Накопители на жестких дисках
Когда питание РС выключается, содержание памяти теряется. Энергонезависимой (non-volatile) памятью РС является накопитель на жестких дисках (hard disk, Hard Disk Drive - HDD), на котором хранятся документы пользователя, файлы и приложения. Первый жесткий диск компания IBM выпустила в 1954 г.; этот накопитель на 50 дисках (platters) диаметром 24" мог хранить 5 МБ данных. Через 25 лет компания Seagate выпустила первый жесткий диск для РС и он имел емкость 40 МБ, а скорость передачи данных составляла 625 КБ/с. Сейчас в это трудно поверить, но в конце 80-х годов прошлого века жесткий диск 100 МБ считался просто огромным по емкости. Сейчас емкости этого накопителя недостаточно для инсталлирования одной операционной системы, не говоря о таких огромных приложениях как Microsoft Office.
Быстрое развитие РС привело программные компании к мысли о том, что размер приложений не играет роли. В результате средняя емкость жесткого диска буквально за несколько лет возросла со 100 МБ до 1.2 ГБ. В начале нового века типичный жесткий диск настольного РС имел емкость 18 ГБ, а содержал всего три диска диаметром 3.5". К счастью, по мере роста емкости накопителей стоимость их снижалась. Повышение поверхностной плотности (areal density) было главной причиной снижения удельной стоимости за 1 МБ.
Однако росла не только емкость жестких дисков - постоянно увеличивалась и их
производительность. Когда появился чипсет Triton фирмы Intel, были разработаны
интерфейсы EIDE и режим PIO 4, благодаря которым производительность жестких
дисков резко повысилась, что позволило пользователям приобретать относительно
дешевые накопители, а не дорогие накопители с интерфейсом SCSI.
Конструкция накопителя на жестких дисках

Жесткие диски имеют твердые диски (platters), состоящие из подложки и магнитного носителя. Подложка, т.е. базовый материал диска, должна быть немагнитной и ровной. Она производится из алюминиевого сплава или смеси стекла и керамики. Для хранения данных обе стороны каждого диска покрываются магнитным носителем; прежде это был магнитный оксид железа, а сейчас применяется исключительно слой тонкопленочного покрытия. Квадратный дюйм каждой поверхности диска способен хранить миллиарды битов.
Для накопителей на жестких дисках приняты два форм-фактора (form
factor) - 5.25" и 3.5", причем преобладает форм-фактор 3.5". Сейчас наметился
переход к стеклянным дискам, которые имеют лучшие тепловые характеристики и
позволяют сделать диски тоньше, чем алюминиевые. Для предотвращения загрязнения
внутренней камеры накопителя давление воздуха выравнивается с помощью
специальных фильтров. Внутренняя камера накопителя часто называется сборкой
жесткого диска (Head Disk Assembly - HDA).

Обычно 2-3 или более дисков собираются вместе и шпиндельный двигатель вращает
их со скоростью несколько тысяч оборотов в минуту. Между дисками имеется
промежуток для головки считывания-записи (read/write head),
смонтированной на конце рычага привода (actuator arm). Головка находится
очень близко к поверхности и диска и поддерживается только слоем воздуха,
который увлекается вращающимся диском; головка фактически летает, или плавает,
над поверхностью диска. В первых накопителях расстояние от головки до
поверхности диска составляло примерно 0.2 мм, а в современных накопителях оно
уменьшено до 0.07 мм и менее. Крохотная частица пыли может вызвать касание
головкой поверхности диска (так называемый крах головки - head crush),
что вызывает порчу участка носителя. В накопителях с интерфейсами IDE и SCSI
компонентом накопителя является и контроллер диска (disk controller).
Для каждой стороны каждого диска имеется головка считывания-записи; все головки смонтированы на рычагах, которые могут передвигать головки к центральной оси или к внешнему краю. Рычаги приводятся в действие приводом головок (head actuator), который имеет звуковую катушку (voice coil) - электромагнитную катушку, которая может очень быстро передвигать магнит. С помощью аналогичного механизма вибрируют диафрагмы громкоговорителей.
Когда при выключении накопителя диски прекращают вращаться, головки
опускаются на их поверхности. При замедлении вращения воздушный поток
уменьшается и головки плавно опускаются ("приземляются" - lands) на специальный
участок, называемый зоной приземления
(Landing Zone - LZ). Эта зона предназначена только для парковки головок и
никогда не содержит данных.
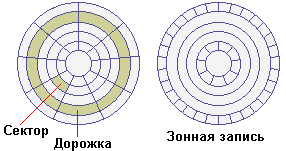
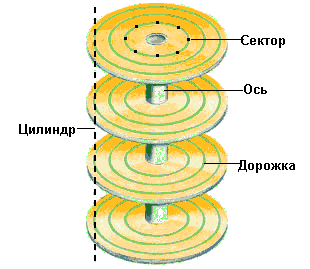
В процессе форматирования низкого уровня (Low-Level Formatting - HLL) диск разделяется на дорожки (tracks) и секторы (sectors). Дорожки представляют собой концентрические окружности на каждой стороне каждого диска. Дорожки, которые физически находятся друг над другом на всех дисках, группируются в так называемые цилиндры (cylinders), которые подразделяются на секторы, содержащие по 512 байтов. Понятие цилиндра очень важное, так как ко всей информации в цилиндре можно обратиться, не перемещая головок. Сектор является наименьшей адресуемой единицей диска. В современных накопителях применяется так называемая зонная запись (Zone-Bit Recording - ZBR), при которой внешние дорожки содержат больше секторов, чем внутренние дорожки.
Распределение отдельных секторов данных и слежение за ними в накопителе
большой емкости связано с большими служебными потерями, ухудшающими обработку
файлов. Для повышения производительности секторы данных распределяются группами,
называемыми кластерами
(clusters).
Работа накопителя
Данные записываются на магнитной поверхности диска точно так же, как на гибких дисках или цифровых лентах. По существу, поверхность считается массивом точечных позиций - доменов - и магнитная поляризация домена устанавливается в двоичные 0 или 1. Позиция каждого элемента массива не идентифицируется в "абсолютном" смысле, поэтому специальные "наводящие маркеры" помогают головке считывания-записи находить позиции на диске. Необходимость наличия этих "наводящих маркеров" объясняет, почему до использования дисков их необходимо форматировать.
При обращении к уже хранимым данным диск вращается очень быстро, поэтому любую часть его окружности можно быстро идентифицировать. Накопитель преобразует запрос считывания от РС в реальные действия. Было время, когда местонахождение нужных компьютеру данных определялось координатами цилиндр/головка/сектор, но современные накопители очень сложные для системы BIOS, поэтому они преобразуют запросы BIOS, используя собственное отображение.
| Размер раздела | Размер кластера FAT32 |
| 3 ГБ - 7 ГБ | 4 КБ |
| 8 ГБ - 16 ГБ | 8 КБ |
| 16 ГБ - 32 ГБ | 16 КБ |
| Больше 32 ГБ | 32 КБ |
Напомним, что для повышения производительности секторы данных распределяются группами, называемыми кластерами (clusters). Число секторов в кластере зависит от размера кластера, который, в свою, очередь, зависит от размера раздела (partition). Таблица слева показывает возможности, поддерживаемые файловой системой Windows 98 FAT32.
Когда компьютеру требуется считать данные, операционная система определяет,
где данные находятся на диске. Для этого она вначале считывает таблицу
размещения файлов (File Allocation Table - FAT) из начала раздела. Таблица
сообщает операционной системе, в каком секторе на какой дорожке искать данные.
Имея такую информацию, головка может затем считать запрошенные данные.
Контроллер диска управляет серво-приводом (servo-motor) накопителя и
преобразует слабые сигналы от головки в цифровые данные для процессора.

Довольно часто следующий считываемый набор данных расположен на диске последовательно. Поэтому накопители на жестких дисках содержат буферный кэш емкостью от 64 КБ до 1 МБ, в котором сохраняется большая часть информации из цилиндра на тот случай, если она потребуется. Наличие дискового кэша значительно повышает производительность и время обращения. Накопителю также требуется серво-информация, которая следит за обновляющимся местонахождением головок. Эта информация может храниться на отдельной поверхности одного из дисков или чередоваться с фактическими данными на всех дисках. Выделять отдельную поверхность дороже, но при этом улучшается время обращения, так как головкам не нужно расходовать время на поиск серво-информации.
Из-за изменений температуры может нарушаться выравнивание дисков с данными и серво-информацией. Для предотвращения этого накопитель постоянно контролирует себя в процессе так называемой тепловой рекалибровки (thermal recalibration). При воспроизведении мультимедиа рекалибровка может вызывать внезапные паузы, что приводит к получению искаженного звука и "выпадению" видеокадров. Когда серво-информация хранится на дисках данных, тепловая рекалибровка не требуется. Поэтому в большинстве накопителей серво-информация встроена в данные.
Самыми распространенными интерфейсами подключения накопителя к РС сейчас
являются интерфейсы EIDE и SCSI
Производительность накопителя
Производительность жесткого диска сильно влияет на общую производительность системы, потому что медленный накопитель может "тормозить" быстрый процессор так, как никакой другой компонент. Эффективная производительность жесткого диска определяется несколькими факторами.
Одним из них является скорость вращения дисков. Число оборотов в минуту прямо влияет на запаздывание (latency) и скорость передачи данных. Чем быстрее вращается диск, тем больше данных проходят под головками, которые считывают данные; чем меньше скорость вращения, тем больше механические запаздывания. Жесткие диски вращаются с постоянной скоростью и до недавнего времени большинство EIDE-накопителей имело скорость вращения 5400 об/мин, а многие SCSI-накопители имели скорость вращения 7200 об/мин. В 1997 г. компания Seagate выпустила накопитель UltraSCSI Cheetah со скоростью вращения 10 033 об/мин, а в середине 1998 г. первой объявила EIDE-накопитель со скоростью вращения 7200 об/мин.
В 1999 г. компания Hitachi превысила барьер 10 000 об/мин, выпустив
SCSI-накопитель Pegasus II, который имел скорость вращения 12 000 об/мин, что
соответствует среднему запаздыванию 2.49 мс. Специалисты компании Hitachi нашли
оригинальное решение удаления избыточного тепла, выделяемого при такой высокой
скорости вращения. В стандартном накопителе 3.5" физические диски имеют диаметр
3". Однако в накопителе Pegasus II диаметр дисков уменьшен до 2.5". Меньшие
диски вызывают меньшее трение о воздух, что уменьшает выделяемое тепло. Кроме
того, шасси накопителя служит большим теплоотводом, что также помогает
рассеивать тепло. Конечно, для увеличения емкости пришлось увеличить число
дисков, что привело к увеличению высоты накопителя. Обычно этот накопитель
применяется в серверах и высококачественных рабочих станциях.
Запаздывание
Механические запаздывания измеряются в миллисекундах и включают в себя время
поиска
(seek time) и вращательное запаздывание (rotational latency). Время
поиска определяет временной интервал, который необходим головке
считывания-записи, чтобы найти физическое местонахождение нужных данных на
диске. Запаздывание - это среднее время поворота нужного сектора в позицию под
головкой по окончании поиска. Среднее время запаздывания легко вычисляется по
известной скорости вращения - оно равно половине времени оборота. Среднее
время обращения
(access time) накопителя представляет собой интервал между моментом запроса
данных системой и моментом доступности данных от накопителя. Время обращения
включает в себя фактическое время поиска, вращательное запаздывание и служебные
потери времени, связанные с обработкой команды.
Скорость передачи
Под скоростью передачи диска (disk transfer rate), которую иногда называют скоростью носителя (media rate), понимается скорость, с которой данные передаются на диск или с диска (физического диска); эта скорость зависит от частоты записи. Обычно она описывается в мегабайтах в секунду МБ/с. В современных накопителях скорость передачи диска повышается при переходе с внутренних цилиндров накопителя к внешним. Важнейшими параметрами носителя, относящимися к плотности на диск, являются число дорожек на дюйм (Tracks Per Inch - TPI) и число битов на дюйм (Bits Per Inch - BPI).
Под скоростью передачи хоста (host transfer rate) понимается скорость, с которой хост-компьютер может передавать данные по интерфейсу IDE/EIDE или SCSI в процессор РС. Обычно эту скорость называют скоростью передачи данных (Data Transfer Rate - DTR), а это может вызвать некоторую путаницу. Некоторые поставщики указывают внутреннюю скорость передачи, т.е. скорость, с которой накопитель передает данные с головки в свои внутренние буферы. Другие приводят пакетную (burst) скорость передачи данных, т.е. максимальную скорость передачи, которую накопитель может обеспечить при идеальных обстоятельствах и в течение короткого времени. На практике наиболее важна внешняя скорость передачи данных, т.е. насколько быстро накопитель фактически передает данные в основную память РС.
Современные высокопроизводительные накопители обеспечивают среднее
запаздывание менее 3 мс, среднее время поиска ниже 7 мс и максимальную скорость
передачи, приближающуюся к 20 МБ/с.
Головки считывания-записи
С момента появления жестких дисков в 1955 г. индустрия магнитной записи постоянно и очень быстро повышала производительность и емкость накопителей на жестких дисках для удовлетворения "ненасытного" требования компьютерной индустрии иметь все более емкую и лучшую память. Поверхностная плотность (areal density) жестких дисков увеличивалась примерно на 27% в год (в 90-е годы прошлого века прирост составил 60% в год). В результате к концу ХХ века поверхностная плотность достигла 600-700 Мб/кв. дюйм.
В течение продолжительного времени технология головок считывания-записи
опиралась на напряжение индукции, которое наводится, когда постоянный магнит
(диск) движется под магнитной катушкой (головкой). Первые головки производились
намоткой обмотки на пластинчатый железный сердечник. Требования массового
производства накопителей и повышения поверхностной плотности стимулировали
совершенствование индуктивных головок считывания-записи.

Кульминацией этого процесса стали тонкопленочные индуктивные (Thin-Film Inductive - TFI) головки считывания-записи, которые стало возможным производить в массовом количестве, применяя технологические процессы полупроводниковой промышленности. На рисунке показана пара TFI-головок в сильно увеличенном масштабе. TFI-головки стали применяться в коммерческих накопителях только в конце 70-х годов прошлого века, хотя сама технология была открыта еще в 60-е годы. Такие головки получили исключительно широкое применение до середины 90-х годов прошлого века. К этому времени оказалось невозможным повышать поверхностную плотность обычным способом - увеличивая чувствительность головки к изменениям магнитного потока за счет добавления числа витков в обмотке головки. Большое число витков увеличивало индуктивность обмотки до такого уровня, когда она ограничивалась способность записывать данные.
Дальнейшим крупным шагом на пути повышения емкости жестких дисков за счет
совершенствования головок считывания-записи стало использование явления,
открытого лордом Кельвином в 1857 г. - сопротивление ферромагнитного сплава
изменяется в зависимости от приложенного магнитного поля. Это явление называется
эффектом анизотропной магнитной резистивности (Anisotropic
MagnetoResistance - AMR).
MR-технология
В 1991 г. исследования специалистов компании IBM по эффекту AMR привели к
созданию магнито-резистивных головок (MR-головок), которые позволили резко
повысить поверхностную плотность жестких дисков. В таких головках преодолено
основное ограничение TFI-головок - одна и та же головка должна попеременно
выполнять конфликтующие задачи записи данных на диск и считывания ранее
записанных данных. В MR-головке запись и считывание производятся отдельными
элементами, каждый из которых можно оптимизировать на выполнение конкретной
функции.

В MR-головке записывающий элемент представляет собой обычную TFI-головку, а считывающий элемент представляет собой тонкую полоску магнитного материала. Сопротивление полоски изменяется при наличии магнитного поля, формируя сильный сигнал, допускающий усиление без помех и обеспечивающий значительное повышение поверхностной плотности. Когда диск проходит под считывающим элементом, схемы накопителя воспринимают и декодируют изменения электрического сопротивления, вызванные реверсированием магнитной полярности. Большая чувствительность считывающего MR-элемента обеспечивает больший выходной сигнал на единицу ширины дорожки на поверхности диска. MR-технология позволяет не только разместить на дисках больше данных, но и позволяет использовать в схемах считывания меньшее число компонентов.
Считывающий MR-элемент меньше записывающего TFI-элемента. Фактически считывающий MR-элемент можно даже сделать меньше дорожки данных, так что при небольшом нарушении выравнивания MR-элемент все же остается над дорожкой и способен считывать записанные на дорожке данные. Небольшой размер элемента предотвращает захват паразитных сигналов вне дорожки, что обеспечивает хорошее отношение сигнал-шум.
Производство MR-головок ставит определенные трудности. Тонкопленочные элементы очень чувствительны к электростатическим разрядам, поэтому необходимо предпринимать специальные предосторожности и средства защиты. Головки также чувствительны к загрязнению, а их материал подвержен воздействию коррозии.
Различные усовершенствования MR-технологии позволили получить поверхностную
плотность примерно в четыре раза больше по сравнению с TFI-головками при большей
высоте полета - минимум 3 Гб/кв. дюйм. Ограничения по чувствительности этой
технологии объясняются тем фактом, что степень изменения сопротивления магнитной
пленки MR-головки сама ограничена. Прошло совсем немного времени и на базе этой
технологии была разработана технология гигантской магнито-резистивности
(Giant Magneto-Resistive - GMR).
GMR-технология
Слово "гигантская" в названии GMR-головке не означает "гигантского" размера головок, так как фактически они меньше обычных MR-головок. Этим словом подчеркивается гигантский магниторезистивный эффект (giant magnetoresistive effect), открытый в конце 80-х годов прошлого века. Работая с сильными магнитными полями и тонкослойными магнитными материалами, ученый открыли большие изменения сопротивления при воздействии на материалы магнитных полей. Это открытие послужило основой новой технологии головок считывания-записи.
Технология GMR-головок опирается на технологии TFI-головок и MR-головок и
позволяет получить головки, которые обладают большей чувствительностью к
изменению намагниченности диска. Эта технология обеспечивает достижение огромной
плотности и скорости передачи данных, объединяя достижения квантовой механики и
сверхточного производства. Ожидается, что в 2004 г. будет получена поверхностная
плотность в 40 Гб/кв. дюйм.
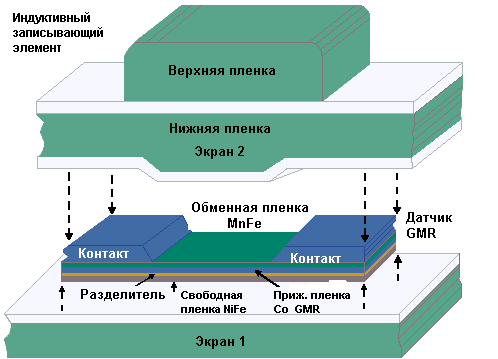
В MR-материале, например сплаве никеля и железа, свободные электроны движутся менее свободно (из-за более частых столкновений атомов), когда направление движения параллельно магнитной ориентации в материале. Собственно, в этом и заключается MR-эффект. Когда электроны движутся менее свободно, сопротивление (резистивность) оказывается больше. GMR-датчики используют квантовую природу электронов, имеющих два направления спинов - вверх и вниз. Проводящие электроны с направлением спина параллельным магнитной ориентации пленки движутся свободнее, обеспечивая малое электрическое сопротивление. Наоборот, движение электронов с противоположным направлением спина затрудняется из-за частых столкновений с атомами в пленке, что дает большее сопротивление. Компания IBM разработала структуры, идентифицируемые как спиновые клапаны (spin valves), к которым прижимается одна магнитная пленка. Это означает, что ее магнитная ориентация фиксирована. Вторая магнитная пленка, называемая пленкой датчика (sensor film) имеет свободную переменную магнитную ориентацию. Обе магнитные пленки очень тонкие и находятся очень близко друг к другу, позволяя электронам с любым направлением спина переходить между этими пленками. Изменения магнитного поля, производимые диском, вызывают ротацию магнитной ориентации пленки датчика, которая, в свою очередь, увеличивает или уменьшает сопротивление всей структуры. Малое сопротивление получается, когда пленка датчика и прижатая пленка магнитно ориентированы в одном и том же направлении, так как электроны с параллельным направлением спина свободно движутся в обеих пленках.
Большее сопротивление образуется, когда магнитные ориентации пленки датчика и прижатой пленки противоположны друг другу, так как движение электронов с любым направлением спина затрудняется одной их этих магнитных пленок. GMR-датчики могут работать со значительно большей поверхностной плотностью по сравнению с MR-датчиками, так как процентное изменение сопротивления больше, что делает их более чувствительными к магнитным полям с диска.
Современные жесткие диски с GMR-головками имеют поверхностную плотность 4.1
Гб/кв. дюйм, а экспериментальные головки обеспечивают достижение плотности 10
Гб/кв. дюйм. Такие головки имеют толщину датчиков 0.04 мкм, но компания IBM
надеется довести толщину до 0.02 мкм, что позволит получить поверхностную
плотность в 40 Гб/кв. дюйм. При повышении плотности можно уменьшить физические
размеры накопителей и снизить потребляемую мощность, а также повысить скорость
передачи данных. Уменьшение размеров дисков и снижение массы головок позволяет
повысить скорость вращения, минимизируя механические запаздывания накопителя.
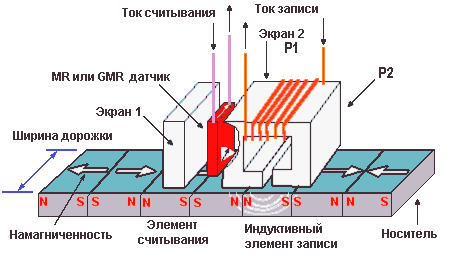
Компания IBM начала производство объединенных GMR-головок считывания-записи с
1992 г. Они состоят из тонкопленочного записывающего элемента и считывающего
элемента. Считывающий элемент имеет MR- или GMR-датчик, находящийся между двумя
магнитными экранами. Магнитные экраны значительно уменьшают паразитные магнитные
поля с диска; датчик фактически воспринимает магнитное поле только записанного
бита, подлежащего считыванию. В объединенной головке второй магнитный экран
действует также как один полюс индуктивной головки записи. Преимущество
отдельных считывающего и записывающего элементов заключается в том, что оба
элемента можно оптимизировать по отдельности. Объединенная головка имеет и
дополнительные преимущества. Такую головку дешевле производить, так как для
этого требуется меньше технологических этапов, а расстояние между считывающим и
записывающим элементами можно сделать меньше.
Кодирование и декодирование данных на жестком диске
Цифровая информация представляет собой поток единиц и нулей. Информация на жестких дисках хранится в форме магнитных импульсов (magnetic pulses). Следовательно, для сохранения информации от РС на жестком диске ее необходимо преобразовать в "магнитную" информацию. При считывании с диска ее необходимо преобразовать в цифровую информацию. Эти преобразования выполняют встроенные в накопитель контроллер и схемы восприятия и усиления, интерпретирующие сигналы, считываемые собственно с дисков.
Магнитная информация на диске представлена потоком крошеных магнитных полей. Магнит имеет два полюса - северный (north) и южный (south) - и магнитный поток (flux) направлен от северного полюса к южному. Информация сохраняется на диске с помощью кодирования (encoding) ее в последовательность магнитных полей. Для этого магнитные поля располагаются в одном из двух направлений полярности - либо так, что северный полюс появляется раньше южного при вращении диска (N-S), либо так, что южный полюс появляется раньше северного(S-N). Несмотря на то, что в принципе несложно соотнести 0 и 1 цифровой информации магнитным полям N-S и S-N, на практике ситуация сложнее: прямое однозначное соответствие невозможно и приходится использовать специальные приемы для того, чтобы данные записывались и считывались правильно.
Технические требования к кодированию и декодированию
Можно подумать, что при наличии двух магнитных полярностей N-S и S-N их можно
использовать для представления двоичных 1 и 0, соответственно, обеспечивая
простое кодирование цифровой информации. Но, оказывается, на практике
осуществить это совсем непросто. Имеются две основных причины, не допускающие
простого однозначного кодирования:
- Поля и переходы: Головки считывания-записи не могут измерять фактическую полярность магнитных полей, а воспринимают переходы потока (flux reversals), которые возникают, когда диск под головкой перемещается с участка с полярностью N-S на участок с полярностью S-N и наоборот. Причина восприятия головкой переходов потока, а не абсолютной полярности, объясняется тем, что переходы проще измерить. Когда под головкой проходит переход, в головке формируется небольшой импульс напряжения, который воспринимается схемой обнаружения. При повышении плотности данных на диске сила каждого отдельного поля уменьшается, что затрудняет обнаружение отдельных импульсов. Таким образом, кодирование данных необходимо производить на основе переходов потока, а не содержания отдельных полей.
- Синхронизация: При кодировании данных требуется некоторый способ указания того, где заканчивается один бит и начинается другой. Даже если бы было можно использовать одну полярность для представления 1, а другую для представления 0, что произошло бы при необходимости закодировать на диске поток из тысячи последовательных нулей? Было бы очень трудно указать, где заканчивается бит, например, 787-й и начинается бит 788-й.
Следовательно, для кодирования данных на жестком диске таким образом, чтобы
их можно было надежно считать, необходимо учитывать приведенные особенности.
Требуется кодировать данные, привлекая переходы потока, а не абсолютные поля.
Необходимо свести число последовательных полей одинаковой полярности к минимуму.
Наконец, для слежения для размещением отдельных битов в кодирующую
последовательность необходимо ввести сигналы синхронизации.
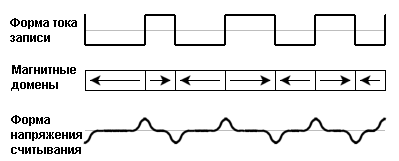
На рисунке показано идеализированное представление записи данных на диск и последующего считывания. Верхний сигнал показывает, как данные записываются на диск. В середине показано, как намагничивается носитель на домены с различным направлением в зависимости от полярности тока записи. Внизу показаны, как переходы потока на диске преобразуются в положительные и отрицательные импульсы напряжения. Отметим, что рисунок иллюстративный и не подразумевает никакого способа кодирования.
В дополнение к рассмотренным требованиям необходимо учитывать еще одно ограничение: пределы намагниченности самого носителя. Каждый линейный дюйм на дорожке может хранить только определенное число переходов. Оно ограничивает поверхностную плотность данных. Так как некоторые переходы потока приходится использовать для синхронизации, они недоступны для данных. Поэтому главная цель способов кодирования данных состоит в уменьшении числа переходов, используемых для синхронизации.
Первые способы кодирования были относительно простыми и в них множество
переходов потока использовалось для синхронизации. Со временем были разработаны
более совершенные способы кодирования, в которых для кодирования одного и того
же объема информации требовалось меньше переходов потока. Они позволяют
поместить больше данных в одно и то же пространство. Важно понимать, что
означает плотность в данном контексте. Аппаратные технологии направлены на то,
чтобы сохранить больше битов на одном и том же участке путем увеличения числа
переходов потока на линейный дюйм дорожки. Способы кодирования направлены на
хранение большего числа битов путем кодирования больше битов (в среднем) на
переход потока.
Частотная модуляция
Первым распространенным способом кодирования для записи цифровых данных на магнитных носителях была частотная модуляция (Frequency Modulation - FM). В этом простом способе двоичная 1 записывалась как два последовательных перехода потока, а двоичный 0 - переходом потока с с последующим отсутствием перехода потока. Более подробно способ описывается таким образом: в начале каждого бита формируется переход потока для представления синхронизации, а затем дополнительный переход добавляется в середине каждого бита для двоичной 1, а для двоичного 0 дополнительный переход опускается.
Битовый набор |
Кодирующий набор |
Переходов |
0 |
RN |
1 |
1 |
RR |
2 |
Взвешенное среднее |
1.5 |
|
В таблице слева показано FM-кодирование (здесь "R" представляет переход потока, а "N" - отсутствие перехода потока). Среднее число переходов потока на бит в случайном потоке битов равно 1.5. Наилучший случай (все нули) дает 1, а наихудший (все единицы) - дает 2.
Название частотная модуляция объясняется тем, что число переходов для единиц
удваивается по сравнению с числом переходов для нулей. Это видно при
рассмотрении записываемого потока данных из нулей и единиц. Байт из нулей
кодируется в виде "RNRNRNRNRNRNRNRN", а байт из единиц - в виде
"RRRRRRRRRRRRRRRR". Здесь наглядно видно, что единицы имеют удвоенную частоту
переходов по сравнению с нулями, чем и объясняется название частотная модуляция,
т.е. изменение частоты в зависимости от данных.

FM-кодирование байта "10001111" показано на рисунке слева. Каждая битовая
ячейка показана прямоугольником и розовая прямая показывает позицию, где при
необходимости помещается переход в середине ячейки. Недостаток FM-кодирования
очевиден: на каждый бит данных требуется переход потока для синхронизации.
Поэтому сейчас этот способ не применяется.
Модифицированная частотная модуляция
Битовый набор |
Кодирующий набор |
Переходов |
0 (с предшествующим 0) |
RN |
1 |
0 (с предшествующей 1) |
NN |
0 |
1 |
NR |
1 |
Взвешенное среднее |
0.75 |
|
Улучшением простейшего способа FM-кодирования стала модифицированная частотная модуляция (Modified Frequency Modulation - MFM), в которой значительно уменьшается число переходов потока для синхронизации. Вместо введения перехода синхронизации в начале каждого бита такой переход вводится только между последовательными нулями. Когда записывается двоичная 1, уже имеется переход (в середине битотовой ячейки), поэтому дополнительный переход синхронизации не требуется. Когда двоичному 0 предшествует 1, то переход недавно был и еще один не нужен. Только длинные последовательности нулей необходимо "разбивать" введением переходов синхронизации.
Приведенная таблица иллюстрирует MFM-кодирование ("R" обозначает переход
потока, а "N" - отсутствие перехода). Среднее число переходов потока в случайном
битовом потоке равно 0.75. В наилучшем случае ("101010...") получается 0.25, а в
наихудшем случае (все единицы или все нули) получается 1.
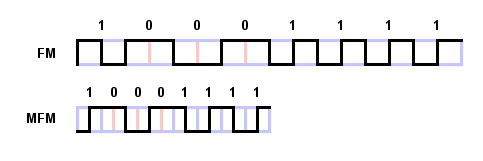
Поскольку среднее число переходов потока на бит оказывается в два раза меньше, чем в FM-кодировании, частоту синхронизации можно удвоить, что позволяет примерно удвоить емкость по сравнению с FM-кодированием при одной и той же поверхностной плотности. Конечно, при этом усложняются схемы кодирования и декодирования из-за усложнения алгоритма. Пример MFM-кодирования байта "10001111" показан на рисунке. Здесь наглядно видно, что при MFM-кодировании в одно и то же пространство помещается вдвое больше данных, используя в два раза меньше переходов потока на бит данных.
MFM-кодирование применялось в первых жестких дисках и сейчас ради обратной
совместимости сохранилось в гибких дисках. Однако для современных жестких дисков
используется более эффективное RLL-кодирование.
Кодирование с ограниченной длиной отрезка
Более сложное кодирование с ограниченной длиной отрезка (Run Length Limited - RLL) фактически является "семейством" способов кодирования. RLL-кодирование определяют два основных параметра, при изменении которых получается "семейство" способов.
FM-кодирование имеет простое однозначное соответствие между кодируемым битом и переходом потока. Здесь нужно знать только значение текущего бита. MFM-кодирование улучшает эффективность кодирования по сравнению с FM-кодированием, более "интеллектуально" управляя тем, где добавлять переходы синхронизации в поток данных; это достигается учетом не только текущего бита, но и одного бита перед ним. Вот почему появляются разные шаблоны перехода потока для 0 с предшествующим 0 и для 0 с предшествующей 1. Такое "заглядывание назад" позволяет улучшить эффективность, позволяя контроллеру анализировать больше данных, решая, когда добавлять переходы синхронизации.
RLL-кодирование еще больше развивает этот способ. Он учитывает группы из нескольких битов вместо кодирования по одному биту. Идея заключается в том, чтобы смешать переходы синхронизации и данных для получения более плотной упаковки закодированных данных с целью улучшения эффективности. Двумя параметрами, определяющими RLL-кодирование, являются длина отрезка (run length) и предел отрезка (run limit), что и объясняет название способа. Слово отрезок (run) относится к последовательности пустых мест (промежутков) в выходном потоке данных без переходов потока. Длина отрезка (run length) представляет собой минимальный промежуток между переходами потока, а предел отрезка (run limit) - максимальный промежуток между ними. Как показано ранее, временной интервал между переходами не может быть слишком большим, так как в противном случае головка считывания может выйти из синхронизма и не сможет разобраться с размещением битов на дорожке.
Битовый набор |
Кодирующий набор |
Переходов |
11 |
RNNN |
1/2 |
10 |
NRNN |
1/2 |
011 |
NNRNNN |
1/3 |
010 |
RNNRNN |
2/3 |
000 |
NNNRNN |
1/3 |
0010 |
NNRNNRNN |
2/4 |
0011 |
NNNNRNNN |
1/4 |
Взвешенное среднее |
0.4635 |
|
Конкретный вариант RLL-кодирования, используемый в накопителе, обозначается как "RLL (X,Y)" или "X,Y RLL", где X есть длина отрезка, а Y - предел отрезка. Наиболее часто в накопителях применяются варианты "RLL (1,7)" и "RLL (2,7)". Рассмотрим распределение потенциальных переходов потока в закодированном магнитном потоке. В варианте "2,7" получается, что наименьшее число "промежутков" между переходами потока равно 2, а наибольшее число равно 7. Для получения такого кодирования используется набор шаблонов для представления битовых последовательностей, как показано в таблице слева ("R" - переход, "N" - отсутствие перехода).
Контроллер использует эти шаблоны, разбирая кодируемый битовый поток и
соотнося поток в соответствии с встреченными битовыми наборами. Например, при
записи байта "10001111" (8Fh) получается такое соотнесение "10-0011-11", которое
закодируется как "NRNN-NNNNRNNN-RNNN". Отметим, что поскольку каждый шаблон
заканчивается "NN", минимальное расстояние между переходами равно двум.
Максимальное расстояние получается при последовательных наборах "0011", что дает
"NNNNRNNN-NNNNRNNN", т.е. семь "не переходов" между переходами, что и объясняет
вариант RLL (2,7).
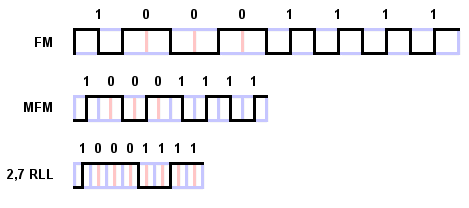
Сравнение приведенной таблицы с соответствующими таблицами для FM- и
MFM-кодирования приводит к нескольким выводам. Наиболее очевидным из них
является усложнение: используются семь разных шаблонов и для кодирования
одновременно приходится учитывать до четырех битов. Среднее число переходов на
бит для произвольного потока равно 0.4635, или примерно 0.50. Оно составляет
треть от среднего числа в FM-кодировании и примерно две трети от среднего числа
в MFM-кодировании. Например, для байта "10001111" RLL-кодирование требует
три "R"; MFM-кодирование требует семь и FM-кодирование требует 13 переходов.
Максимальное правдоподобие частичного отклика
Стандартные схемы считывания работают путем обнаружения переходов потока и
интерпретирования их в соответствии с используемым способом кодирования. Сигнал
данных считывается головкой, усиливается и подается в контроллер. Контроллер
преобразует сигнал в цифровую информацию, непрерывно анализируя сигнал,
синхронизируя его с внутренним генератором синхронизации и фиксируя небольшие
импульсы напряжения, которые представляют собой переходы потока. Такой
традиционный способ считывания и интерпретации дисковых данных называется
детектированием пиков
(peak detection).
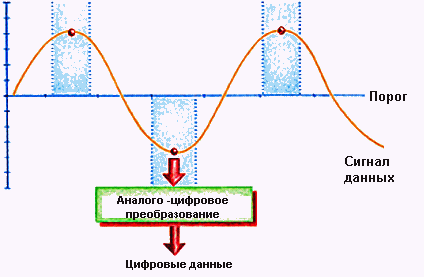
На рисунке наглядно показано аналоговое детектирование пиков. Схема сканирует считываемые с диска данные и фиксирует положительные и отрицательные импульсы, представляющие собой переходы потока на поверхности диска.
Этот способ действует прекрасно, если пики достаточно велики для выделения их из шумов. По мере повышения плотности данных переходы потока оказываются ближе друг к другу и сигнал анализировать труднее, так как пики сближаются и начинают интерферировать друг с другом. В результате при считывании с диска могут возникнуть ошибки. На практике это означает, что максимальную поверхностную плотность на диске приходится снижать, чтобы интерференции не было. Чтобы все-таки увеличить плотность, магнитные поля приходится делать слабее. При этом уменьшается интерференция, но затрудняется детектирование пиков. В некоторой точке схеме становится очень трудно определить, где имеются переходы потока.
Чтобы разрешить это противоречие, был разработана новая технология, которая
по-другому решает проблему интерпретации данных. Эта технология, названная
максимальным правдоподобием частичного отклика (Partial Response, Maximum
Likelihood - PRML), изменила весь способ считывания сигнала с поверхности диска
и его интерпретации. Вместо попытки различать отдельные пики для нахождения
переходов потока, контроллер с PRML-технологией использует сложные алгоритмы
дискретизации, обработки и обнаружения сигнала для оперирования аналоговым
потоком данных с диска (это "partial response"), а затем определяет, какую
наиболее вероятную последовательность битов представляет сигнал (это "maximum
likelihood").
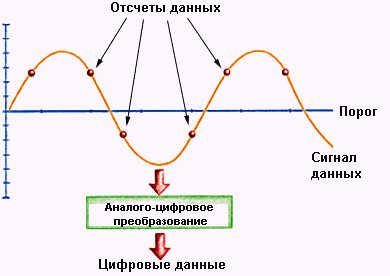
Общее представление о PRML дает приведенный рисунок. Поток данных дискретизируется и анализируется с привлечением методов обработки цифровых сигналов. Несмотря на то, что PRML кажется странным (и ненадежным) способом считывания данных с жесткого диска, фактически он очень надежен и фактически PRML (и его улучшенный вариант EPRML) стал стандартом для декодирования данных. Он позволяет увеличить поверхностную плотность примерно на 30-40% по сравнению с традиционным способом детектирования пиков.
Усовершенствованный метод PRML (Extended PRML - EPRML) обеспечивает некоторое
повышение производительности по сравнению с базовым PRML. EPRML-устройства
по-прежнему анализируют аналоговый поток данных от головки считывания-записи для
определения правильной последовательности данных. В них применяются более
совершенные алгоритмы и лучшие схемы обработки сигналов, позволяющие эффективнее
и точнее интерпретировать поступающую с диска информацию. Главное достоинство
EPRML состоит в повышении поверхностной плотности (точнее, линейной составляющей
поверхностной плотности) на 25%-70% по сравнению с обычным PRML. EPRML
применяется практически во всех новых накопителях на жестких дисках.
Форм-факторы жестких дисков
Большинство жестких дисков рассчитано на установку внутри корпуса РС. Стандарт, определяющий размеры и форму накопителя, называется форм-фактором (form factor) и относится, большей частью, к внешним размерам накопителей. Главная причина стандартизации форм-факторов объясняется объясняется необходимостью совместимости. Наличие общепринятых соглашений о стандартных формах и размерах накопителей, а также, конечно, об интерфейсах дисковых накопителей, позволяет производителям РС приобретать жесткие диски любой компании и без проблем устанавливать их в компьютеры.
За время эволюции РС разработано совсем немного форм-факторов жестких дисков.
Поскольку изменение стандарта на форм-фактор требует согласования с
производителями других компонентов РС, например системного корпуса, стандартные
размеры в промышленности изменяются очень редко и только при наличии веских
причин. Например, популярность портативных РС заставила разработать жесткие
диски меньших размеров для экономии пространства и потребляемой мощности.

Обычно форм-факторы описываются одной численной характеристикой. Например, самыми распространенными сейчас являются форм-факторы "3.5 дюйма" и "2.5 дюйма". Эти числа относятся к ширине накопителя, но оказываются несколько запутанными. Они выбраны по историческим причинам и обычно соотносились либо с диаметром собственно дисков, либо с шириной корпусов накопителей. Конечно, единственное число не может представлять оба эти размера, а иногда оно не представляет ни один из них. Например, накопители 3.5" обычно имеют ширину 4", а диаметр их дисков составляет 3.74". В этом случае форм-фактор 3.5" объясняется тем, что эти накопители помещались в отсек накопителя на гибком диске 3.5". На фотографии показаны пять наиболее популярных форм-факторов (слева по часовой стрелке): 5.25", 3.5", 2.5", PC Card и CompactFlash.
Далее рассмотрены основные форм-факторы внутренних дисковых накопителей РС. В
дополнение к стандартным форм-факторам кратко упомянуты внешние накопители и
сменные "лотки", которые можно считать "гибридом" внутренних и внешних
накопителей.
Форм-фактор 5.25"
Этот форм-фактор является старейшим в мире РС - он применялся для первых жестких дисков в компьютере IBM PC/XT и в последующих моделях, но сейчас устарел. Основой его послужил отсек для накопителей на гибком диске 5.25", которые в настоящее время также устарели. Однако отсеки 5.25" все же применятся в современных РС для накопителей CD-ROM и DVD, а не для жестких дисков. Форм-фактор 5.25" был вытеснен форм-фактором 3.5" по двум основным причинам: во-первых, накопители 5.25" были слишком большими и занимали много места и, во-вторых, накопители 3.5" имеют лучшую производительность. Накопители 5.25" применялись до середины 90-х годов прошлого века в серверах, где важнейшим параметром была высокая емкость, но в массовых РС они исчезли практически в начале 90-х годов.
В накопителях 5.25" обычно применялись диск диаметром 5.12", накопители имели
ширину 5.75" и длину (глубину) 8.0". Многие годы выпускались накопители только с
двумя значениями высоты: полной высоты (full-height) 3.25" и половинной высоты
(half-height) 1.63". В середине 90-х годов компания Quantum выпустила серию
накопителей Bigfoot с высотой 1" и менее.
Форм-фактор 3.5"
Этот форм-фактор уже примерно десять лет считается стандартом в мире РС. Накопители 3.5" применяются сейчас практически во всех настольных РС и даже в серверах. Только в портативных РС его вытеснили форм-фактор 2.5" и меньшие форм-факторы.
Название 3.5" этого форм-фактора объясняется тем, что накопители с таким форм-фактором были рассчитаны на отсек накопителя на гибком диске 3.5". Традиционно накопители с форм-фактором 3.5" имеют ширину 4.0" и глубину 5.75", а диаметр собственно дисков составляет 3.74". В последнее время выпущены накопители с форм-фактором 3.5", диаметр дисков которых значительно меньше 3.74". Например, в накопителях со скоростью вращения 10 000 об/мин диаметр дисков составляет 3.0", а в новых накопителях со скоростью вращения 15 000 об/мин диаметр дисков равен всего 2.5". Стандартный форм-фактор 3.5" сохранен в этих накопителях ради совместимости.
Стандартной высотой накопителей 3.5" для массовых РС стала высота 1.0" и такие накопители часто называются плоскими (slimline или low-profile). Однако в серверах, где требуются диски большой емкости применяются накопители 3.5" половинной высоты (half-height) 1.63"; заметим, что накопители 3.5" полной высоты 3.35" никогда не выпускались.
По-видимому, форм-фактор 3.5" еще долгие годы останется промышленным
стандартом для РС. Объясняется это огромным числом компьютеров, в которых
установлены такие накопители, и отсутствием веских причин изменять этот
форм-фактор для типичных настольных РС.
Форм-фактор 2.5"
Накопители 2.5" сейчас стали стандартными для портативных компьютеров, рынок которых постоянно расширяется. Несмотря на то, что раньше в портативных компьютерах применялись накопители 3.5", их быстро заменили накопители 2.5", которые обладают следующими достоинствами:
- Уменьшенные размеры: Меньшие накопители занимают меньше места и позволяют уменьшить размеры самих компьютеров. Вполне возможен переход к накопителям с меньшими форм-факторами.
- Сниженная потребляемая мощность: Меньшие накопители потребляют меньшую мощность, что очень важно для компьютеров с батарейным питанием.
- Улучшенная прочность: В меньших накопителях применяются диски с меньшим диаметром, которые менее подвержены выходу из строя в результате ударов, что имеет важное значение для переносимых компьютеров.

На фотографии слева показан типичный жесткий диск емкостью 8.6 ГБ для ноутбуков. Обратите внимание на один разъем, с помощью которого накопитель подключается к РС в отсеке накопителя, что позволяет при необходимости легко заменить накопитель.
В отличие от ранее рассмотренных форм-факторов в накопителях с форм-фактором
2.5" действительно применятся диски диаметром 2.5". Ширина накопителя составляет
2.75", а глубина 3.94". Первоначально эти накопители выпускались с единственной
высотой 0.75" (или 19 мм), но в последующем были выпущены накопители с другими
размерами по высоте (17 мм, 12.5 мм и даже 9.5 мм). Обычно высота накопителей
дается в метрической системе, а особенных названий для классификации по высоте
нет. Фактически форм-фактор 2.5" считается стандартом для портативных
компьютеров и таких промышленных применений, где требуются накопители небольших
размеров и повышенной стойкости к ударам и вибрации.
Форм-фактор PC Card (PCMCIA)
Одним из наиболее популярных интерфейсов в мире портативных РС является PC Card, иногда называемый PCMCIA (Personal Computer Memory Card International Association - http://www.pcmcia.org/). Этот интерфейс был разработан для упрощения расширения портативных РС и комплектования их различными миниатюрными устройствами.
Несмотря на небольшие размеры карт стандарта PC Card, инженеры ухитрились "втиснуть" на них жесткий диск. В 1995 г. были определены три форм-фактора карт PC Card. Ширина 2.13" и глубина 3.37" карт всех трех форм-факторов одни и те же (размеры карт соответствуют размерам кредитной карточки). Форм-факторы отличаются только высотой (толщиной): устройства Type I имеют толщину 3.3 мм, Type II - 5.0 мм и Type III - 10.5 мм. Первоначально карты Type I и Type II предназначались для таких устройств, как модемы и память, а карты Type III - для жестких дисков. Однако со временем технологические достижения позволили некоторым компаниям разработать жесткие диски, которые помещались на картах Type II. Так как большинство портативных РС допускали подключение только двух карт Type I/II или одной карты Type III, выпуск жестких дисков на картах Type II оказался очень удобным.
Ширина 2.13" этого форм-фактора накладывает строгое ограничение диаметр
дисков накопителя - даже диски диаметром 2.5" оказываются слишком большими. Во
многих современных накопителях PC Card применяются диски диаметром 1.8".
Примером миниатюрного накопителя служит известный Microdrive компании IBM.
Отметим, что многие компании выпускают твердотельные накопители (Solid State
Drives - SSD) с форм-фактором PC Card. Они функционируют точно так же, как
обычные накопители на жестких дисках, но не имеют механических частей и
реализованы с использованием флэш-памяти (flash memory - см. далее CompactFlash.
Интересно отметить, что жесткие диски на картах PC Card не выпускают крупные
компании; по-видимому, это объясняется меньшим объемом рынка по сравнению с
обычными жесткими дисками.
Форм-фактор CompactFlash
Аналогично тому, как Ассоциация PCMCIA разработала карты PC Card для расширения возможностей портативных компьютеров, образованная в 1995 г. Ассоциация CompactFlash Association (http://www.compactflash.org/) разработала новый форм-фактор, названный, конечно же, CompactFlash (сокращенно CF или CF+). Этот форм-фактор похож на форм-фактор PC Card, но, как это неудивительно, даже меньше. Карты CF предназначены не для портативных РС, а для меньших электронных устройств, например ручных компьютеров (Hand-Held Computers - HHC), цифровых камер и коммуникационных устройств, включая сотовые телефоны.
Слово "flash" в названии форм-фактора CompactFlash подчеркивает основную технологию, используемую в этих картах - флэш-память (flash memory). Фактически флэш-память представляет собой микросхемы ROM с электрическим стиранием (Electrically-Erasable Read-Only Memory - EEROM), которые применяются на материнских платах РС для хранения BIOS. Имеющийся на карте контроллер позволяет стереть (flashing) cnfhjt содержание памяти и записать новое. Конечно, в отличие от обычной памяти RAM флэш-память является энергонезависимой, т.е. сохраняет содержание при выключении питания.
Главное назначение форм-фактора CompactFlash - предоставить потребительским электронным устройствам использовать карты CompactFlash как эквивалент жесткого диска. Поскольку флэш-память энергонезависима, она выполняет такую же главную функцию, как и жесткий диск. Имеются два стандартных размера карт двух типов карт CompactFlash, приведенные в следующей таблице. Разумеется, карты с большей толщиной позволяют разместить на них больше микросхем флэш-памяти, т.е. имеют большую емкость.
Форм-фактор |
Ширина (дюймы) |
Глубина (дюймы) |
Высота (дюймы/мм) |
Применение |
CF+ Type I |
1.69 |
1.42 |
0.13 / 3.3 |
Карты небольшой емкости для цифровых камер, ручных компьютеров; не используются (пока ?) для жестких дисков |
CF+ Type II |
1.69 |
1.42 |
0.20 / 5.0 |
Карты большей емкости как жесткие диски для цифровых камер, ручных компьютеров и др. |

Как видно из таблицы, карты форм-фактора CF настолько малы, что они, по-видимому, не рассчитывались на размещение настоящего жесткого диска. Однако в 1999 г., когда производители этих карт стремились достичь емкости 64 МБ, компания IBM выпустила накопитель Microdrive, который соответствовал форм-фактору CF. Вначале емкость накопителя составляла 170 МБ и 340 МБ, что было впечатляющим достижением для накопителя с единственным диском диаметром 1". Однако в 2000 г. был выпущен накопитель Microdrive емкостью 1 ГБ на карте CF Type II, которая имеет толщину всего 5.0 мм. Скорость вращения в этом накопителе составляет 3600 об/мин, а время разгона всего 0.5 секунды, что позволяет выключать накопитель в холостом состоянии ради экономии мощности.
По мере увеличения поверхностной плотности емкость таких накопителей будет
продолжать повышаться. В течение нескольких ближайших лет ожидается острая
конкурентная борьба жестких дисков с картами флэш-памяти. Она обусловлена
огромным объемом выпуска цифровых камер, ручных компьютеров и других электронных
бытовых устройств, в которых требуется все больше памяти.
Внешние жесткие диски
Подавляющее большинство дисковых накопителей является внутренними, т.е. они
монтируются внутри корпуса РС и скрыты от пользователя. Именно поэтому
накопители производятся в соответствии со стандартизованными форм-факторами -
они должны размещаться в отведенном им месте.

Однако выпускаются и внешние дисковые накопители, особенно рассчитанные на интерфейс SCSI. Фактически они мало не отличаются от внутренних накопителей, но имеют дополнительный пластиковый корпус, свой блок питания и, разумеется, дороже. Внешние накопители имеют некоторые достоинства по сравнению с внутренними, например их проще устанавливать, они, как правило, имеют лучшую систему охлаждения и могут работать с любыми системами, использующими интерфейс SCSI. Стандартных форм-факторов для внешних накопителей не существует. В прошлом внешние накопители были распространены больше, чем сейчас; по-видимому, сказывается их более высокая стоимость и необходимость размещения в ограниченном рабочем пространстве. На фотографии показан внешний жесткий диск Travelstar E компании IBM, который использует интерфейс карту PC Card.
В настоящее время внешние накопители стали широко применяться для расширения
и резервирования портативных компьютеров. Выпускается множество моделей,
использующих интерфейс параллельного порта РС или интерфейс PC Card. Во втором
варианте жесткий диск находится в пластиковом корпусе и имеет интерфейсный
кабель, заканчивающийся разъемом PC Card. Карта подключается портативному
компьютеру через слот PC Card. Тот факт, что жесткий диск не ограничен
физическими размерами слота PC Card, позволяет использовать накопители большей
емкости по сравнению с накопителями форм-фактора PC Card, сохраняя достоинства
интерфейса PC Card.
Лоток для сменного жесткого диска

Интересный компромисс между внутренними и внешними жесткими дисками представляет лоток для сменного жесткого диска (removable hard disk drive tray). Лоток устанавливается в стандартном корпусе РС и позволяет вставлять в него обычные дисковые накопители. Благодаря лотку можно сменять накопители, не открывая корпус РС, а это позволяет использовать жесткие диски как сменный носитель. На фотографии слева показана мобильная стойка (mobile rack), которая применяется в настольном РС для резервирования и архивирования. Накопитель вставляется в лоток (внизу), который расположен в стационарной доковой станции (docking station), показанной вверху. Сама доковая станция смонтирована в отсеке накопителя 5.25" и подключена к обычному кабелю IDE/ATA. С правой стороны виден замок, который фиксирует лоток, а также индикаторы питания и активности накопителя.
Для некоторых применений такая конструкция оказывается идеальным устройством
сменной памяти: в ней применяются обычные жесткие диски, которые являются очень
быстрыми, имеют высокую надежность и большую емкость, а также оказываются
относительно дешевыми по удельной стоимости. Их можно использовать для
резервирования внутреннего стандартного накопителя. Кроме того, возможность
простой смены жесткого диска позволяет работать на РС нескольким пользователям,
поддерживая их данные и программы совершенно отдельными.
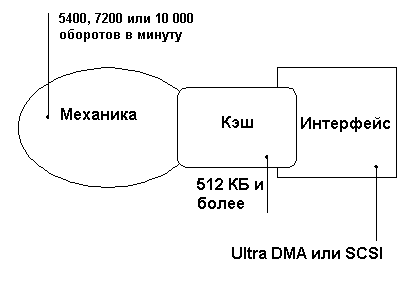
Накопители с интерфейсом IDE
На рисунке слева показана общая схема интерфейса жесткого диска. Одним из самых первых и наиболее важных стандартов в мире РС стал стандарт интегрированной электроники накопителей (Integrated Drive Electronics - IDE), который разработан компаниями Western Digital и Compaq в 1986 г. для преодоления ограничений производительности прежних стандартов ST506 и ESDI. Термин IDE сам по себе не определяет аппаратный стандарт, а представляет собой предложения, которые были введены в спецификацию промышленного интерфейса, называемую ATA (AT Attachment). Параллельный стандарт ATA родился из первоначального интерфейса Advanced Technology (AT) компании IBM и определяет для интерфейса набор команд и регистров, что привело к созданию универсального стандарта на коммуникацию накопителя и РС. Почти синонимами термина IDE являются названия ATA, ATA/ATAPI, EIDE, ATA-2, Fast ATA, ATA-3, Ultra ATA, Ultra DMA и др.
Одной из главных новинок IDE стало интегрирование функций контроллера диска в сам накопитель. Отделение логики контроллера от интерфейса позволило производителям накопителей повышать производительность накопителей независимо - в сам интерфейс ATA средства повышения производительности не вводились. IDE-накопители подключаются непосредственно к системной шине, не требуя отдельного контроллера на шине, что позволяет снизить стоимость системы. Быстрому распространению стандарта IDE способствовали два важнейших для массового пользователя обстоятельства - стоимость и совместимость, которые часто перевешивают производительность.
Со времени реализации стандарта ATA в РС произошли радикальные изменения.
Спецификация IDE была рассчитана на поддержку двух внутренних жестких дисков,
максимальная емкость которых не превышала 528 МБ, которая в 1986 г. казалась
просто немыслимой. Но за 10 лет появились более быстрые процессоры и новые
технологии локальных шин VLB и PCI, которые совместно с повышенными требованиями
программного обеспечения превратили интерфейс IDE в "узкое место"
производительности.
Интерфейс EIDE
В 1993 г. компания Western Digital разработала улучшенный интерфейс IDE
(Enhanced IDE - EIDE), который снимал ограничения ATA, обеспечивая вместе с тем
обратную совместимость. Интерфейс EIDE поддерживает более высокую скорость
передачи данных - Fast ATA обеспечивает пакетные скорости до 16.6 МБ/с - и
большую емкость - до 137 ГБ с середины 1998 г., когда был превышен прежний
предел интерфейса в 8.5 ГБ.
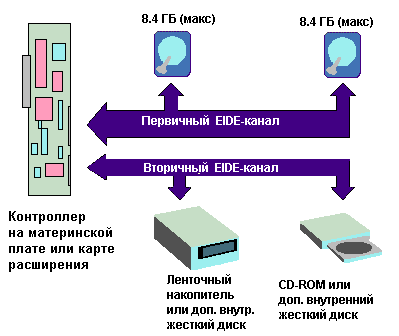
Для четырех возможных устройств в системе EIDE предусмотрено два канала. Каждый канал поддерживает два устройства в конфигурации ведущий-ведомый. Первичный порт обычно подключается к шине, например PCI, и устанавливается на те же самые адрес и линию IRQ, как в стандартной системе IDE. Это обеспечивает обратную совместимость с системой IDE и предотвращает конфликты, которые могли бы возникнуть с операционной системой или другими программами, взаимодействующими с IDE-устройством. Старая система IDE должна быть настроена на лучшие параметры EIDE (более высокая производительность и увеличенная емкость жесткого диска), а для этого потребуется дополнительная программа.
Когда хосту, т.е. обычно РС, требуется считать или записать данные,
операционная система вначале определяет местонахождение данных на жестком диске
- номер головки, цилиндр и сектор. Затем операционная система передает командную
и адресную информацию в контроллер диска, который позиционирует головки
считывания-записи на нужную дорожку. При вращении диска выбранная головка
считывает адрес каждого сектора на дорожке. Когда под головкой считывания-записи
оказывается нужный сектор, данные считываются в дисковый кэш обычно блоками по 4
КБ. После этого интерфейсная микросхема передает данные хосту.
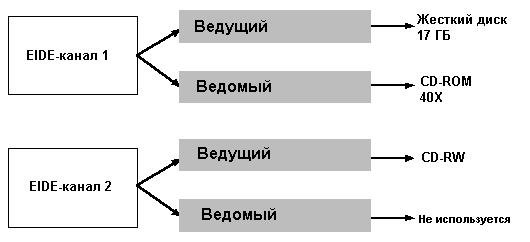
Поддержка недисковых периферийных устройств, например накопителей CD-ROM и
ленточных накопителей, стала возможной после разработки компанией Western
Digital спецификации пакетного интерфейса ATA (AT Attachment Packet Interface -
ATAPI). Расширение ATAPI протокола ATA определяет единую систему команд и единый
набор регистров, позволяющих другим устройствам разделять шину ATA с
традиционными ATA-накопителями на жестких дисках. Введено несколько специальных
команд для накопителей CD-ROM, включая группу команд Read CD, а также команду
быстрого выбора CD. На рисунке показана одна из возможных конфигураций
интерфейса EIDE в типичном РС.

На рисунке слева показаны разъем и кабель интерфейса EIDE. Обратите внимание на глухое отверстие в центре сверху, а также красную полоску с правой стороны кабеля (она показывает, что с этой стороны должен находиться контакт 1 разъема). Оба этих средства предназначены для того, чтобы предотвратить неправильное подключение разъема.
В дополнение к ATAPI интерфейс EIDE поддерживает стандарты передач, разработанные Комитетом ATA Committee. Режимы программного ввода-вывода (Programmed Input/Output - PIO) представляют собой набор протоколов для накопителя и контроллера IDE для обмена данными с различными скоростями; протоколы определяют спецификации участия процессора в передаче данных между жестким диском и памятью. Многие накопители также поддерживают работу с прямым доступом к памяти (Direct Memory Access - DMA), как альтернативный протокол режимам PIO. В этом режиме накопитель сам управляет шиной (мастеринг шины - bus mastering) и передает данные прямо в системную память. Режим DMA оказывается лучшим для мультизадачных РС, так как во время передач данных процессор может выполнять другие задачи. Однако процессор может использовать шину памяти или шину ISA в то время, когда шина PCI занята накопителем, только в системах с чипсетом Triton HX/VX или более новыми. Для реализации режима DMA требуется драйвер устройства в операционной системе, а системный BIOS также должен поддерживать эти спецификации.
В последующем индустрия жестких дисков разработала несколько методов для дальнейшего повышения производительности. Первый заключался в увеличении емкости накопителей путем повышения плотности дорожек и линейной плотности данных. При этом эффективно повышается и внутренняя скорость передач данных. Для дальнейшего повышения скорости передачи данных производители увеличивали скорость вращения дисков и совершенствовали алгоритмы работы дискового кэша. В конце концов, пришлось модифицировать и сам протокол ATA/IDE.
Оригинальная спецификация ATA была рассчитана на подключение накопителей к
шине ISA и скорости передачи ограничивались на уровне 2-3 МБ/с. Новый интерфейс
ATA-2, или Fast ATA, обеспечивал подключение к локальной шине и ее большая
пропускная способность позволила повысить скорость передачи данных. Поскольку
поставщикам систем и накопителей разрешалось маркировать их изделия как EIDE,
даже когда они поддерживали только подмножество спецификаций EIDE, несколько
поставщиков использовали термин Fast ATA (AT Attachment) для своих
EIDE-накопителей, которые поддерживали PIO Mode 3 и Multiword Mode 1 DMA, и
термин Fast ATA-2 для накопителей, которые поддерживали PIO Mode 4 и Multiword
Mode 2 DMA.
Ultra ATA
Во второй половине 1997 г. предел EIDE в 16.6 МБ/с был удвоен до 33 МБ/с новым протоколом Ultra ATA (он называется также ATA-33 или Ultra DMA Mode 2). Наряду с повышением скорости передачи данных Ultra ATA также улучшает целостность данных благодаря использованию циклического избыточного контроля (Cyclical Redundancy Check - CRC).
Оригинальный интерфейс ATA опирался на TTL-технологию шинного интерфейса,
которая, в свою очередь, опиралась на протокол старой шины ISA. В этом протоколе
используется асинхронная
передача данных. Сигналы команды и данных передаются вместе с импульсным
сигналом, называемым
стробом (strobe), но сигналы команды и данных не взаимосвязаны.
Одновременно можно передавать только один тип сигнала (команда или данные), а
это означает, что запрос данных должен быть завершен, прежде чем команду или
другой тип сигнала можно передать вместе с тем же самым стробом.
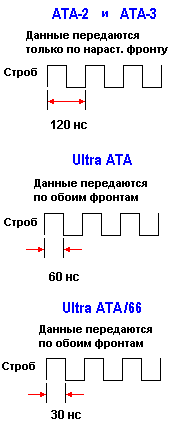
Начиная с ATA-2 применяется более эффективная синхронная передача данных. В синхронном режиме накопитель управляет стробом и синхронизирует сигналы команд и данных с нарастающим фронтом каждого импульса. Синхронные передачи данных интерпретируют нарастающий фронт строба как разделитель сигналов (signal separator). Каждый импульс строба может переносить сигнал команды или данных, допуская распределение команд и данных со стробом. Для повышения производительности в этом способе логично повышать частоту строба. Однако при повышении частоты система становится более чувствительной к электромагнитной интерференции (Electro-Magnetic Interference - EMI), называемой также помехами. Помехи могут вызвать искажение данных и ошибки при передаче. ATA-2 включает в себя PIO Mode 4 или DMA Mode 2, которые с появлением чипсета Intel Triton в 1994 г. обеспечили поддержку скорости передачи данных до 16.6 МБ/с.
Спецификация ATA-4 включает в себя Ultra ATA, который в попытках избежать EMI "выжимает" максимум из имеющихся частот строба, используя в качестве разделителей сигналов нарастающий и спадающий фронты сигнала строба. Это позволяет за одно и то же время передать вдвое больше данных. Если пакетная скорость передачи данных ATA-2 и ATA-3 составляет до 16.6 МБ/с, то Ultra ATA обеспечивает пакетную скорость передачи данных до 33.3 МБ/с. Спецификация ATA-4 добавляет Ultra DMA Mode 2 (33.3 МБ/с) к прежним режимам PIO 0-4 и традиционным режимам DMA 0-2. Реализуемый Ultra DMA циклический избыточный контроль (Cyclical Redundancy Check - CRC) стал новинкой для ATA. Значение CRC вычисляется для пакетов хостом и контроллером жесткого диска и сохраняется в их регистрах CRC. По окончании каждого пакета хост передает в контроллер жесткого диска содержание своего регистра CRC, который сравнивает значение хоста со своим. Если контроллер жесткого диска сообщает хосту об ошибке, хост повторно выдает команду, которая вызвала ошибку CRC.
Спецификация ATA-5 включает в себя Ultra ATA/66, которая удваивает пакетную скорость передачи Ultra ATA, уменьшая времена установления сигналов и повышая частоту строба. Повышенная частота строба вызывает увеличение EMI, которую нельзя устранить в стандартном 40-контактном кабеле, используемым в ATA и Ultra ATA. Чтобы уменьшить EMI, был разработан новый 40-контактный 80-проводный кабель. В этом кабеле добавлено 40 дополнительных земляных проводов между каждой парой из 40 земляных и сигнальных проводников оригинального кабеля. Введенные провода помогают защитить сигналы от воздействия EMI. Новый разъем остается совместимым по контактам с 40-контактными наборами штырьков, поэтому жесткие диски Ultra ATA/66 обратно совместимы с Ultra ATA/33 и DMA, а также с существующими жесткими дисками EIDE/IDE, накопителями CD-ROM и хост-системами. Спецификация ATA-5 ввела новый способ обнаружения ошибок с помощью циклического избыточного контроля и добавила режимы Ultra DMA 3 (44.4 МБ/с) 4 (66.6 МБ/с) к прежним режимам PIO 0-4, DMA 0-2 и Ultra DMA 2.
В следующей таблице показано, что в ходе эволюции интерфейса ATA было усовершенствовано несколько компонентов с целью повышения скорости и функциональности первой спецификации ATA:
| Спецификация | ATA | ATA-2 | ATA-3 | ATA/ATAPI-4 | ATA/ATAPI-5 |
| Режимы макс. передачи | PIO 1 | PIO 4 DMA 2 |
PIO 4 DMA 2 |
PIO 4 DMA 2 UDMA 2 |
PIO 4 DMA 2 UDMA 4 |
| Макс. скорость передачи | 4 МБ/с |
16.4 МБ/с |
16.4 МБ/с |
33.4 МБ/с |
66 4 МБ/с |
| Макс. число подключений | 2 | 2 | 2 | 2 на кабель | 2 на кабель |
| Требуемый кабель | 40-контактный | 40-контактный | 40-контактный | 40-контактный | 40-конт., 80-проводный |
| CRC | Нет | Нет | нет | Да | Да |
| Дата появления | 1981 г. | 1994 г. | 1996 г. | 1997 г. | 1999 г. |
Последнее поколение интерфейса параллельного ATA (Parallel ATA) до перехода
промышленности на интерфейс последовательного ATA (Serial ATA) объявлено в 2000
г. Новая спецификация, называемая также Ultra DMA Mode 5, рассчитана на прежний
40-контактный 80-проводный кабель, который разработан для Ultra ATA-66, повышает
пакетную скорость передачи данных до 100 МБ/с. Напряжение питания снижено с +5 В
до +3.3 В и ужесточены требования к временной диаграмме.
Последовательный ATA
В недалеком прошлом были разработаны две альтернативных технологии
последовательного интерфейса 0 универсальная последовательная шина (Universal
Serial Bus - USB) и IEEE-1394 как возможные замены интерфейса параллельного ATA.
Однако ни один из этих интерфейсов пока не может предложить такую комбинацию
низкой стоимости и высокой производительности, которая была основой успеха
традиционного интерфейса параллельного ATA. Однако, несмотря на успех, длинная
история параллельного ATA полным-полна проблем. Большинство этих проблем были
успешно преодолены или обойдены. Однако некоторые проблемы все же остались и в
1999 г. была образована рабочая группа Serial ATA Working Group (в нее вошли
компании APT Technologies, Dell, IBM, Intel, Maxtor, Quantum и Seagate
Technologies). Группа начала работу над интерфейсом Serial Advanced Technology
Attachment (ATA) для накопителей на жестких дисках и ATAPI-устройств; ожидается,
что интерфейс последовательного ATA должен заменить современный интерфейс
параллельного ATA.
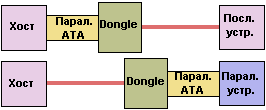
По сравнению с параллельным предшественником интерфейс Serial ATA будет иметь меньшее напряжение сигналов и меньшее число контактов, будет быстрее и живучее и будет иметь намного меньший кабель. Он будет также программно полностью совместим с Parallel ATA и обеспечит обратную совместимость со старыми устройствами Parallel ATA и ATAPI. Это будет достигнуто либо с помощью чипсетов, поддерживающих устройства Parallel ATA, совместно с дискретными компонентами, которые поддерживают устройства Serial ATA, либо с помощью последовательных и параллельных преобразователей (dongles), которые адаптируют параллельные устройства к последовательному контроллеру или адаптируют последовательные устройства к параллельному контроллеру.
Приведем основные достоинства Serial ATA по сравнению с Parallel ATA:
- Уменьшение напряжения и числа контактов: Малые напряжения сигналов Serial ATA (амплитуда 500 мВ) снимут трудно разрешаемые проблемы сигналов с напряжением +5 В современного интерфейса Parallel ATA.
- Меньшие и проще прокладываемые кабели и устранение ограничений длиной кабеля: Архитектура Serial ATA заменяет широкие плоские кабели интерфейса Parallel ATA на тонкий и гибкий кабель, который может иметь длину до 1 м. Последовательный кабель проще прокладывать внутри корпуса РС и он не требует громоздких 40-контактных разъемов интерфейса Parallel ATA. Кабель небольшого диаметра улучшит воздушный поток внутри корпуса РС и облегчит разработку будущих компактных РС.
- Повышенная живучесть данных: Интерфейс Serial ATA обеспечит более эффективное обнаружение и исправление ошибок по сравнению с Parallel ATA.
Ожидается, что первое поколение интерфейса Serial ATA появится в 2001 г. и
будет поддерживать скорость передачи данных до 150 МБ/с. В последующих версиях
спецификации скорость передачи данных будет доведена до 300 МБ/с и затем до 600
МБ/с.
Предел в 8.4 ГБ
При разработке первого РС было необходимо определить, сколько байтов выделить для адресации ячеек памяти в системе, включая и память жесткого диска. Также нужно было определить, как структурировать байты адреса для обращения к памяти. Вначале эти байты были разделены на адреса цилиндра, головки и сектора (Cylinder, Head, Sector - CHS), которые прямо связаны с физической топологией накопителей на жестких дисках. К сожалению, разработчики системного BIOS и интерфейса ATA не согласовали общее число байтов для одинаковой адресации и не определили одно и то же число байтов для адресации цилиндра, головки и сектора. Различия в конфигурациях CHS потребовали преобразования адреса, когда данные посылались из системы (с использованием системного BIOS) в интерфейс ATA. В результате возникали проблемы ограничения максимальной емкости накопителей в 528 МБ, 4.2 ГБ и последнего предела в 8.4 ГБ.
Ограничение в 8.4 ГБ вызвано общим адресным пространством, которое определено для системного BIOS. Большинство РС ограничено доступом к накопителям не более 8.4 ГБ (7.9 ГБ в некоторых РС). BIOS этих компьютеров не имеет достаточных адресов для доступа к более чем 8.4 ГБ. Это связано с тем, что текущий интерфейс ATA использует 28 битов адреса, которые поддерживают накопители с емкостью 2**28 x 512 байтов, или 137 ГБ. К сожалению, большинство системных BIOS используют адреса в 24 бита, которые обеспечивают доступ к 2**24 x 512 байтам, или 8.4 ГБ. Когда системе требуется считать данные с диска или записать данные на диск, BIOS должен использовать программное прерывание. Для доступа к дисковым накопителям обычно используется прерывание 13h. Это прерывание рассчитано на 24 адресных бита, что позволяет системе обращаться к дискам емкостью не более 8.4 ГБ.
Системные разработчики знали об этом ограничении и определили расширения для прерывания 13h, Они позволяют использовать для адресации счетверенное слово длиной 64 бита, что позволяет адресовать 2**64 x 512, или 9.4 x 10**21 байтов (это более чем в триллион раз больше накопителя с емкостью 8.4 ГБ). Очень мало систем, выпущенных до середины 1998 г. правильно поддерживали расширения прерывания 13h; к счастью, имеется несколько способов обойти эту проблему.
Однако и это еще не все - имеется еще одно ограничение, которое невозможно преодолеть, модернизируя BIOS. Из-за внутренних ограничений большинство версий операционной системы Windows 95 поддерживает максимальный размер раздела в 2.1 ГБ. Это означает, что накопители больше 2.1 ГБ необходимо разбивать на несколько логических накопителей C:, D: и т.д. Для накопителя емкостью 8.4 ГБ потребуется минимум четыре логических накопителя.
Компания Microsoft в качестве решения предоставила поддержку расширенной файловой системы. В этой системе число адресных битов в таблице размещения файлов (File Allocation Table - FAT) увеличено с 16 битов (FAT16) до 32 битов (FAT32), что повышает размер логического накопителя до 2.2 ТБ. Новая расширенная файловая система поддерживается в версиях OSR2.x системы Windows 95, а также в операционной системе Windows 98.
Следующее ограничение интерфейса ATA возникнет на емкости 137 ГБ, когда будут
исчерпаны возможности 28 адресных битов интерфейса ATA.
Накопители с интерфейсом SCSI
Как и в большинстве спецификаций компьютерного мира, оригинальная спецификация системного интерфейса малых компьютеров (Small Computer System Interface - SCSI) была закончена в 1986 г., когда уже велась разработка лучшей версии (SCSI-2). Интерфейс SCSI разрабатывался компаниями Shugart и NCR как новый интерфейс для миникомпьютеров. Основу интерфейса составлял (и составляет до сих пор) набор команд для управления передачами данных и взаимодействия между устройствами. Команды были очень сильной стороной SCSI, так как они придавали интерфейсу "интеллект"; однако вначале они же были и слабой стороной, так как не было стандарта на такую систему команд, которая удовлетворяла бы производителей устройств. Для стандартизации команд SCSI в последующем было расширение общей системы команд (Common Command Set - CCS).
SCSI, как и EIDE, образует шину, которая управляет передачами данных между процессором компьютера и периферийными устройствами, самым важным из которых является накопитель на жестких дисках. В отличие от EIDE, SCSI требует специальный интерфейс для подключения к шине PCI или ISA. Этот интерфейс не является контроллером; его правильнее называть хост-адаптером (host adaptor). Настоящие контроллеры встроены в каждое SCSI-устройство и они "сцепляют" SCSI-устройства, подключая их к шине через хост-адаптер.
Наиболее очевидным достоинством SCSI является число устройств, которым он
может управлять. Если интерфейс IDE ограничен двумя дисковыми накопителями, а
современный интерфейс - четырьмя устройствами (жесткие диски, накопители CD-ROM
и ленточные накопители), то SCSI-контроллер может управлять восемью
устройствами, включая и карту хост-адаптера, которая считается устройством.
Более того, устройствами могут быть жесткие диски, накопители CD-ROM, CD-R,
принтеры, сканеры, сетевые карты и многое другое.
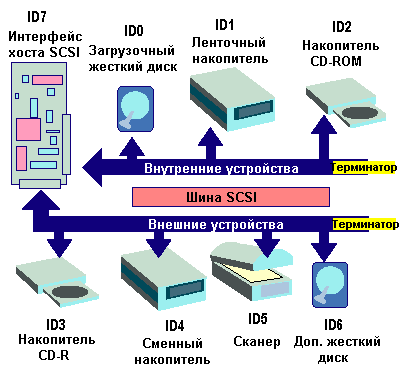
Каждое устройство в цепи, включая хост-адаптер, должны идентифицироваться уникальным номером ID. Одно SCSI-устройство не должно использовать такой же номер ID, как и другое, но можно нумеровать их произвольно. Большинство хост-адаптеров имеют внутренние и внешние разъемы, позволяющие расширять цепь в любом направлении. Нет взаимозависимости между номерами ID и физическими позициями устройств на шине, но оба конца шины должны заканчиваться резистивными терминаторами (terminator) для предотвращения отражения сигналов и обеспечения целостности данных при большой длине кабелей. Терминаторы могут быть представлены физическими перемычками, разъемами-вставками или даже программными конфигурациями.
Оригинальный интерфейс SCSI поддерживает до восьми устройств, используя номера ID от 0 до 7. Управляющий хост-адаптер традиционно занимает ID 7 и загружает операционную систему с устройства, имеющего наименьший номер ID. В большинстве SCSI-систем загрузочный жесткий диск имеет ID 0, а для незагрузочных устройств остаются номера ID с 1 до 6. При запуске SCSI-системы отображается список всех устройств с их номерами ID.
Хост-адаптер SCSI занимает линию запроса аппаратного прерывания IRQ, но
подключенные к карте устройства не требуют ее, что значительно упрощает
расширяемость. Фактически можно добавить вторую SCSI-карту еще для восьми
устройств. Более того, двухканальная SCSI-карта занимает только одну линию IRQ и
управляет до 15 периферийными устройствами.
Эволюция SCSI
Первоначальный стандарт SCSI-1 1986 г. сейчас устарел. В нем предусматривалась асинхронная передача 8-битовых данных с пропускной способностью 3 МБ/с. Допускалась поддержка до восьми устройств - хост-адаптер и до семи накопителей на жестких дисках.
В синхронной передаче хост и устройство совместно определяют максимальную поддерживаемую ими скорость передач данных и работают с этой скоростью. Интерфейс SCSI-2 начал разрабатываться в 1986 г. и в 1994 г. был утвержден Американским Национальным институтом стандартов (American National Standards Institute - ANSI). SCSI-2 поддерживает синхронную передачу со скоростью до 5 МБ/с и допускает подключение помимо жестких дисков и других устройств.
В SCSI-2 были предусмотрены также две опции повышения быстродействия: удвоение сигнальной частоты до 10 МГц (Fast SCSI) и добавление второго кабеля к шине SCSI, что обеспечило передачу как 16-битовых, так и 32-битовых данных (Wide SCSI). Эти опции можно использовать по отдельности или совместно в Fast Wide SCSI, что повышает скорость передачи данных до 20 МБ/с. Адаптеры Wide SCSI могут поддерживать в одной цепи до 16 устройств с номерами ID от 0 до 15.
После появления SCSI-2 ситуация несколько запуталась Спецификация SCSI-3, предложенная в 1996 г., разделила SCSI на несколько стандартов:
- Спецификация параллельного интерфейса (Parallel Interface), которая управляет работой SCSI-кабелей.
- Архитектурная модель (Architectural Model), определяющая команды, которые необходимы для реализации передачи данных.
- Спецификация первичных команд (Primary Commands), которая устанавливает команды для всех SCSI-устройств.
- Спецификация для типов устройств.
Более важно, что SCSI-3 не требует второго кабеля для Fast SCSI или Wide SCSI и добавляет поддержку волоконно-оптического кабеля. Введено также автоматическое конфигурирование SCAM (SCSI Configuration Auto-Magically), которое сняло жалобы пользователей на трудные инсталлирование и конфигурирование SCSI. Будучи подмножеством технологии Plug and Play, SCAM обеспечивает самоконфигурирование SCSI-устройств, которые сами выбирают свои номера ID, не требуя присваивания номеров ID вручную, как это производится в SCSI-1 и 2.
Расширение SCSI-2 реализовано в виде UltraSCSI или Fast-20. Здесь сигнальная скорость повышена до 20 МГц за счет сокращения шины SCSI до 1.5 м. В 1998 г. появилась новейшая версия UltraSCSI-2 или Fast-40. При работе шины с частотой 40 МГц 16-битовая реализация достигает теоретически максимальной полосы пропускания 80 МБ/с.
Реализация Ultra2 SCSI также допускает более длинные кабели благодаря переходу от несимметричной конфигурации к дифференциальной низковольтной (Low Voltage Differential - LVD) конфигурации. LVD сохраняет все достоинства дифференциальной высоковольтной конфигурации с напряжением +5 В, но не требует дорогих приемопередатчиков. Будучи намного менее подверженной помехам, LVD допускает кабели длиной до 12 м даже при подключении всех 16 устройств.
Объявленный в конце 1999 г. стандарт Ultra160 SCSI является подмножеством большего стандарта Ultra3 SCSI, который удваивает производительность своего предшественника Ultra2 SCSI. Технологически он предлагает три основных усовершенствования Ultra2:
- Циклический избыточный контроль (Cyclic Redundancy Checking - CRC), который контролирует все передаваемые данные, что значительно повышает целостность данных.
- Контроль домена (domain validation), который интеллектуально контролирует конфигурацию системы с целью повышения надежности.
- Синхронизация двойной передачи, которая является главным фактором повышенной пропускной способностью.
Следующая таблица показывает основные характеристики различных вариантов SCSI:
| Версия SCSI | Сигнальная скорость (МГц) |
Ширина шины |
Макс. DTR |
Макс. устройств | Макс. длина кабеля |
SCSI-1 |
5 |
8 |
5 |
7 | 6 м |
SCSI-2 |
5 |
8 |
5 |
7 | 6 м |
Wide SCSI |
5 |
16 |
10 |
15 | 6 м |
Fast SCSI |
10 |
8 |
10 |
7 | 6 м |
Fast Wide SCSI |
10 |
16 |
20 |
15 | 6 м |
Ultra SCSI |
20 |
8 |
20 |
7 | 1.5 м |
Ultra SCSI-2 |
20 |
16 |
40 |
7 | 12 м |
| Ultra2 SCSI | 40 | 16 | 80 | 15 | 12 м |
| Ultra160 SCSI | 80 | 16 | 160 | 15 | 12 м |
Интерфейс SCSI обеспечивает полную обратную совместимость, поэтому "древние" устройства SCSI-1 могут работать с новейшими хост-адаптерами. Конечно, для использования потенциального быстродействия новых SCSI-устройств требуется соответствующий хост-адаптер, а самый быстрый хост-адаптер не сможет ускорить старое медленное SCSI-устройство.
Интерфейс SCSI стал общепринятым стандартом для серверной массовой памяти и
реализация Ultra2 LVD часто применяется в избыточных массивах независимых дисков
(Redundant Array of Independent Disks - RAID) ради достижения большой скорости и
высокой доступности. Однако его доминированию в серверной памяти угрожает
недавно принятый стандарт Fibre Channel.
Сводка интерфейсов
В следующей таблице приведены сводные сведения о стандартах интерфейсов периферийного оборудования для настольных РС (DTR - скорость передачи данных):
| Стандарт | Типичные применения | Пакетная DTR | Примечание |
| ATA/IDE | Жесткие диски, накопители CD-ROM и DVD-ROM. | От 3.3 МБ/с до 66.6 МБ/с | Стандартная шина жестких дисков для предвидимого будущего. |
| SCSI | Жесткие диски, сменные накопители, сканеры. | От 5 МБ/с до 80 МБ/с | Стандартная шина скоростных жестких дисков для предвидимого будущего. |
| USB | Указывающие устройства, сканеры, цифровые камеры. | 12 МБ/с | В будущем может заменить последовательные и параллельные порты. |
| IEEE-1394 | Цифровые видеокамеры и другие скоростные устройства. | 400 Мб/с | Началось распространение в 2000 г. |
Стандарт Fibre Channel
Утвержденный институтом ANSI, стандарт Fibre Channel призван революционизировать организацию сетевой памяти. Он намного быстрее SCSI, так как первые реализации поддерживают скорости передачи данных до 100 МБ/с, а дуплексный режим повышает ее до 400 МБ/с. Стандарт Fibre Channel не страдает от ограничений на расстояние, характерных для SCSI, и допускает расстояние до 30 м по медным проводникам и до 10 км при использовании одномодального оптоволокна - аналогично сети Gigabit Ethernet, которая опирается на такие же транспортные протоколы.
Fibre Channel можно реализовать в форме непрерывной петли с арбитражем (Form of a Continuous Arbitrated Loop - FCAL), к которой подключаются сотни отдельных запоминающих устройств и хост-систем, но можно воспользоваться быстродействующим коммутатором, аналогичным сетевому коммутатору. В результате получается очень гибкая и отказоустойчивая технология; подключая дисковые массивы и устройства резервирования прямо к петле, а не к одному серверу, можно создать независимую сеть памяти (Storage Area Network - SAN). Это, в свою очередь, позволяет реализовать обмен данными между серверами и резервирование, не влияя на обычный сетевой трафик, что оказывается важным преимуществом для приложений клиент-сервер, связанных с использованием и обработкой огромных объемов данных.
В следующей таблице приведено сравнение Fibre Channel с более устоявшимися технологиями хранения данных (DTR - скорость передачи данных):
| Макс. DTR | Макс. расстояние | Макс. число устройств | Поддержка RAID | |
| IDE | 66.6 МБ/с | 1 м | 4 на контроллер | Возможно, но редко |
| Ultra Wide SCSI | 40 МБ/с | 1.5 м (до 25 м с дорогим окончанием) | 15 на контроллер | Да |
| Ultra2 LVD SCSI | 80 МБ/с | 12 м | 15 на контроллер | Да |
| Fibre Channel | 100 МБ/с (200 МБ/с в дуплексном режиме) | 30 мм по меди, 500 м по многомодальному оптоволокну, 10 км по одномодальному оптоволокну | 127 на петлю с арбитражем | Да, с независимым подключением к нескольким серверам. |
Архитектура последовательной памяти
Современные огромные базы данных и приложения, связанные с использованием и обработкой данных, требуют много памяти, а для передачи больших блоков информации требуется живучая, надежная и масштабируемая технология. Компанией IBM разработан интерфейс архитектуры последовательной памяти (Serial Storage Architecture - SSA) для объединения запоминающих устройств, подсистем памяти, серверов и рабочих станций в серверные приложения. Однако к началу 1999 г. он не получил широкого распространения и, по всей вероятности, в конкурентной борьбе уступит стандарту Fibre Channel.
Архитектура SSA обеспечивает защиту данных для критических приложений, гарантируя, что отказ одного кабеля не препятствует доступу к данным. Все компоненты в типичной SSA-подсистеме соединяются двунаправленными кабелями. Выданные адаптером данные могут доставляться получателю по петле в любом направлении. SSA обнаруживает нарушения в петле и автоматически реконфигурирует систему, обеспечивая соединение на время восстановления коммуникационной линии.
Система может поддерживать до 192 накопителей на жестком диске с возможностью "горячей замены". Емкость накопителей составляет 2.25 ГБ и 4.51 ГБ и конкретные накопители можно выделить для использования массивом в случае аппаратного отказа. Один адаптер способен поддерживать до 32 отдельных RAID-массивов и массивы допускается "зеркалировать" по серверам для обеспечения экономичной защиты в критических приложениях. Более того, массивы могут быть разнесены до 25 м (для соединения применяются тонкие дешевые медные кабели), что позволяет разместить подсистемы в защищенных удобных местах вдали от самого сервера.
Благодаря своей живучести и простоте применения архитектура SSA стала
использоваться в среде сервер-RAID, где она обеспечивает скорость передачи
данных до 80 МБ/с, причем продолжительная скорость данных составляет 60 МБ/с в
режиме не-RAID и 35 МБ/с в режиме RAID.
Технология RAID
В 80-е годы массовые накопители на жестких дисках имели ограниченную емкость, а большие накопители были чрезмерно дорогими. Как альтернатива одному дорогому и емкому накопителю разработчики систем памяти стали экспериментировать с массивами дешевых накопителей меньшей емкости. В 1988 г. исследователи из Калифорнийского университета в Беркли сформулировали правила организации таких массивов. Они предложили термин избыточный массив дешевых дисков (Redundant Array of Inexpensive Disks - RAID), чтобы отразить те преимущества по доступности данных и стоимости, которые могут обеспечить правильно реализованные массивы. Когда удельная стоимость за мегабайт значительно снизилась, слово "дешевых" (Inexpensive) было трансформировано в слово "независимых" (Independent), чтобы сделать упор на преимущества обеспечиваемой технологией доступности (availability) данных по сравнению с обычными системами дисковой памяти.
Первоначальный принцип состоял в группировании дешевых дисковых накопителей в массив таким образом, чтобы массив представлялся системе как один большой дорогой накопитель (Single Large Expensive Drive - SLED). Было показано, что такой массив должен иметь лучшие характеристики производительности по сравнению с традиционным одиночным накопителем. Но сразу же возникла проблема: среднее время между отказами (Mean Time Before Failure - MTBF) массива уменьшалось из-за вероятности отказа любого одного накопителя в массиве. Последующие разработки привели к созданию шести стандартизованных уровней RAID, обеспечивающих баланс между производительностью и защитой данных. Фактически слово уровень (level) может вызвать путаницу, так как эти модели не образуют иерархии; массив RAID 5 в принципе не является лучше или хуже массива RAID 1. Наиболее часто на практике реализуются уровни RAID 0, 1, 3 и 5:
- Уровень 0 обеспечивает чередование данных (data striping - буквально разбиение данных на полосы), т.е. распределение блоков каждого файла по нескольким дискам, но без избыточности. Этим повышается производительность, но не вводится отказоустойчивости. Набор накопителей в массиве RAID Уровень 0 распределяет данные таким образом, что они организуются в полосы (stripes) на нескольких накопителях, обеспечивая параллельное обращение к данным в нескольких накопителях. .
- Уровень 1 обеспечивает зеркалирование дисков (disk mirroring), когда данные одновременно записываются в дублирующих два накопителя. При отказе одного накопителя система мгновенно переключается на другой накопитель без потери данных и без перерыва в обслуживании. RAID 1 улучшает производительность по считыванию, но повышенные производительность и отказоустойчивость достигаются за счет доступной емкости используемых накопителей.
- Уровень 3 аналогичен Уровню 0, но жертвует некоторой емкостью для достижения лучших целостности данных и отказоустойчивости путем резервирования одного выделенного накопителя для хранения информации, предназначенной для исправления ошибок. В этом накопителе содержится информация о паритете (parity information), которая предназначена для обеспечения целостности данных во всех накопителях системы.
- Уровень 5 реализуется наиболее часто. Он выполняет чередование данных на байтовом уровне и также чередует информацию для исправления ошибок. Такая организация обеспечивает хорошую производительность и восстановление потерянных данных при отказе одного любого накопителя.
Чередование данных является краеугольным камнем технологии и используется в большинстве уровней RAID. Фактически базовая реализация RAID 0 не является истинным RAID, если не применяется совместно с другими уровнями RAID, так как в ней нет присущей отказоустойчивости. Чередование представляет собой метод распределения данных по физическим накопителям массива для создания большого виртуального накопителя. Данные подразделяются на последовательные сегменты, или полосы (stripes), которые последовательно записываются в накопители массива, и каждая полоса имеет определенный размер, или глубину (depth), в блоках. Такой массив накопителей может обеспечить лучшую производительность по сравнению с отдельным накопителем, если размер полосы соответствует типу прикладной программы, поддерживаемой массивом:
- В среде с интенсивным вводом-выводом или с множеством транзакций, где возникает несколько одновременных запросов небольших записей данных, предпочтительны большие (уровня блока) полосы. Если полоса в отдельном накопителе достаточна велика, чтобы содержать всю запись, накопители в массиве могут независимо реагировать на одновременные запросы данных.
- В среде с интенсивным использованием данных, где хранятся большие записи данных, более подходят меньшие (уровня байта) полосы. Если конкретная запись данных распределена по нескольким накопителям в массиве, содержание записи можно считать параллельно, что повышает общую скорость передачи данных.
С RAID тесно связан еще один принцип хранения данных под названием
расширенные доступность и защита данных (Extended Data Availability and
Protection - EDAP). Система памяти с возможностями EDAP может защищать
свои данные и предоставлять онлайновый немедленный доступ к данным несмотря на
возникновение отказов в дисковой системе, подключенных устройствах или в рабочей
среде. Местонахождение, тип и частота отказов определяют степень возможностей
EDAP, относящихся к дисковой системе. Два типа RAID обеспечивают EDAP для
дисков: зеркальный (Mirroring RAID) и паритетный RAID (Parity RAID).
Зеркалирование было разработано раньше паритетного RAID и было названо RAID
Уровень 1. Главный недостаток зеркального RAID заключается в том, что он требует
100%-й избыточности. Его достоинствами по сравнению с паритетным RAID являются
повышение производительности при считывании и допущение возможности
одновременного отказа нескольких дисков в группе. Паритетный RAID был назван в
как RAID Уровней 3, 4, 5 и 6. В этих случаях служебные потери (избыточные данные
в форме паритета) по сравнению с зеркальным RAID (избыточные данные в форме
полной копии) значительно снижаются и составляют от 10% до 33%.
Паритетные уровни RAID для восстановления данных при отказе диска объединяют чередование и вычисление паритета. На рисунке показаны чередование данных и паритетный RAID. Блок данных, содержащих значения 73, 58, 14 и 126 чередуется в массиве RAID 3, который содержит четыре накопителя данных и паритетный накопитель с использованием паритета по четности.
До конца 90-х годов прошлого века почти все реализации RAID относились к
серверной области. Однако затем быстродействие процессоров достигло такой точки,
когда основным узким местом, сдерживающим рост производительности систем, стал
накопитель на жестком диске. Поэтому появление в 2000 г. материнских плат с
контроллером RAID позволяет использовать RAID в высокопроизводительных
настольных системах.
Новые технологии накопителей большой емкости
Технология SMART
В 1992 г. компания IBM первой начала поставку накопителей на жестких дисках 3.5", которые могли предсказывать свой отказ. В них был реализован предиктивный анализ отказа (Predictive Failure Analysis - PFA); он представляет собой технологию, которая периодически измеряет выбранные параметры накопителя, например высоту полета головки, и посылает предупреждающее сообщение в случае превышения заданного порога. Благоприятное восприятие промышленностью технологии PFA, в конце концов, привело к стандартному индикатору предсказания надежности - технологии самоконтроля, анализа и уведомления (Self-Monitoring, Analysis and Reporting Technology - SMART) для накопителей IDE, ATA и SCSI.
Имеется два вида отказов накопителей на жестких дисках - непредсказуемые и предсказуемые. Непредсказуемые отказы возникают быстро без предварительного предупреждения. Они вызываются статическим электричеством, физическим повреждением или тепловыми проблемами пайки и их нельзя ни предсказать, ни избежать. Фактически примерно 60% отказов накопителей вызываются механическими причинами, часто из-за постепенного ухудшения производительности накопителя. Наиболее важными объектами являются:
- Головки: трещина на головке, разбитая головка, загрязнение головки, резонанс головки, ненадежное соединение с электронным модулем.
- Двигатель и подшипники: отказ двигателя, износ подшипников, чрезмерная скорость вращения, отсутствие вращения.
- Электронный модуль: отказ микросхемы, плохое соединение с накопителем или шиной.
- Носитель: царапина, дефект, повторные обращения, плохой сервомеханизм, исправления кода ECC.
За прошедшие годы эти проблемы были тщательно исследованы, что позволило разработчикам не только выпускать надежные изделия, но и применить полученные знания для предсказания отказов устройств. Путем исследований и мониторинга важных функций были определены пороги производительности, которые коррелированы с надвигающимся отказом и именно такие типы отказов SMART пытается предсказать.
Аналогично тому, что архитектуры накопителей на жестких дисках у разных производителей различны, так и в SMART-накопителях применяются разнообразные способы контроля доступности данных. Например, SMART-накопитель может контролировать высоту полета головки над носителем. Если головка начинает летать слишком высоко или слишком низко, вероятность отказа накопителя становится довольно высокой. В других накопителях могут контролироваться другие или дополнительные условия, например схемы ECC на карте накопителя или частота мягких отказов. Когда подозревается надвигающийся отказ, накопитель через операционную систему посылает предупреждение в приложение, которое отображает предупреждающее сообщение.
Крах головки (head crash), т.е. касание головкой носителя, является
одним из наиболее катастрофических отказов жесткого диска. Высота полета головки
за прошедшие годы постоянно снижалась для повышения поверхностной плотности и
общей емкости накопителей, а это вело к повышению вероятности отказа. К счастью,
это не так, поскольку высота полета всегда считалась важнейшим параметром
надежности накопителя и по мере уменьшения высоты полета разрабатывались все
более сложные способы предсказания краха головки. Однако опасно даже
кратковременное повышение высоты полета, так как магнитное поле может оказаться
недостаточным для надежной записи данных на носитель. Такая ситуация называется
"записью с большой высоты" (high fly write) и причиной ее могут быть внешний
удар, вибрация, дефект носителя или загрязнение. Мягкие ошибки, вызываемые этим
явлением, исправимы, а тяжелые ошибки исправить нельзя.
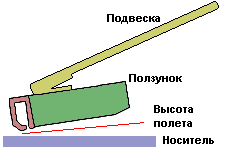
Высотой полета управляет подвеска, которая соединена с ползунком, содержащим головку и воздушный подшипник ползунка. Эта аэродинамическая система управляет высотой полета, когда ползунок позиционируется над поверхностью носителя. Переходы головки между внутренним и внешним радиусами вызывает двукратное изменение линейной скорости воздушного потока. До разработки современной технологии с воздушным подшипником такое изменение скорости приводило к двукратному изменению номинальной высоты полета. Однако сейчас это изменение сведено к незначительной части номинального значения и достигнута высота полета всего в 1.2 микродюйма (3 мкм). Имеется несколько внешних условий, например температура, высота и загрязнение, которые могут вызвать нарушения между воздушным подшипником и поверхностью диска и потенциально изменить высоту полета.
Сравнительно недавно к SMART отнесен тепловой контроль для извещения хоста о
том, что накопитель работает при слишком высокой температуре. В накопителе на
жестком диске чрезмерная температура воздействует на электронные и механические
компоненты, например подшипники привода, шпиндельный двигатель и привод со
звуковой катушкой. Возможными причинами повышения температуры могут быть
загрязненный охлаждающий вентилятор, вышедший из строя комнатный кондиционер или
недостаточно эффективная система охлаждения. Во многих реализациях SMART
используется тепловой датчик, который фиксирует окружающие условия, влияющие на
надежность накопителя, например температуру, скорость охлаждающего потока
воздуха, напряжение и вибрацию, и выдает пользователю предупреждение, когда
температура превышает установленный порог, обычно 60-65 градусов Цельсия.
Накопитель Microdrive

В середине 1999 г. компания IBM выпустила самый маленький в мире накопитель Microdrive, в котором ключевую роль сыграла GMR-технология. В накопителе используется один диск диаметром 1", который имеет вес всего 16 Г. Стандартный интерфейс CF+ Type II позволяет встраивать этот накопитель в различные ручные устройства, а с помощью адаптера обеспечивается совместимость с интерфейсом карт PCMCIA Type II. Крошечные элементы внутри Microdrive предоставляют некоторые уникальные возможности. Например, время разгона накопителя составляет всего 0.5 с, что позволяет выключать шпиндельный двигатель при отсутствии обращений к данным, а это улучшает характеристики экономии мощности.
Емкость накопителя составляет 170 МБ и 340 МБ, при скорости вращения 4500
об/мин время поиска равно 15 мс, а среднее время запаздывания 6.7 мс. Скорость
передачи данных варьируется от 32 Мб/с до 49 Мб/с.
Технология OAW
GMR-технология обещает в ближайшие годы достичь поверхностной плотности 40
Гб/кв. дюйм. Однако некоторые производители жестких дисков полагают, что при
плотности 20 Гб/кв. дюйм возникнет явление потери данных из-за того, что данные
упакованы слишком плотно. Компания Quinta Corporation пытается преодолеть этот
технологический барьер памяти (его часто называют Superparamagnetic Limit),
разрабатывая технологию винчестера с оптической помощью
(Optically Assisted Winchester - OAW).
Технология OAW имеет много общего с магнито-оптической (Magneto-Optical - MO) технологией, но использует несколько способов устранения недостатков емкости и производительности МО-форматов. В рассматриваемой технологии для выбора различных головок в накопителе применяется лазерный луч, а не типичная электромагнитная система обычных накопителей. Принцип простой: лазер фокусируется на поверхности диска и может использоваться для считывания и записи. Считывание опирается на эффект Керра - при отражении поляризованного света от намагниченной поверхности его поляризация перекручивается. При пропускании через поляризованный фильтр интенсивность света будет соответствовать выравниванию подсвеченного домена.
Такой способ считывания требует от лазера небольшой мощности, поэтому нагрев носителя минимален, что предотвращает искажение данных. Лазер и оптику можно использовать и для записи, используя магнито-оптический способ. Крошечный участок на поверхности диска нагревается достаточно мощным лазером до температуры выше точки Кюри. При этом магнитные свойства материала поверхности можно изменить с помощью магнитной катушки. При этом изменяются характеристики поляризации света. Однако в отличие от обычной магнито-оптики в OAW-технологии нагрев носителя и запись производятся за один проход вместо нагрева на одном обороте и записи на другом. Это стало возможным благодаря применению микрозеркала (micromachined mirror) и крошечного объектива для очень точной фокусировки лазера на минимально возможный участок. Соседние участки не нагреваются и остаются неизменными.
Поскольку используемый для нагрева носителя лазер можно сфокусировать на
участок намного меньших размеров, чем магнит, достигается большая плотность
данных. Сам носитель изготовлен из аморфного сплава и не имеет гранулярной
структуры, т.е. плотность ограничивается на атомном уровне. В отличие от обычных
магнито-оптических дисков лазерный луч подводится к головке по оптоволокну, а не
направляется с помощью зеркал по воздуху. В результате головка и рычаг занимают
намного меньшее пространство, позволяя "втиснуть" несколько дисков в такой же
форм-фактор, что и у обычного винчестерского жесткого диска. Производительность
также сравнима с обычным жестким диском, но долговечность намного больше, так
как носитель диска очень стоек при комнатной температуре.
Голографические жесткие диски
В конце 1995 г. консорциум университетских, промышленных и правительственных
организаций США выступил с программой разработки системы голографической памяти
(Holographic Data Storage System - HDSS). На первом этапе планировалось
разработать несколько ключевых компонентов системы, включая широкополосный
модулятор света для ввода данных, оптимизированный массив датчиков для вывода
данных и мощный полупроводниковый красный лазер. Одновременно исследователи HDSS
рассматривали проблемы архитектуры оптических систем, например схемы
мультиплексирования и режимы доступа, методы кодирования и декодирования данных,
способы обработки сигналов и требования к приложениям. На последнем году
программы член консорциума IBM Research Division показал, что ключом к созданию
огромной памяти в следующем тысячелетии могут стать голограммы.
Большие объемы данных можно хранить голографически, так как лазеры способны сохранять страницы электронных узоров внутри специальных оптических материалов, а не только на поверхности. В традиционной голографии при рассматривании объекта под разными углами наблюдения объект выглядит по-разному. Однако в голографической памяти производится обращение к разным "страницам" информации.
В голографической памяти используются два лазерных луча - эталонный луч и луч данных - для создания интерференционного узора на носителе, где два луча пересекаются. Такое пересечение вызывает устойчивое физическое или химическое изменение, которое сохраняется в носителе. Таким образом производится запись данных. При считывании взаимодействие эталонного луча и хранимого интерференционного узора воссоздает такой луч данных, который можно воспринять массивом детекторов. Носителем служит вращающийся диск, содержащий полимерный материал, или один оптически чувствительный кристалл. Ожидается, что голография будет широко применяться в архивах и библиотеках, где требуется хранить огромные объемы данных при минимальных расходах.
Благодаря отсутствию движущихся частей голографическая память окажется
намного надежнее современных накопителей на жестких дисках. Компания IBM уже
продемонстрировала возможность хранения 1 ГБ данных в кристалле размером с
кусочек сахара и скоростью доступа к данным в один триллион битов в секунду.
Следующим крупным шагом вперед должно стать создание перезаписываемой
голографической памяти.
Память PLEDM
Несмотря на наличие различных технологий жестких дисков для текущего тысячелетия, может оказаться, что будущее жестких дисков совсем не связано с механическими системами памяти. Новые разработки полупроводниковой памяти могут привести к тому, что твердотельная память окажется серьезной альтернативой жестким дискам. Технология твердотельных дисков, означающая хранение данных в огромных банках быстродействующей памяти RAM, уже применяется в мощных серверах, но пока современные микросхемы памяти RAM не позволяют считать их емкой и дешевой заменой массовых жестких дисков. Однако крупнейшие производители полупроводниковой памяти, например компании Hitachi, Mitsubishi, Texas Instruments и другие, усиленно работают над созданием дешевых микросхем RAM большой емкости. Компания Hitachi и Кембриджский университет разрабатывают технологию PLEDM (Phase-state Low Electron-number Drive Memory).
В технологии PLEDM вместо конденсаторов обычных микросхем DRAM используются
двухтранзисторные ячейки. Важно отметить, что такая память будет сохранять
содержание даже при выключении питания. Ожидается, что первые коммерческие
изделия появятся в 2005 г. Время считывания и записи будет составлять менее 10
нс; ячейки обеспечивают большой сигнал даже при низком напряжении питания.
Устройство Millipede
В конце 1999 г. сотрудники исследовательской лаборатории компании IBM в Цюрихе доказали, что микро- и нано-механические системы способны конкурировать с электронными и магнитными устройствами массовой памяти. Вместо записи битов в виде намагниченных областей на поверхности диска в устройстве Millipede (многоножка) выплавляются крошечные выемки на записывающей поверхности тонкой органической пленки.
Рассматриваемая технология опирается на принципы электронного сканирующего микроскопа и использует зонды, смонтированные на концах крошечных кронштейнов, которые вытравлены в кремниевой пластине, для сканирования поверхности до мельчайших деталей. Зонды устройства Millipede (1024 в виде матрицы 32х32) нагреваются электрическими импульсами до температуры в 400 градусов Цельсия. Такой температуры вполне достаточно для расплавления поверхности полимерной пленки. При этом зонды оставляют выемки диаметром всего от 30 до 50 нанометров. Каждая выемка (и отсутствие ее) представляет собой бит. Для считывания данных устройство Millipede регистрирует, находится ли зонд на выемке или нет, воспринимая температуру кронштейна при пропускании тока. Стирание хранимых данных осуществляется нагревом всей органической пленки, в результате которого выемки исчезают.
Высокая скорость передачи данных достигается благодаря параллельной работе
множества крошечных зондов на небольшом участке поверхности. Сотрудники компании
IBM полагают, что данная технология позволит достичь удельной плотности 80
Гбит/кв. см, что в 5-10 раз больше предполагаемого физического предела магнитной
памяти.
