 МБ, может предоставлять запрашиваемую процессором информацию в 90-95% времени. Только вдумайтесь в приведенные цифры: кэш, емкость которого меньше 1% емкости кэшируемой памяти, может регистрировать "попадания" в более чем 90% запросов. Именно по причине столь высокой эффективности кэширование играет очень важную роль.
Работа кэша опирается на принцип локальности обращений (locality of reference). Он гласит, что при выполнении даже огромных программ в несколько мегабайтов одновременно используется только незначительные части кода. Программы расходуют значительное время, работая с одной небольшой областью кода, который часто реализует одни и те же операции с несколько отличающимися данными, а затем переходит к другой области. Такое положение объясняется широким использованием в программах циклов (loops).
Предположим, к примеру, что вы запустили текстовый процессор и открыли свой любимый документ. Программа текстового процессора в некоторый момент должна считать файл и отобразить на экране считанный текст. В упрощенном варианте эти действия выполняет примерно такой код:
- Открыть файл документа.
- Открыть экранное окно.
- Для каждого символа в документе:
- Считать символ.
- Сохранить символ в рабочей памяти.
- Записать символ в окно, если символ является частью первой страницы.
- Закрыть файл документа.
Цикл образуют три команды, которые выполняются для каждого символа в документе. Эти команды повторяются многие тысячи раз, а в приложениях имеются сотни или тысячи подобных циклов. Всякий раз при нажатии клавиши PgDn на клавиатуре текстовый процессор должен очищать экран, определять отображаемые следующими символы и затем выполнять аналогичный цикл для копирования символов из памяти на экран. Для сохранения файла на жестком диске также приходится выполнять несколько циклов.
Этот пример показывает, почему кэширование повышает производительность при выполнении программного кода, а как же быть с данными? Не трудно догадаться, что обращение к данным, например рабочим файлам, так же является повторяющимся. Сколько раз при работе с текстовым процессором вы производите скроллинг ("прокрутку") вверх и вниз вновь и вновь отыскивая один и тот же текст в процессе редактирования? Системный кэш хранит значительную часть этой информации, поэтому при необходимости ее можно загрузить во второй раз, третий раз и т.д.
В рассмотренном примере для считывания символов из файла, сохранения их в рабочей памяти и записи на экран использовался цикл. При первом выполнении команд цикла (считывание, сохранение, запись) их необходимо загрузить из относительно медленной системной памяти (в предположении, что они находятся в памяти, так как в противном случае их придется загружать с намного более медленного диска).
Кэш (аппаратно) запрограммирован на хранение содержания ячеек памяти, к которым производились недавние обращения на тот случай, если оно потребуется вновь. Поэтому каждая из приведенных команд сохраняется в кэше после первой загрузки из памяти. Когда процессору потребуется в следующий раз использовать ту же самую команду, он вначале проверит, не находится ли нужная команда в кэше, и загрузит ее из кэша, а не из медленной системной памяти. Число буферированных таким способом команд зависит от емкости и организации кэша.
Предположим, что цикл должен обработать 1000 символов и кэш может хранить все
три команды цикла. Это означает, что 999 раз из 1000 (т.е. 99.9% времени)
выполнений команд они будут загружаться из кэша. Именно поэтому кэши может
удовлетворить большой процент запросов памяти, хотя емкость его часто составляет
менее 1% емкости системной памяти.
Компоненты L2-кэша
L2-кэш состоит из двух основных компонентов. Обычно физически не размещаются в одних и тех же микросхемах, но логически связаны и обеспечивают правильную работу кэша. Вот эти компоненты:
- Память данных (data store): В этой памяти фактически хранится кэшированная информация. Когда выполняется операция "сохранить что-то в кэше" или "считать что-то из кэша", участвующие в операции данные помещаются в память данных или считываются из памяти данных. Когда говорят о емкости кэша 256 КБ или 512 КБ, подразумевается емкость памяти данных. Чем больше емкость этой памяти, тем больше информации можно кэшировать и тем выше вероятность удовлетворения запроса из кэша.
- Тэговая память RAM (tag RAM): Это небольшая область памяти, используемая кэшем для слежения за тем, каким ячейкам памяти принадлежат элементы в памяти данных. Емкость тэговой RAM (а не емкость памяти данных) управляет тем, сколько основной памяти можно кэшировать.
В дополнение к этим памятям, конечно же, имеется схема контроллера кэша. В
современных РС значительную долю нагрузки по управлению L2-кэшем несет
системный чипсет (system chipset).
Структура памяти данных
Многие полагают, что кэш организован как большая последовательность байтов. Фактически же в РС пятого поколения и выше L2-кэш организован как набор длинных строк кэша (cache lines), каждая из которых содержит 32 байта (256 битов). Это означает, что в каждой операции считывания или записи кэша производится передача 32 байтов; невозможно считать или записать только один байт. Такая организация объясняется причинами производительности. Как минимум, невозможно иметь в строке кэша меньше 64 битов, так как шина данных процессоров Pentium имеет ширину 64 бита. Ширина памяти данных в 256 битов объясняется тем, что обращение к памяти производится четырьмя пакетами, а 4 х 64 равно 256.
Рассмотрим кэш емкостью 512 КБ (это память данных). Чтобы мысленно
представить себе структуру этой памяти, нужно вместо одного длинного столбца с
524 288 (512 K) отдельными рядами представить 32 столбца и 16 384 (16 K) рядов.
Каждое обращение к памяти данных производится к строке (ряду), поэтому кэш имеет
16 384 различных адресов.
Отображение и ассоциативность кэша
Важным фактором в определении эффективности L2-кэша является то, как кэш отображается (mapped) на системную память. Имеется много способов распределения "хранилища" кэша на адреса обслуживаемой им памяти. Как пример, рассмотрим РС, имеющий L2-кэш 512 КБ и основную память 64 МБ. Возникает сложный вопрос о том, как разделить 16 384 адресов строк кэша между "огромной" памятью 64 МБ?
Имеются три основных способа отображения. Выбор способа отображения настолько важен при разработке кэша, что кэш часто называется в соответствии с выбранным способом:
- Кэш с прямым отображением (Direct Mapped Cache): Простейший способ распределения кэша системной памяти заключается в том, чтобы определить, сколько строк кэша имеется (в нашем примере - 16 384) и просто разбить системную память на такое же число блоков. При этом каждый блок может использовать одну строку кэша, Этот способ называется прямым отображением (direct mapping). Поэтому при наличии 64 МБ адресов основной памяти каждую строку кэша будут разделять 4096 адресов памяти (64 M деленное на 16 K).
- Полностью ассоциативный кэш (Fully Associative Cache): Вместо жесткого распределения строк кэша конкретным ячейкам памяти возможно разработать кэш так, что любая строка может хранить содержание любой ячейки памяти. Такой способ называется полностью ассоциативным отображением (fully associative mapping).
- N-направленный ассоциативный по множеству кэш (N-Way Set Associative
Cache):
Здесь "N" является числом, обычно 2, 4, 8 и т.д. Такой кэш представляет
собой компромисс между кэшем с прямым отображением и полностью ассоциативным
кэшем. В этом случае кэш разбивается на множества (sets), причем каждое
множество содержит "N" строк кэша, например 4. Тогда каждый адрес памяти
присваивается множеству и может кэшироваться в любом из этих 4 мест внутри
присвоенного ему множества. Другими словами, внутри каждого множества кэш
является ассоциативным, чем и объясняется его название.
В этой структуре имеется "N" возможных мест кэша, в которых может находиться заданная ячейка памяти. Компромисс заключается в том, что имеется "N" ячеек памяти, конкурирующих за одни и те же "N" строк в множестве. Предположим, например, что применяется 4-направленный ассоциативный по множеству кэш. Здесь вместо одного блока из 16 384 имеется 4096 множеств по 4 строки в каждом. Каждое из множеств разделяется 16 384 адресами памяти (64 M деленное на 4 K) вместо 4096 адресов в случае кэша с прямым отображением. Таким образом, здесь разделяется больше строк (4 вместо одной), но и больше адресов разделяют их (16 384 вместо 4096).
В общем, кэш с прямым отображением и полностью ассоциативный кэш являются
частными случаями N-направленного ассоциативного по множеству кэша. Можно
установить "N" = 1, чтобы получить "1-направленный" ассоциативный по множеству
кэш. В этом случае каждое множество состоит из одной строки, а это эквивалентно
кэшу с прямым отображением, так как каждый адрес памяти указывает только на одно
возможное место в кэше. С другой стороны, если сделать "N" действительно
большим, например установить "N" равным числу строк в кэше (16 384 в нашем
примере), то получится только одно множество, содержащее все строки кэша и
каждая ячейка памяти показывает на это огромное множество. Это означает, что
любой адрес памяти может быть в любой строке, т.е. получается полностью
ассоциативный кэш.
Сравнение способов отображения кэша
Существует критичный компромисс в производительности кэша, который и привел к созданию рассмотренных способов отображения кэша. Чтобы кэш имел хорошую производительность, желательно максимизировать оба следующих параметра:
- Коэффициент попаданий (hit ratio): Желательно максимально повысить вероятность того, что кэш содержит требуемые процессору адреса памяти. В противном случае преимущества кэширования пропадают из-за большого числа промахов.
- Скорость поиска (search speed): Желательно максимально быстро определять, произошло ли попадание в кэше. В противном случае небольшой временной интервал расходуется на поиск в кэше при каждом обращении (попадании или промахе).
Рассмотрим эти параметры для трех типов кэша:
- Кэш с прямым отображением: Это простейший кэш, в котором проще
всего определять попадание. Так как имеется только одно место, в которое
может кэшировать любая ячейка памяти, искать просто нечего; строка либо
содержит отыскиваемую информацию, либо не содержит.
К сожалению, кэш с прямым отображением имеет наихудшую производительность, так как имеется только одно место, в котором можно сохранить любой адрес. Вернемся к нашему примеру с L2-кэшем 512 КБ и системной памяти 64 МБ. Напомним, что данный кэш имеет 16 384 строк (предполагая 32-байтовые строки кэша) и каждая строка разделяется 4096 адресами памяти. В самом худшем случае предположим, что процессору требуются два разных адреса (назовем их X и Y), которые отображены на одну и ту же строку кэша в чередующейся последовательности (X, Y, X, Y). Это может произойти в небольшом цикле. Процессор загрузит X из памяти и сохранит его в кэше. Затем он будет искать в кэше Y, но Y использует ту же строку, что и X, поэтому его в кэше не будет. Поэтому Y загружается из памяти и сохраняется в кэше для будущего использования. Но затем процессор запрашивает X, а находит в кэше только Y. Данный конфликт повторяется вновь и вновь. Конечный результат состоит в том, что коэффициент попаданий равен 0%. Конечно, мы рассмотрели наихудший сценарий, но, в общем, производительность для такого способа отображения оказывается худшей. - Полностью ассоциативный кэш: Такой кэш имеет наилучший коэффициент
попаданий, так как любая строка в кэше может содержать любой адрес, который
требуется кэшировать. Это означает, что проблема, которая характерна для
кэша с прямым отображением, снимается из-за отсутствия единственной строки,
который должен использовать адрес.
Однако в таком кэше возникают проблемы поиска в кэше. Если каждый адрес может храниться в любой из 16 384 строк, то как узнать, где он находится? Даже при использовании для поиска специальных схем производительность снижается. Причем снижение происходит для всех обращений к памяти, независимо от того, получается попадание или нет, так как для определения попадания необходимо выполнить поиск. Кроме того, при необходимости добавления нового элемента потребуются дополнительные схемы, чтобы определить используемые строки (обычно для определения используемой следующей строки применяется алгоритм Least Recently Used - LRU - наиболее давно используемая). Все эти схемы усложняют кэш, удорожают его и увеличивают время поиска. - N-направленный ассоциативный по множеству кэш: Такой кэш оказывается приемлемым компромиссом между кэшем с прямым отображением и полностью ассоциативным кэшем. Рассмотрим 4-направленный ассоциативный по множеству кэш. Здесь каждый адрес может кэшироваться в любом из четырех мест. Это означает, что в примере для кэша с прямым отображением, где мы попеременно обращались к двум адресам, отображенным на одну и ту же строку кэша, теперь они должны отображаться на одно и то же множество. Это множество имеет 4 строки, поэтому одна может хранить X, а другая Y. При этом коэффициент попаданий повышается с 0% почти до 100%! Конечно, это предельный случай. Что касается поиска, его нетрудно реализовать, так как каждое множество имеет только 4 строки для проверки, хотя и при этом небольшом поиске требуются дополнительные схемы для определения того, какую строку кэша использовать при считывании "свежих" данных из памяти. По-прежнему, для этого обычно применяется разновидность алгоритма LRU.
Приведем сводную таблицу, показывающую способы отображения кэша и обеспечиваемые ими относительные производительности:
Тип кэша |
Коэффициент попаданий |
Скорость поиска |
Кэш с прямым отображением |
Плохой |
Наилучшая |
Полностью ассоциативный кэш |
Наилучший |
Средняя |
N-направленный ассоциативный по множеству кэш, N>1 |
Очень хороший, лучше при увеличении N |
Хорошая, хуже при увеличении N |
На практике наиболее распространены кэш с прямым отображением и ассоциативный
по множеству кэш. Кэш с прямым отображением используется для L2-кэша на
материнских платах, а более производительный ассоциативный по множеству кэш чаще
используется во внутреннем L1-кэше.
Память тэгов
Поскольку каждая строка (или множество) в памяти данных разделяется большим числом адресов памяти, которые отображаются на нее (него), необходимо следить за тем, какой адрес использует каждую строку кэша в данный момент времени. Именно для этого и применяется память тэгов (tag RAM).
Вновь рассмотрим предыдущий пример: РС с основной памятью 64 МБ, кэшем 512 КБ и строками кэша по 32 байта. Здесь имеется 16 384 строк кэша и поэтому каждую строку разделяют 4096 различных адресов памяти. Но напомним, что каждая строка состоит из 32 байтов, т.е. в каждой строке можно поместить различных 32 байта. В результате получается, что имеется 129 (4096 деленные на 32) различных 32-байтовых строк памяти, которые разделяют ячейку кэша.
Для адресации памяти 64 МБ требуется 26 линий адреса (так как 2^26 равно 64 М), которые нумеруются от A0 до A25. Для 512 КБ требуется только 19 линий от A0 до A18. Разность составляет 7 линий, так как 128 = 2^7. Эти 7 линий адреса сообщают, какой из 128 различных адресов, которые может использовать строка кэша, фактически используются ею в данный момент. Именно для этого и предназначена тэговая память. Элементов в тэговой памяти столько же, сколько в памяти данных, поэтому получается 16 384 элементов тэговой памяти, но эти элементы значительно короче 32-байтовых элементов памяти данных.
Отметим, что тэговая память привлекается как можно раньше в процессе
обращения к памяти для определения наличия или отсутствия попадания в кэше. Это
означает, что независимо от быстродействия памяти данных тэговая память должна
быть несколько быстрее.
Как используется адрес памяти
Адрес памяти от процессора представляет собой адрес байта, необходимого процессору. Для проверки попадания контроллер кэша разбивает его на три секции. Для нашего примера (память 64 МБ, кэш 512 КБ, более простой кэш с прямым отображением), поэтому мы имеем 26 битов адреса от A0 до A25:
- A0 - A4: Младшие 5 битов представляют 32 различных байта в памяти данных (2^5 = 32). Напомним, что просматриваемый кэш имеет 32-байтные строки, считающиеся законченными единицами. Поэтому контроллер кэша игнорирует биты адреса A0 - A4; процессор будет использовать их впоследствии, определяя какой байт использовать из 32 байтов, полученных из кэша.
- A5 - A18: Эти 14 битов представляют строку кэша, на которую отображается адрес. Напомним, что 2^14 = 16 384, т.е. равно полному числу строк кэша. Этот адрес строки кэша используются для поиска адреса тэга в памяти тэгов и затем фактических данных в памяти данных, если зарегистрировано попадание.
- A19 - A25: Эти 7 битов представляют адрес тэга, который указывает системе, какая из возможных ячеек памяти, которые разделяют строку кэша (определяемую линиями адреса A5 - A18), сейчас использует ее.
Если использованные для примера числа изменяются, соответственно меняются и
диапазоны адресов. Так, при наличии памяти 32 МБ, кэша 128 КБ и 16-байтовых
строк кэша игнорируются биты адреса A0 - A3, биты A4 - A16 представляют адрес
строки кэша и биты A17 - A24 являются адресом тэга.
Политика записи кэша и бит Dirty (грязный)
В дополнение к кэшированию считываний из памяти система может кэшировать и записи в память. Обработка битов адреса, строк кэша и т.п. выполняется так же, как и при считывании. Однако имеются два способа обработки кэшем записи, которые называются политикой записи (write policy) кэша.
- Кэш с обратной записью (write-back cache): Эта политика обеспечивает полное кэширование записи системной памяти. Когда производится запись в ячейку системной памяти, которая в данный момент кэширована, новые данные записываются только в кэш и фактически не записываются в системную память. Впоследствии, если другой ячейке памяти требуется использовать строку кэша, в которой запомнены эти данные, они сохраняются (записываются назад - written back) в системную память и затем строку может использовать новый адрес.
- Кэш со сквозной записью (write-through cache): В этом способе всякий раз, когда процессор записывает в кэшированную ячейку памяти, обновляются и кэш, и соответствующая ячейка памяти. По существу, это похоже на "полукэширование" (half caching) записей; данные просто записываются в кэш на тот случай, если их вскоре будет считывать процессор, но сама запись фактически не кэшируется, так как всякий раз приходится инициировать запись в память.
Многие кэши с обратной записью можно настроить на работу со сквозной записью (однако, не все), а противоположная настройка обычно невозможна.
В общем, обратная запись обеспечивает лучшую производительность, но с незначительным риском целостности памяти (memory integrity). Кэширование с обратной записью позволяет системе не производить множества ненужных циклов записи в системную память, что заметно ускоряет выполнение программ. Однако при использовании кэширования с обратной записью данные в кэшированные ячейки помещаются только в кэш, а сама системная память фактически не обновляется до тех пор, пока не приходится освобождать строку кэша для того, чтобы освободить место для использования ее другим адресом.
В результате в любой момент времени может возникнуть рассогласование между многими строками в кэше и адресами памяти, которым они соответствуют. В этом случае данные в памяти называются "устаревшими" (stale), так как в них нет новой информации, которая только что была записана в кэш. При использовании кэша со сквозной записью память никогда не может "устареть", поскольку запись в системную память производится при каждом записи в кэш.
Обычно "устаревшая" память не вызывает проблем, потому что контроллер кэша следит за тем, какие ячейки в кэше изменены и какие ячейки памяти вследствие этого "устарели". Для этого привлекается дополнительный бит в каждой строке памяти, называемый битом "грязный" (dirty bit). Когда запись кэшируется этот бит устанавливается в 1, сообщая контроллеру кэша: "когда ты решишь повторно использовать данную строку кэша для другого адреса, необходимо записать ее содержание в память". Обычно бит "грязный" реализуется добавлением дополнительного бита в тэговую память.
Однако использование кэша с обратной записью влечет небольшую вероятность искажения данных, если что-то произойдет до того, как "грязные" строки кэша смогут быть сохранены в памяти. Конечно, таких ситуаций совсем мало, так как память и кэш являются энергозависимыми, т.е очищаются при выключении РС.
С другой стороны, рассмотрим дисковый кэш, когда системная память используется для кэширования записей на жесткий диск. Здесь память оказывается энергозависимой, а жесткий диск - нет. Когда применяется кэш с обратной записью, на диске могут оказаться устаревшие (по сравнению с памятью) данные. Если питание выключается, теряется все, что еще не записано на диск, а это может привести к искажениям данных. Поэтому большинство дисковых кэшей позволяют программам отменять политику обратной записи для обеспечения согласования между кэшем ( в памяти) и диском.
Во многих кэшах можно также скомандовать контроллеру "сейчас же запиши в
системную память все грязные строки кэша". Эта операция выполняется, когда
необходимо гарантировать согласование кэша с памятью, т.е. чтобы не было
устаревших данных. Иногда такую операцию называют "выгрузкой" (flushing) кэша и
она часто выполняется в дисковых кэшах (см. выше).
Процесс операции считывания и записи в кэше
После обсуждения всех компонентов кэша и принципов его построения мы подробно рассмотрим, что фактически происходит, когда процессор инициирует операцию считывания и записи системной памяти. Для примера взят РС, имеющий память 64 МБ, кэш 512 КБ с прямым отображением и строки кэша по 32 байта:
- Процессор инициирует операцию считывания или записи системной памяти.
- Одновременно контроллер кэша начинает проверять, содержится ли запрошенная информация в памяти, а контроллер памяти начинает операцию считывания или записи системной памяти. Обращение к памяти производится для того, чтобы не терять времени в случае промаха в кэше; когда в кэше регистрируется попадание, система при необходимости отменяет частично выполненный обращение к системной памяти. В случае кэша со сквозной записью операция записи в память всегда продолжается.
- Контроллер кэша контролирует попадание, анализируя адрес от процессора. Младшие пять битов (A0 - A4) игнорируются, потому что они выделяют один из 32 байтов в строке кэша. Они не нужны, так как кэш всегда возвратит в процессор все 32 байта, а процессор определяет, какой байт ему нужен. Следующие 14 битов адреса (A5 - A18) определяют подлежащую проверке строку кэша (отметим, что 2^14 равно 16 384).
- Контроллер кэша считывает из тэговой памяти по адресу, определяемому 14 линиями адреса A5 - A18. Если, например, они содержат адрес 13 714, контроллер будет проверять содержание элемента #13 714 тэговой памяти. Он сравнивает считанные из тэговой памяти 7 битов с 7 битами адреса A19 - A25, полученными от процессора. Если они одинаковы, контроллер знает, что элемент в кэше с этим адресом строки необходим процессору, т.е. имеется попадание. Если тэговая память не соответствует, имеется промах.
- В случае попадания в операции считывания контроллер кэша считывает 32-байтовое содержание памяти данных кэша по тому же адресу строки, который определяется битами A5 - A18 (13 714), и посылает его в процессор. Инициированная в системной памяти операция считывания отменяется и на этом вся операция закончена. При записи контроллер записывает 32 байта в память данных в ту же сроку кэша, которую определяют биты A5 - A18. Затем при использовании кэша со сквозной записью производится запись в системную память; в случае кэша с обратной записью операция записи в системную память отменяется и бит "грязный" для этой строки кэша устанавливается в 1, показывая, что кэш обновился, а системная память нет.
- В случае промаха в операции считывания выполняется инициированное ранее считывание из системной памяти и 32 байта считываются из памяти по адресу A5 - A25. Эти байты подаются в процессор, который по пяти младшим битам A0 -A4 адреса определяет требуемый ему байт. При этом кэш должен тоже сохранить в своей памяти данных эти только что считанные из системной памяти байты в расчете, что они вскоре понадобятся. При использовании кэша со сквозной записью 32 байта просто помещаются в память данных по адресу, который определяют биты A5 - A18. Содержание битов A19 - A25 сохраняется в тэговой памяти по тому же 14-битовому адресу A5 - A18. Теперь элемент кэша готов к последующему запросу процессора. При использовании кэша с обратной записью до перезаписи старого содержания строки кэша необходимо проверить бит "грязный" этой строки. Если он установлен в 1, то необходимо вначале записать содержание строки кэша в память, а затем сбросить бит "грязный". Если же этот бит сброшен в 0, то содержание системной памяти не "устарело" и запись в нее производить не нужно.
- В случае промаха в операции записи кэш ничего не должен выполнять, так как большинство кэшей не обновляет строку кэша при промахе в операции записи. Кэш просто оставляет прежнее содержание и производится запись в системную память, полностью обходя кэш. Однако некоторые кэши всегда записывают данные в память данных при выполнении операций записи. Они опираются на предположение, что все только что записанное процессором в большой вероятностью потребуется в ближайшем будущем. Следовательно, они полагают, что каждая запись по определению оказывается попаданием. Другими словами, при записи попадание не проверяется и строка кэша, соответствующая адресу записи, всегда заменяется выданными процессором данными. Это означает также, что при промахе в записи контроллер кэша должен обновлять кэш, включая проверку бита "грязный" до записи, таким образом, как это выполняется в случае промаха при считывании.
Конечно, рассмотренный довольно сложный пример еще более усложняется при
использовании ассоциативного по множеству или полностью ассоциативного кэша.
Здесь при проверки попадания необходимо производить поиск и определять, какую
строку кэша обновлять при промахе.
Характеристики кэша
В этом разделе обсуждаются характеристики L2-кэша, которые необходимо
учитывать при выборе материнской платы или модернизации кэша. Особенный упор
сделан на производительность кэша.
Скорость (быстродействие) кэша
Нет единственного числа, которое полностью определяло бы "скорость" системного кэша. Поэтому приходится учитывать "сырую" скорость используемых компонентов, а также необходимых для них схем. Анализ скорости кэша во многом аналогичен соответствующему анализу скорости системной памяти.
Под "raw" скоростью кэша понимается быстродействие образующих его микросхем. Обычно для кэша применяются микросхемы статического RAM (SRAM) в отличие от микросхем динамического RAM (DRAM) для системной памяти. Микросхемы SRAM быстрее, но и дороже микросхем DRAM. Быстродействие SRAM составляет 5 - 10 нс, а DRAM 30 - 60 нс.
Быстродействие микросхем определяет верхний предел производительности, к которому должны стремиться разработчики материнских плат и чипсетов. Рассмотрим материнскую плату с процессором Pentium, имеющую скорость шины памяти 66 МГц, т.е. такт составляет 15 нс. Чтобы материнская плата считывала из кэша за один такт, скорость микросхем SRAM должна быть меньше 15 нс (из-за служебных потерь точно 15 нс не хватает). Если микросхемы SRAM окажутся быстрее, выигрыша производительности не будет, а если медленнее, то возникнут проблемы с временной диаграммой, которые проявляются как ошибки памяти и зависание системы.
Тэговая память в составе кэша обычно должна быть быстрее памяти данных кэша. Это объясняется тем, что вначале необходимо считывать из тэговой памяти, проверяя наличие попадания. Необходимо проверить тэг и иметь в случае попадания достаточное время для считывания из кэша в одном такте синхронизации. Например, может оказаться, что микросхемы памяти данных кэша имеют скорость 15 нс, а микросхемы тэговой памяти 12 нс.
Чем сложнее способ отображения кэша, тем более важным оказывается разница скоростей тэговой памяти и памяти данных. Простые способы отображения, например прямое отображение, обычно не требуют большой разницы. В этом случае можно использовать для всего кэша микросхемы с одной и той же скоростью; если, например, системе требуется 15 нс для тэговой памяти и 16 нс для памяти данных, спецификация материнской платы просто определяет 15 нс для всего, потому что это проще. В любом случае, если материнская плата не поставляется с установленным L2-кэшем, необходимо приобретать память в соответствии с руководство на материнскую плату.
Истинная скорость любого кэша, т.е. насколько быстро он производит передачи в процессор и из процессора для ускорения приложений, зависит от схемы контроллера кэша и других схем чипсета. Возможности чипсета определяют, какие виды передач может использовать кэш. Это, в свою очередь, определяет оптимальную временную диаграмму кэша, т.е. число тактов синхронизации для передачи данных в кэш и из кэша.
Очевидно, производительность кэша сильно зависит от скорости, на которой
работает подсистема кэша. В типичном РС с процессором Pentium этой скоростью
является скорость шины памяти 66 или 100 МГц. Однако в процессоре Pentium Pro
есть интегрированный L2-кэш, который работает с полной скоростью процессора,
например 180 или 200 МГц. Для процессора Pentium II применяется L2-кэш на
дочерней плате, который работает на половинной скорости процессора.
Емкость кэша
Под емкостью кэша обычно понимается емкость его памяти данных, в которой хранится содержание ячеек памяти. В типичном РС емкость L2-кэша составляет 512 КБ или 1024 КБ, но может доходить и до 2 МБ. Емкость внутреннего L1-кэша обычно составляет от 16 КБ до 64 КБ.
Чем больше емкость кэша, тем более вероятней регистрация попадания при обращении к памяти, так как одну и ту же строку кэша разделяют меньше ячеек системной памяти. Рассмотрим прежний пример РС, имеющего память 64 МБ, кэш с прямым отображением 512 КБ и 32-байтовые строки памяти. При этом получается, что есть 16 384 строк кэша (512 К, деленные на 32). При увеличении емкости кэша до 1 МБ получится 32 768 строк кэша и каждую будут разделять 2048 адресов. Если же оставить кэш 512 КБ и увеличить системную память до 256 МБ, то каждую из 16 384 строк кэша будут разделять 16 384 адреса.
Если имеется кэш 256 КБ и системная память 32 МБ, то увеличение кэша на 100%
до 512 КБ приведет к повышению коэффициента попаданий менее чем на 10%.
Повторное удвоение емкости повысит коэффициент попаданий менее чем на 5%. На
практике такое различие для большинства пользователей почти незаметно. Однако
при увеличении емкости системной памяти целесообразно увеличить и емкость кэша,
чтобы предотвратить снижение производительности. Но при этом необходимо
учитывать кэшируемость (cacheability) системного RAM.
Кэшируемость системного RAM
Кэшируемость системного RAM оказывается наиболее запутанной характеристикой подсистемы кэша. Емкость RAM, которую может кэшировать система очень важен при необходимости использовать большую память. Почти все РС пятого поколения способны кэшировать системную память 64 МБ. Однако многие РС, даже новые, не могут кэшировать более 64 МБ. Популярные чипсеты 430FX ("Triton I"), 430VX (один из "Triton II"s, называемый также "Triton III") и 430TX не могут кэшировать больше 64 МБ системной памяти, а РС с этими чипсетами выпущено многие миллионы штук.
Если увеличить память сверх предела кэшируемости, производительность ухудшится. Когда часть памяти не кэшируется, система должна обращаться к памяти при каждом обращении к некэшируемой области, которая намного медленнее кэша. Кроме того, при работе с мультизадачной операционной системой невозможно управлять, где заканчивается кэшируемая память и начинается некэшируемая память.
На емкость кэшируемой памяти влияет чипсет и ширина тэговой памяти. Чем больше памяти в РС, тем больше линий адреса необходимо для определения адреса. Это означает, что приходится хранить больше битов адреса в тэговой памяти, чтобы проверять регистрацию попадания. Разумеется, если чипсет не рассчитан на кэширование более 64 МБ, расширение тэговой памяти совершенно не поможет.
Наиболее популярным чипсетом, поддерживающим кэширование сверх 64 МБ, является 430HX ("Triton II") фирмы Intel. Отметим, что кэширование сверх 64 МБ считается для него необязательным (optional) и производитель материнской платы должен обеспечить использование 11-битовой тэговой памяти вместо принимаемой по умолчанию 8-битовой. Дополнительные три бита увеличивают кэшируемость с 64 МБ до 512 МБ.
Многие пользователи путаются в емкости системной памяти и кэшируемости. Часто полагают, что увеличение кэша позволит кэшировать большую память, но реально кэшируемостью управляют тэговая память и чипсет.
Процессор Pentium Pro использует встроенный L2-кэш с тэговой памятью, поэтому здесь вопрос о кэшируемости не стоит - процессор будет кэшировать системную память емкостью до 4 ГБ. Процессор Pentium II использует дочернюю плату SEC и может кэшировать до 512 МБ.
Часто спрашивают - "насколько замедляется система при использовании большей
системной памяти, чем она может кэшировать?" Простого ответа на этот вопрос нет,
так как он зависит от РС и того, что на нем выполняется. Наиболее вероятное
ухудшение производительности составляет от 5% до 25%. Специально подчеркнем, что
избежать сильного замедления можно добавлением реальной физической памяти, чтобы
система не использовала виртуальной памяти. При напряженной мультизадачности и
"пробуксовке" системы всегда лучше иметь больше памяти, даже некэшируемой, а не
заставлять систему обращаться к намного более медленному жесткому диску. Но,
разумеется, предпочтительней иметь всю память кэшируемой.
Интегрированный кэш и отдельные кэши данных и команд
Большинство (практически все) L2-кэшей работают с данными и командами процессора
(программы). Они не различают их, считая просто адресами памяти. Однако во
многих процессорах применяется разделенный L1-кэш. Например, в "классическом"
процессоре Pentium (P54C) имеется кэш 8 КБ для данных и отдельный кэш 8 КБ для
команд. При этом повышается эффективность благодаря конструкции процессора, но
незначительно влияет на производительность по сравнению с единым кэшем 16 КБ.
Каждый из отдельных кэшей может иметь различные характеристики, например
использовать разные способы отображения, как в процессоре Pentium Pro.
Способы отображения
На эффективность кэша, т.е. коэффициент попаданий и скорость, влияет способ отображения. Мы уже рассматривали их и вкратце упомянем три способа отображения:
- Кэш с прямым отображением (direct mapped cache): Каждая ячейка памяти отображается на единственную строку кэша; только один из множества адресов, разделяющих эту строку, может использовать ее в любой момент времени. Это простейший способ отображения. Схемы для проверки попадания оказываются несложными и быстрыми, но коэффициент попаданий хуже, чем в других способах отображения. В системном кэше на материнской плате обычно применяется именно этот способ отображения.
- Полностью ассоциативный кэш (fully associative cache): Любая ячейка памяти может кэшироваться в любой строке кэша. Это самый сложный способ отображения, который требует для проверки попадания сложных алгоритмов поиска. Поиск может замедлить работу кэша, но этот способ теоретически обеспечивает наилучший коэффициент попадания, так как предоставляет максимум вариантов для кэширования любого адреса памяти.
- N-направленный ассоциативный по множеству кэш (N-way set associative cache): Здесь число "N" обычно равно 2, 4, 8 и т.д. Этот компромиссный кэш разбивается на множества по "N" строк каждое и любой адрес памяти можно кэшировать в любой из этих "N" строк. При этом повышается коэффициент попаданий по сравнению с прямо отображенным кэшем и уменьшается сложность поиска, так как "N" обычно невелико. Обычно в L1-кэше используется 2- или 4-направленный ассоциативный по множеству кэш.
Политика записи
Политика записи кэша определяет, как он выполняет записи в ячейки памяти, которые в данное время находятся в кэше. Напомним, что имеются две политики записи:
- Кэш с обратной записью (write-back cache): Когда система записывает в ячейку памяти, содержащуюся в кэше, запись новой информации производится только в соответствующую строку кэша. Когда строка кэша требуется для какого-то другого адреса памяти, измененные данные "обратно записываются" (written back) в системную память. Такой кэш имеет лучшую производительность по сравнению с кэшем со сквозной записью, ускоряя продолжительные операции циклы записи в системную память.
- Кэш со сквозной записью (write-through cache): Когда система записывает в ячейку памяти, содержащуюся в кэше, запись одновременно производится в соответствующую строку кэша и саму ячейку памяти. Такое кэширование обеспечивает меньшую производительность, чем кэширование с обратной записью, но его проще реализовать и обеспечивается полная согласованность, так как содержание кэша всегда согласовано с содержанием основной памяти, чего может не быть в кэше с обратной записью.
На практике применяются обе разновидностей кэшей, но в новых РС преобладает
кэш с обратной записью.
Транзакционный (неблокирующий) кэш
Большинство кэшей могут удовлетворять одновременно только по одному запросу. Если инициируется запрос к кэшу и зарегистрирован промах, кэш должен ожидать данных из памяти и на это время он "блокируется". Неблокирующий кэш (non-blocking cache) может обрабатывать другие запросы, в процессе ожидания данных из памяти при промахе.
L2-кэши процессоров Pentium Pro и Pentium II могут управлять четырьмя
одновременными запросами. Для этого реализованы транзакционная архитектура
(transaction-based architecture) и введена специальная задняя шина
(backside bus), которая не зависит от шины основной памяти. Такую архитектуру
фирма Intel называет сдвоенной независимой шиной (Dual Independent Bus -
DIB).
Технологии передачи кэша и временная диаграмма
Одним из наиболее важных факторов, прямо влияющих на производительность L2-кэша, является технология передачи информации в процессор и из процессора. Имеются три основных типа технологии кэша на материнских платах; используемая системой технология определяется возможностями чипсета, в частности, контроллера кэша.
Под временной диаграммой (timing) понимается число тактов синхронизации,
необходимое для передачи данных в/из кэша или процессора и оно зависит от
нескольких факторов, в частности, от применяемой технологии. При рассмотрении
сложной временной диаграммы приходится учитывать различные характеристика
процессора, кэша, системной памяти, чипсета и др. Однако, в общем, чем меньше
тактов занимает передача, тем быстрее система.
Пакетизация кэша
В типичном L2-кэше каждая строка кэша состоит из 32 байтов и в передаче участвуют все эти 32 байта. Однако обычный тракт передачи в РС пятого и шестого поколения имеет ширину всего 64 бита, поэтому приходится последовательно выполнять четыре передачи. Поскольку передачи осуществляются из соседних ячеек памяти, не нужно определять адреса после указания первого, поэтому второе, третье и четвертое обращения выполняются очень быстро.
Такой способ быстрого доступа называется пакетизацией (bursting) или работой в пакетном режиме. Этот способ применяется практически во всех L2-кэшах. Временная диаграмма обычно представляется в виде "x-y-y-y". Например, в диаграмме "3-1-1-1" первое считывание занимает 3 цикла, а следующие три по одному циклу. Ясно, что чем меньше эти числа, тем лучше.
Примечание: Эта ситуация напоминает пакетные передачи
системной памяти, но они выполняются быстрее.
Асинхронный кэш
В асинхронном кэше реализована самая неэффективная временная диаграмма. Асинхронность означает, что передачи не "привязаны" к сигналам системной синхронизации. Запрос выдается в кэш и кэш реагирует, причем происходящее не зависит от того, что делает системная синхронизация (на шине памяти). Ситуация аналогична работе системной памяти FPM или EDO.
Так как асинхронный кэш не "привязан" к системной синхронизации, повышение ее
частоты может вызвать проблемы. На частоте 33 МГц может быть реализована
временная диаграмма 2-1-1-1 (что очень хорошо), но на частоте 66 МГц она
принимает вид 3-2-2-2 (что довольно плохо). Поэтому асинхронный кэш в РС с
процессорами Pentium не применяется.
Синхронный пакетный кэш
В отличие от асинхронного кэша, который работает независимо от системной синхронизации, синхронный кэш "привязан" к тактам шины памяти. В каждом такте системной синхронизации можно производить передачу в/из кэша (если он готов к этому) В результате можно поддерживать более высокую скорость передач по сравнению с асинхронным кэшем. Однако, чем быстрее работает система, тем более быстродействующими должны быть микросхемы SRAM. В противном случае могут возникать различные проблемы, например зависание.
На очень высоких скоростях даже такой кэш замедляется. Например, он может
иметь диаграмму 2-1-1-1 на частоте 66 МГц, но на более высокой частоте, например
100 МГц, она растягивается до 3-2-2-2. Синхронный пакетный кэш не получил
широкого распространения, так как лучшими характеристиками обладает
конвейерно-пакетный кэш.
Конвейерно-пакетный кэш
Конвейеризация широко применяется в процессорах для повышения производительности и в конвейерно-пакетном кэше (Pipelined Burst - PLB) она используется аналогичным образом. В PLB-кэше введены специальные схемы, которая позволяет частично одновременно выполнить четыре передачи данных в "пакете". В сущности, вторая передача начинается до завершения первой передачи.
Из-за сложности схемы первоначально требуется несколько больше времени на
настройку "конвейера". Поэтому PLB-кэш несколько медленнее синхронного пакетного
кэша при начальном считывании, требуя 3 такта синхронизации вместо 2 для
синхронного кэша. Однако параллелизм позволяет PLB-кэшу пакетировать в одном
такте синхронизации остальные 3 передачи даже при очень высокой частоте
синхронизации, например реализовать диаграмму 3-1-1-1 при скорости шины 100 МГц.
PLB-кэш стал стандартом почти для всех высококачественных материнских плат с
процессором Pentium.
Сравнение производительности различных технологий передачи данных
В следующей таблице приведена теоретическая максимальная производительность системы для различных технологий кэша в зависимости от скорости шины. Слово "теоретическая" подчеркивает достижимость этой производительности только при при поддержки скорости шины чипсетом, наличии достаточного быстрого кэша и пр. Отметим, что хотя асинхронный пакетный кэш обеспечивает лучшую производительность с частотой шины 60 и 66 МГц, он применяется реже конвейерно-пакетного кэша:
Скорость шины (МГц) |
33 |
50 |
60 |
66 |
75 |
83 |
100 |
Асинхронный кэш |
2-1-1-1 |
3-2-2-2 |
3-2-2-2 |
3-2-2-2 |
3-2-2-2 |
3-2-2-2 |
3-2-2-2 |
Синхронный пакетный кэш |
2-1-1-1 |
2-1-1-1 |
2-1-1-1 |
2-1-1-1 |
3-2-2-2 |
3-2-2-2 |
3-2-2-2 |
Конвейерно-пакетный кэш |
3-1-1-1 |
3-1-1-1 |
3-1-1-1 |
3-1-1-1 |
3-1-1-1 |
3-1-1-1 |
3-1-1-1 |
Структура и конструктивное оформление кэша
Имеется множество конструктивных оформлений системного кэша, которые
рассматриваются в данном разделе. Используемое в конкретном РС оформление
зависит от процессора, чипсета и материнской платы.
Интегрированный L2-кэш
Процессор Pentium Pro выпускался с интегрированным (встроенным) L2-кэшем. Корпус, который вставляется в материнскую плату, фактически содержит две микросхемы - сам процессор с L1-кэшем и L2-кэш емкостью 256 КБ, 512 КБ или 1 МБ. При этом L2-кэш работает не с частотой шины, а с внутренней частотой синхронизации процессора, что повышает производительность. Упрощается и настройка РС, так как все вспомогательные схемы находятся внутри корпуса.
К сожалению, при такой реализации для повышения емкости кэша приходится
заменять процессор. Эти процессоры были довольно дорогими из-за технологических
сложностей производства (весь кэш на одном большом кристалле). Кроме того,
дефекты в L2-кэше часто не обнаруживаются до полной сборки процессора, поэтому в
случае дефектного кэша приходилось выбрасывать весь процессор. По всем этим
причинам в последующих процессорах Pentium интегрированный кэш не применяется.
Кэш на дочерней плате
Начиная с процессора Pentium II, появилось новое конструктивное оформление, называемое Single Edge Contact (SEC). Интегрированный кэш процессора обеспечивал высокую производительность, но оказался слишком дорогим. Кэш на материнской плате обычных процессоров Pentium был простым и дешевым, но имел относительно низкую производительность. Корпус SEC является компромиссом, когда процессор и кэш монтируются вместе на небольшой дочерней плате (daughterboard), которая вставляется в материнскую плату. Такой прием сильно снижает стоимость производства, дефектный кэш не влечет выбрасывания процессора.
Такой кэш работает быстрее кэша на материнской плате, но медленнее интегрированного кэша, т.е. оказывается компромиссным между ними. L2-кэш с процессором Pentium II работает на половинной частоте процессора, например при частоте процессора 266 МГц частота работы кэша составляет 133 МГц, что лучше частоты шины памяти 66 МГц. L2-кэш для процессоре Pentium II является неблокирующим, как и кэш процессора Pentium Pro.
Примечание: Несмотря на схожесть архитектур процессоров
Pentium II и Pentium Pro, из-за конструктивных ограничений кэш процессора
Pentium II кэширует только первые 512 МБ системной памяти, а процессора Pentium
Pro - до 4 ГБ системной памяти.
Кэш на материнской плате
Чаще всего микросхемы кэша размещаются прямо на материнской плате. В старых
платах несколько микросхем SRAM вставлялись в сокеты, а в новых платах 1 - 4
микросхемы впаяны в материнскую плату. Если микросхемы кэша вставляются в
сокеты, можно добавить микросхемы для увеличения емкости памяти данных кэша.
Некоторые материнские платы поддерживают кэш с вмонтированными микросхемами и
модуль COASt. Чтобы использовать оба типа кэша, требуется изменить положение
перемычки на материнской плате.
Модули COASt
На некоторых материнских платах применяется конструктив кэша, называемый COASt (Cache On A Stick - буквально "кэш на палочке"). Модуль COASt представляет собой небольшую схемную плату, похожую на модуль памяти SIMM и содержащую микросхемы SRAM. Он вставляется в специальный сокет на материнской плате, часто называемый CELP (Card Edge Low Profile). Некоторые материнские платы используют для кэша только этот сокет, другие имеют только кэш на материнской плате, а третьи - используют оба типа кэша. В последнем случае используемый кэш определяется перемычкой, но некоторые материнские платы автоматически обнаруживают имеющийся модуль COASt.
Сокет CELP мог стать стандартом для разнообразных модулей COASt, но этого не случилось. Несмотря на стандартно звучащие названия, например "COASt V1.2", нельзя полагать, что любой из старых модулей COASt будет работать на плате.
Примечание: Модуль COASt часто содержит не только больше памяти
данных, но и большую тэговую память, позволяющую кэшировать больше системной
памяти.
