Процессоры фирмы Intel
Процессор (processor), часто называемый центральным процессором (Central Processing Unit - CPU), является главным компонентом ("мозгом") любого РС. Он определяет, по крайней мере, частично, какие операционные системы можно использовать, какие приложения можно выполнять, какова производительность РС и даже какова стоимость РС. Всю работу для пользователя прямо или косвенно выполняет процессор. Как и остальные аппаратные средства РС, процессоры постоянно совершенствуются. Исключительные технологические достижения в области обработки данных в первую очередь связаны с появлением все более мощных и быстрых процессоров.
Процессор играет важную роль в следующих аспектах компьютерной системы:
- Производительность: Процессор вносит определяющий вклад в производительность РС. Конечно, на общую производительность влияют и другие компоненты, но все же возможности именно процессора определяют максимальную производительность системы. Остальные компоненты только позволяют процессору достичь его полных потенциальных возможностей.
- Поддержка программного обеспечения: Все более быстрые и мощные процессоры позволяют использовать новейшее программное обеспечение. Кроме того, поддержка процессорами новых технологий предоставляет возможность работать с программами, недоступными для старых РС.
- Надежность и устойчивость: Качество процессора во многом определяет надежную и устойчивую работу системы.
- Потребляемая мощность и охлаждение: Первые процессоры потребляли незначительную мощность по сравнению с другими устройствами РС, но новые процессоры потребляют десятки ватт. Потребляемая мощность влияет на выбор метода охлаждения и надежность системы.
- Поддержка материнской платы: Процессор определяет используемый чипсет и, следовательно, материнскую плату, которая, в свою очередь, во многом определяет производительность и возможности РС.
При рассмотрении процессоров с общей точки зрения необходимо отметить следующие важные моменты:
- История развития процессоров РС тесно связана с фирмой Intel.
- Начало современным процессорам положено в 1971 г., когда фирма Intel выпустила первый в мире микропроцессор (microprocessor) 4004.
- В настоящее время можно идентифицировать семь или восемь поколений процессоров.
- В процессе эволюции процессоров важнейшую роль играет совместимость (compatibility).
Принципы работы процессора
Общие принципы работы процессоров всех компьютеров одинаковы. Процессор воспринимает сигналы в форме единиц и нулей (двоичные сигналы), оперирует ими в соответствии с набором машинных команд (инструкций - instructions) и формирует двоичные результаты. Напряжение на линии в момент передачи сигнала определяет, будет он считаться 1 или 0. В РС с питанием +3.3 В напряжение +3.3 В означает 1, а 0 В означает 0.
Процессоры определенным образом реагируют на входные нули и единицы и возвращают результат. Результат формируется в схеме, которая называется логическим элементом (logic gate), для построения которого требуется минимум один транзистор. Логические элементы выполняют различные операции на основе булевой логики (Boolean logic), которая опирается на алгебраическую систему, разработанную английским математиком Джорджем Булем. Основными булевыми операторами являются AND, OR, NOT и NAND (не AND); возможны также многие их комбинации.
Логические элементы работают на основе цифровых переключателей, или ключей (switch), которые переключают ток. Самый распространенный сейчас тип ключа - транзистор, называемый MOSFET-транзистором (Metal-Oxide Semiconductor Field-Effect Transistor - полевой МОП-транзистор). Когда на такой транзистор подается напряжение, он реагирует пропусканием или непропусканием тока. Большинство процессоров РС работают с напряжением питания +3.3 В, но старые процессоры (до и включая некоторые версии процессора Pentium) имели напряжение питания +5 В. В самом распространенном типе ключа на полевом МОП-транзисторе высокое напряжение включает схему, а низкое напряжение вблизи 0 В выключает схему.
Миллионы полевых МОП-транзисторов действуют совместно в соответствии с командами программы
и управляют прохождением электрического тока через логические элементы для получения нужного
результата. Каждый логический элемент содержит один или несколько транзисторов и каждый
транзистор должен управлять током так, чтобы схема включалась, выключалась или оставалась
в своем текущем состоянии.
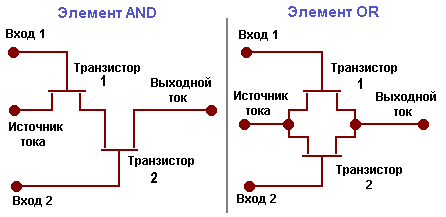
Простые логические элементы AND и OR показывают, как работают схемы. Каждый из элементов имеет два входных сигнал и один выходной сигнал. Логическое AND означает, что оба входа должны быть 1, чтобы выходной сигнал стал 1. Логическое OR означает, что любой вход может быть 1 для получения результирующей 1. В элементе AND оба входа должны иметь высокое напряжение (логическая 1), чтобы элемент пропустил через себя ток.
Прохождением электрического тока через каждый элемент управляет транзистор элемента. Однако эти транзисторы не являются изолированными образованиями. Огромное число транзисторов формируется на одной пластинке кремния и соединяется внутренними проводниками. В результате получается интегральная схема (Integrated Circuit - IC) и именно разработка интегральных схем сделала возможным появление микропроцессоров. Интеграция схем не прекратилась после выпуска первых интегральных схем. Если в первых интегральных схемах объединялось множество транзисторов, то затем стало объединяться множество интегральных схем и в результате получились большие интегральные схемы (Large-Scale Integration - LSI). Чрез некоторое время было освоено производство сверхбольших интегральных схем (Very Large-Scale Integration - VLSI).
Современные процессоры содержат десятки миллионов транзисторов, которые совместно с резисторами, конденсаторами и диодами образуют логические элементы. Логические элементы образуют интегральные схемы, а интегральные схемы образуют электронные системы. Фирма Intel первой решила объединить логические элементы процессора на одном кристалле кремния (чипе - chip) и в 1971 г. выпустила микропроцессор 4004. Это был 4-битовый процессор, предназначенный для калькулятора. Он оперировал данными длиной четыре бита, а команды имели длину восемь битов. Микропроцессор имел отдельные программную память емкостью 1 КБ и память данных емкостью 4 КБ. Программисту были доступны 16 4-битовых регистров общего назначения (General Purpose Register - GPR). Система команд (instruction set) насчитывала 46 команд. Микропроцессор содержал всего 2300 транзисторов, выпускался в 16-контактном корпусе с двухсторонним расположением выводов (Dual Inline Package - DIP) и работал на частоте синхронизации (clock rate) 740 кГц. Восемь тактов синхронизации составляли цикл процессора в 10.8 мкс.
Много лет в индустрии РС доминировали два семейства микропроцессоров - процессор Pentium фирмы
Intel и процессор PowerPC компании Motorola. Эти процессоры являются также наглядными примерами
двух конкурирующих архитектур процессоров - первый называется компьютером со сложной системой
команд (Complex Instruction Set Computer - CISC), а второй компьютером с сокращенной
системой команд (Reduced Instruction Set Computer - RISC).
CISC-процессор
CISC-процессор представляет собой традиционную архитектуру компьютера, в которой процессор использует микрокод (microcode) для выполнения очень сложной системы команд. Команды могут иметь переменную длину и использовать все режимы адресации (addressing modes), что требует сложных схем для декодирования команд.
Система команд х86 переменной длины от 8 до 120 битов первоначально разрабатывалась для процессора 8086 с его ничтожными 30 000 транзисторов. В новых поколениях процессоров команд становилось больше. В процессор 80386 введено 26 новых команд, в процессор 80486 еще шесть команд, а в процессор Pentium - восемь команд. Следовательно, для использования новых команд программы необходимо переписывать, что происходило в новых версиях Windows. В результате для выполнения некоторых программ требуются процессор 80386 или Pentium.
В течение нескольких лет производители компьютеров разрабатывали все более сложные процессоры,
которые имели все большие системы команд. Однако в 1974 г. инженер John Cocke из компании
IBM предложил подход, который позволил резко сократить число команд. В середине 80-х годов
прошлого века этот подход был реализован несколькими производителями, которые разработали
процессоры, способные выполнять только очень ограниченную систему команд.
RISC-процессор
RISC-процессоры имеют команды постоянной длины, например 32 бита в процессоре Pentium Pro, лишены косвенного режима адресации и сохранили только те команды, которые можно совмещать и выполнять в одном машинном цикле (machine cycle) или менее. Одно из преимуществ RISC-процессоров состоит в том, что они могут выполнять команды очень быстро, так как они очень просты. Еще одно, более важное, достоинство заключается в том, что RISC-процессоры требуют меньше транзисторов, а это значит, что их можно быстрее и дешевле разрабатывать и производить.
У специалистов пока нет единого мнения о ценности RISC-архитектуры. Сторонники ее полагают, что RISC-компьютеры дешевле и быстрее, поэтому являются компьютерами будущего. Противники отмечают, что хотя аппаратные средства дешевле, RISC-архитектура вызывает большую нагрузку на программное обеспечение, так как RISC-компиляторы должны генерировать программные процедуры для выполнения сложных команд, которые в CISC-компьютерах реализованы аппаратно. Кроме того, обычные микропроцессоры становятся все быстрее и дешевле.
В некоторой степени, аргументы сторонников обеих архитектур становятся спорными, так как
на практике CISC- и RISC-реализации становятся все более и более похожими. Многие современные
RISC-процессоры поддерживают столько же команд, что и вчерашние CISC-процессоры, и, наоборот,
современные CISC-процессоры используют многие приемы, которые раньше ассоциировались только
с RISC-процессорами. Даже лидер в CISC-процессорах - фирма Intel - использовала RISC-приемы
в процессоре 486 и продолжает расширять их в семействе процессоров Pentium.
Процессор с очень длинным командным словом
Процессор с очень длинным командным словом (Very Long Instruction Word - VLIW) использует длинные команды. Цель состоит в том, чтобы в одной команде объединить несколько команд. В этом случае процессор может за одну операцию считать несколько команд, что повысит производительность. Обычные не-VLIW процессоры воспринимают только одну команду в слове. Под словом понимается объем данных, передаваемых в процессор и VLIW-процессор получает несколько команд в одном слове.
Для переупорядочивания команд применяется программный компилятор. Рассматриваемый принцип прекрасно работает в специализированных процессорах, например цифровых сигнальных процессорах (Digital Signal Processor - DSP). Эти процессоры повторно выполняют одни и те же операции.
Центральный процессор РС является процессором общего назначения, а в этом случае реализовать
принцип VLIW очень сложно. Поэтому фирма Intel должна решать множество проблем при разработке
64-битового процессора Itanium, который опирается на принцип VLIW. Отметим, что компания
TransMeta использовала принцип VLIW в процессоре Crusoe для портативных компьютеров.
Технологический процесс
От своих давних предшественников, выполненных на электронных лампах, дискретных транзисторах или небольших интегральных схемах, микропроцессор отличается тем, что законченный процессор выполнен на одном кристалле кремния. Кремний является полупроводником, который при легировании примесей по определенному шаблону превращается в транзистор, являющийся базовым компонентом всех цифровых схем. Технологический процесс заключается в травлении (etching) транзисторов, резисторов и токопроводящих дорожек и других элементов на поверхности кремния.
Прежде всего необходимо вырастить кремниевый слиток (silicon ingot). Он должен иметь бездефектную кристаллическую структуру, что накладывает ограничения на размер слитка. В прошлом диаметр слитков был ограничен 2 дюймами, но сейчас выращивают слитки диаметром 8 дюймов. На следующем этапе слиток разрезается на полупроводниковые пластины (wafers). Пластины полируются до получения зеркальной поверхности без трещин. На этих пластинах формируются кристаллы микропроцессоров. Обычно на одной пластине формируются от 100 до 150 микропроцессоров.
Схемы создаются слоями, которые состоят из нескольких веществ. Например, двуокись кремния является изолятором, а поликремний применяется для проводящих дорожек. Из чистого кремния после бомбардировки ионами получаются транзисторы - этот процесс называется легированием (doping).
Для получения требуемой схемы добавляются новые слои, занимающие всю поверхность пластины, а ненужные участки вытравляются. Для этого новый слой покрывается фоторезистом (photoresist), на который проецируется изображение требуемой схемы. После экспозиции удаляются те участки фоторезиста, которые подвергались освещению, оставляя маску, через которую производится травление. После этого оставшийся фоторезист удаляется с помощью растворителя.
Процесс продолжается с формированием слоев до получения законченной схемы. Конечно, все линейные размеры элементов измеряются микронами (микрометрами - мкм) и даже мельчайшие пылинки могут испортить схему. Частицы пыли имеют размер примерно 100 мкм, что в 300 раз больше размеров элементов. Микропроцессоры производятся в чистых помещениях (clean rooms) - ультрачистой среде, где операторы одеты в костюмы, напоминающие космические скафандры.
В прошлом коэффициент выхода годных схем составлял менее 50%, а сейчас он повышен, но достичь 100% невозможно. Как только на пластину нанесены все слои, каждый микропроцессор контролируется и дефектные схемы отмечаются. После этого пластина разрезается на отдельные кристаллы (die). Дефектные кристаллы уничтожаются, а хорошие помещаются в корпуса, называемые матрицей штырьковых выводов (Pin Grid Arrays - PGA); они представляют собой керамические прямоугольники с рядами штырьков внизу.
Микропроцессор 4004 производился по технологии 10 мкм; такой размер по нынешним временам считается огромным. Например, кристалл процессора Pentium Pro по этой технологии должен иметь размеры 5.5x7.5 дюймов, а сам процессор работал бы медленно, так как более быстрые транзисторы должны быть меньше. В конце 1998 г. была освоена технология 0.25 мкм, в 1999 г. появились микросхемы, выполненные по технологии 0.18 мкм, а целью многих производителей микросхем является достижение технологии 0.1 мкм и даже меньше.
В следующей таблице приведены сводные данные о технологии различных современных процессоров:
| Процессор | Технология | Число транзисторов | Размер кристалла |
| 486 | 1.0 мкм | ||
| Intel Pentium | 0.5 мкм | ||
| Cyrix 6X86 | 0.5 мкм | ||
| Intel Pentium MMX | 0.35 мкм | ||
| AMD K6 | 0.25 мкм | ||
| Intel Pentium II | 0.35 мкм/0.25 мкм | ||
| Intel Celeron | 0.25 мкм | ||
| Cyrix MII | 0.25 мкм | ||
| AMD K6-2 | 0.25 мкм | ||
| AMD K6-3 | 0.25 мкм | ||
| AMD Athlon | 0.25 мкм | ||
| Intel Pentium III | 0.18 мкм | ||
| AMD Athlon "Thunderbird" | 0.18 мкм | ||
| Intel Pentium 4 | 0.18 мкм |

В заключение отметим, что все современные процессоры требуют внешнего охлаждения с помощью
специального теплоотвода и вентилятора ("кулера" - cooler), благодаря которым процессор работает
более надежно. Кроме того, хорошее охлаждение позволяет "разогнать" (overclocking) процессор,
т.е. несколько повысить рабочую частоту сверх номинальной. Компания Intel поставляет
процессоры "коробке" (in a box), которая содержит хорошие теплоотвод и вентилятор. Срок
гарантии такого процессора составляет три года. Питание на вентилятор подается двумя
способами. В старых РС питание подается от блока питания. На материнских платах с форм-фактором
ATX питание подается с материнской платы. В этом случае скорость вращения вентилятора
контролирует система BIOS, которая может управлять температурой процессора.
Базовая структура процессора
Основными функциональными компонентами современного процессора являются:
- Ядро (Core): Фактически это исполнительное устройство, или операционное устройство, (execution unit). Процессор Pentium имеет два параллельных целочисленных конвейера (pipelines), которые позволяют ему одновременно считывать, интерпретировать, выполнять и диспетчировать две команды.
- Предсказатель разветвления (Branch Predictor): Устройство предсказания разветвления (Branch Prediction Unit - BPU) пытается предугадать, какая последовательность будет выполняться после встречи в программе условного перехода, чтобы устройство предвыборки (Prefetch Unit) и устройство декодирования (Decode Unut) могли заранее получить готовые команды.
- Устройство с плавающей точкой (Floating Point Unit): Третье исполнительное устройство в процессоре Pentium, в котором выполняются операции с плавающей точкой. Отметим, что во многих офисных программах FPU не привлекается, но в программах трехмерной графики, например AutoCad, нагрузка на FPU очень велика.
- Первичный кэш (Primary Cache, L1-кэш): Процессор Pentium имеет два внутренних кэша по 8 КБ для кода (команд программы) и данных, которые работают намного быстрее большего внешнего вторичного кэша (L2-кэша).
- Шинный интерфейс (Bus Interface): Это устройство передает в процессор смесь команд и данных.
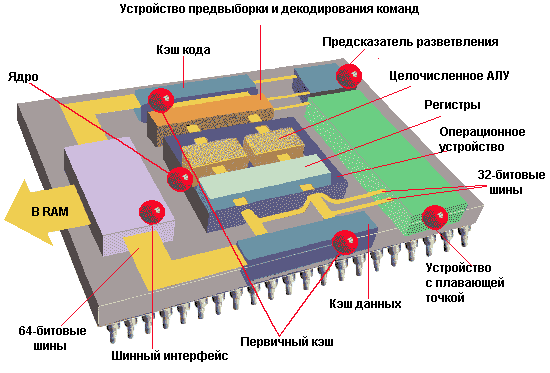
Все компоненты процессора работают согласованно благодаря генератору синхронизации (clock), определяющему скорость работы процессора. Первый микропроцессор имел частоту синхронизации 100 кГц, а в процессоре Pentium Pro она повышена до 200 МГц. Частота синхронизации новейших процессор превышает 1 ГГц. Программный счетчик (Program Counter - PC) - это внутренний регистр, который содержит адрес следующей выполняемой команды. Когда приходит время ее выполнения, устройство управления (Control Unit) передает команду из памяти в регистр команды (Instruction Register - IR).
Одновременно производится инкремент программного счетчика, так что он указывает на следующую команду в программе; теперь процессор выполняет команду, содержащуюся в регистре команды. Некоторые команды выполняет само устройство управления; если, например, команда указывает "перейти к ячейке 2749", значение 2749 записывается в программный счетчик, поэтому следующей процессор выполняет команду из данной ячейки.
Многие команды выполняются в арифметико-логическом устройстве (Arithmetic and Logic Unit - ALU). Оно работает совместно с регистрами общего назначения (General Purpose Registers - GPR) - ячейками временного хранения, которые можно загрузить из памяти или записать в память. Типичная команда ALU может прибавить содержание ячейки памяти к регистру общего назначения. ALU также изменяет биты в регистре состояния (Status Register - SR) после выполнения каждой команды. Этот регистр содержит информацию о результате предыдущей команды. Обычно биты регистра SR показывают нулевой результат, переполнение, перенос и др. Устройство управления использует информацию из регистра SR для выполнения команд условного перехода, например "перейти по адресу 7410, если предыдущая команда вызвала переполнение".
На этом мы закончим рассмотрение базовой архитектуры процессора и отметим, что любую
операцию можно выполнить, используя последовательности простых команд, аналогичных
рассмотренным.
Конструктивное оформление
Законченный кристалл процессора помещается в специальный корпус, имеющий
стандартизованную форму. Корпус вставляется в сокет (socket) или
слот (slot) на материнской плате, который процессор использует для
интерфейса с компонентами на материнской плате. Корпуса эволюционировали
вместе с тем как процессоры становились все больше и сложнее.
Корпус DIP
Для первых процессоров РС использовался стандартный для интегральных схем
того времени корпус с двухсторонним расположением выводов (Dual
Inline Package - DIP). Однако по мере увеличения числа входных и
выходных сигналов процессора корпус DIP вскоре оказался неподходящим.
Современные процессоры имеют буквально сотни сигналов, а так как корпус DIP
допускает только два ряда выводов, он становился слишком длинным.
Корпус PGA и его разновидности
Корпус типа матрица штырьковых выводов (Pin Grid Array - PGA) стал стандартным корпусом для процессоров второго, третьего, четвертого и пятого поколений. Корпус PGA представляет собой квадрат или прямоугольник, который имеет два или более рядов контактов (штырьков), расположенных по периметру. Корпус вставляется в специальный сокет (панельку) на материнской или дочерней плате.
До недавнего времени основным материалом для корпусов PGA была керамика (ceramic), поэтому иногда такие корпуса назывались CPGA. В некоторых новых процессорах материалом корпуса служит пластик (plastic) и их называют PPGA. У этого корпуса имеется выпуклая металлическая пластинка, которая лучше контактирует с теплоотводом.
Когда число выводов в процессоре Pentium и последующих процессорах достигло 300, потребовалось в том же пространстве расположить больше штырьков. Для этого штырьки были расположены зигзагообразно (staggered) и полученный корпус стал называться SPGA.
Наконец, для процессора Pentium Pro пришлось использовать специальную
разновидность корпуса PGA, которая называется dual pattern PGA.
Объясняется это тем, что в корпусе Pentium Pro находятся кристалл собственно
процессора и кристалл интегрированного L2-кэша.
Корпус SEC
Новейший стиль корпусов процессоров - процессорный картридж с одним краевым
разъемом (Single Edge Contact - SEC), который стал применяться,
начиная с выпуска процессора Pentium II. Фактически SEC представляет собой
небольшую дочернюю плату (daughtercard), которая содержит собственно процессор
и L2-кэш, имеет краевой разъем и вставляется в специальный слот (slot),
или разъем, на материнской плате. Это позволило фирме Intel запатентовать
новый интерфейс как Slot 1.
Корпус MMO
Портативные РС из-за ограничений размера и веса всегда всегда ставили серьезные
конструктивные проблемы. Чтобы преодолеть эти проблемы и обеспечить дальнейшую
миниатюризацию, фирма Intel разработала специальную конструкцию, которая
называется мобильный модуль (Mobile MOdule - MMO). Здесь в небольшом
модуле интегрированы собственно процессор, L2-кэш и чипсет. По существу, он
представляет собой небольшую материнскую плату.
Сокеты и слоты процессоров
Сокет на материнской плате предназначен для помещения в него процессора. За прошедшие годы фирма Intel определила несколько интерфейсных стандартов для материнских плат РС. Стандартизованные спецификации сокетов и слотов используются различными процессорами, конструкция которых ориентирована на стандартные сокеты и слоты. Стандартизация позволила и другим компаниям, в первую очередь, AMD и Cyrix, разрабатывать процессоры, совместимые с процессорами фирмы Intel.
Стандартизация позволила также решить еще одну проблему, очень важную для потребителей РС. В первые 10 лет выпуска РС потребитель, который желал повысить производительность своей системы был вынужден приобретать новый РС целиком. Фирма Intel реализовала свою программу OverDrive, которая позволила модернизировать РС, приобретая только новый процессор. Стандартизация сокетов обеспечивала поддержку текущими системами будущих процессоров, рассчитанных на стандартные сокеты. Зная имеющийся в их компьютере сокет, пользователи могли определить, какие процессоры могут поддерживаться их материнской платой.
Поскольку многие сокеты и корпуса процессоров квадратные, предусмотрено
несколько мер, исключающих вставку процессора с неправильной ориентацией.
Процессор обычно отмечается точкой или срезом в углу, который должен соответствовать
отмеченному углу сокета. Кроме того, во многих сокетах предусмотрены ключи
с помощью асимметричного расположения штырьков, поэтому процессор вставить
неправильно невозможно.
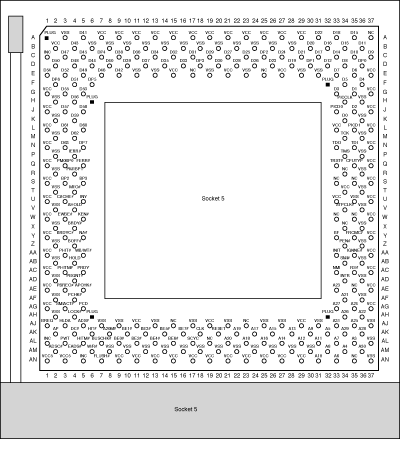
Появление стандартизованных сокетов привело к тому, что теперь пользователь должен был сам удалять и вставлять процессор. При большом числе штырьков (на рисунке слева показан Socket 5, рассчитанный на 320 соединений) эта процедура оказалась довольно затруднительной. Чтобы упростить эти операции, для сокетов был разработан сокет с нулевым усилием стыковки (Zero Insertion Force- ZIF). Такой сокет имеет небольшой рычажок, который закрепляет или освобождает штырьки корпуса процессора. Если поднять рычажок, можно легко (без усилий) вынуть или вставить процессор, а если опустить рычажок, процессор надежно фиксируется в сокете.
Процессоры OverDrive отличаются от обычных процессоров одним важным моментом - они предназначены для модернизации устаревших материнских плат, поэтому их обычно нельзя вставить в сокеты, рассчитанные на обычные версии этих же процессоров. Например, процессор Pentium рассчитан на материнские платы Socket 5 или Socket, а другие версии Pentium OverDrive можно использовать в сокетах от Socket 2 до Socket 7.
В следующей таблице приведены сводные данные по стандартным сокетам и слотам фирмы Intel.
Обозначение |
Число контактов |
Число рядов |
Питание |
Поколение |
Поддерживаемые процессоры |
Socket 1 |
169 |
3 |
+5 В |
Четвертое |
80486DX, 80486SX, 80486DX2, 80486DX4 OverDrive |
Socket 2 |
238 |
4 |
+5 В |
Четвертое |
80486DX, 80486SX, 80486DX2, 80486DX4 OverDrive, Pentium OverDrive 63 и 83 |
Socket 3 |
237 |
4 |
+5 В / +3.3 В |
Четвертое |
80486DX, 80486SX, 80486DX2, 80486DX4, AMD 5x86, Cyrix 5x86, Pentium OverDrive 63 и 83 |
Socket 4 |
273 |
4 |
+5 В |
Пятое (+5 В) |
Pentium 60-66, Pentium OverDrive 120/133 |
Socket 5 |
320 |
5 |
+3.3 В |
Пятое |
Pentium 75-133, Pentium OverDrive 125-166, Pentium с MMX OverDrive 125-166 |
Socket 6 |
235 |
4 |
+3.3 В |
Четвертое |
Не применяется |
Socket 7 |
321 |
5 |
+2.5 В - +3.3 В |
Пятое |
Pentium 75-200, Pentium OverDrive, Pentium с MMX, Pentium с MMX OverDrive, 6x86, K5, K6, 6x86MX |
Socket 8 |
387 |
5 |
+3.1 В / +3.3 В |
Шестое |
Pentium Pro |
Slot 1 |
242 |
Нет |
+2.8 В / +3.3 В |
Шестое |
Pentium II, Pentium Pro (Socket 8 на дочерней карте) |
Исторический обзор
Микропроцессор 4004 был предшественником всех современных процессоров фирмы Intel. В первом IBM PC использовался процессор Intel 8088, хотя раньше его фирма Intel выпустила более мощный процессор 8086. Процессор 8088 с внутренней 16-битовой архитектурой был выбран по экономическим соображениям: для его 8-битовой шины данных подходили более дешевые материнские платы, чем для 16-битовой шины данных процессора 8086. Кроме того, во время разработки IBM PC большинство интерфейсных микросхем были рассчитаны на 8-битовые устройства. Вычислительной мощности первых процессоров явно недостаточно для выполнения современных программ.
Следующая таблица показывает поколения (generations) процессоров фирмы Intel, начиная с первого поколения 8088/86 конца 70-х годов прошлого века до процессора седьмого поколения компании AMD Athlon, выпущенного летом 1999 г.
| Тип - Поколение | Год | Ширина шины данных/ адреса |
L1-кэш (КБ) |
Скорость шины |
Внутренняя |
8088 - Первое |
1979 |
8/20 битов |
Нет |
4.77-8 |
4.77-8 |
8086 - Первое |
1978 |
16/20 битов |
Нет |
4.77-8 |
4.77-8 |
80286 - Второе |
1982 |
16/24 битов |
Нет |
6-20 |
6-20 |
80386DX - Третье |
1985 |
32/32 битов |
Нет |
16-33 |
16-33 |
80386SX - Третье |
1988 |
16/32 бита |
8 |
16-33 |
16-33 |
80486DX - Четвертое |
1989 |
32/32 бита |
8 |
25-50 |
25-50 |
80486SX - Четвертое |
1989 |
32/32 бита |
8 |
25-50 |
25-50 |
80486DX2 - Четвертое |
1992 |
32/32 бита |
8 |
25-40 |
50-80 |
80486DX4 - Четвертое |
1994 |
32/32 бита |
8+8 |
25-40 |
75-120 |
Pentium - Пятое |
1993 |
64/32 бита |
8+8 |
60-66 |
60-200 |
MMX - Пятое |
1997 |
64/32 бита |
16+16 |
66 |
166-233 |
Pentium Pro - Шестое |
1995 |
64/36 битов |
8+8 |
66 |
150-200 |
Pentium II - Шестое |
1997 |
64/36 битов |
16+16 |
66 |
233-300 |
| Pentium II - Шестое | 1998 | 64/36 битов | 16+16 | 66/100 | 300-450 |
| Pentium III - Шестое | 1999 | 64/36 битов | 16+16 | 100/133 | 450-600 |
| Pentium 4 - Седьмое | 2000 | 64/36 битов | 8+32 | 400 | 1400-1500 |
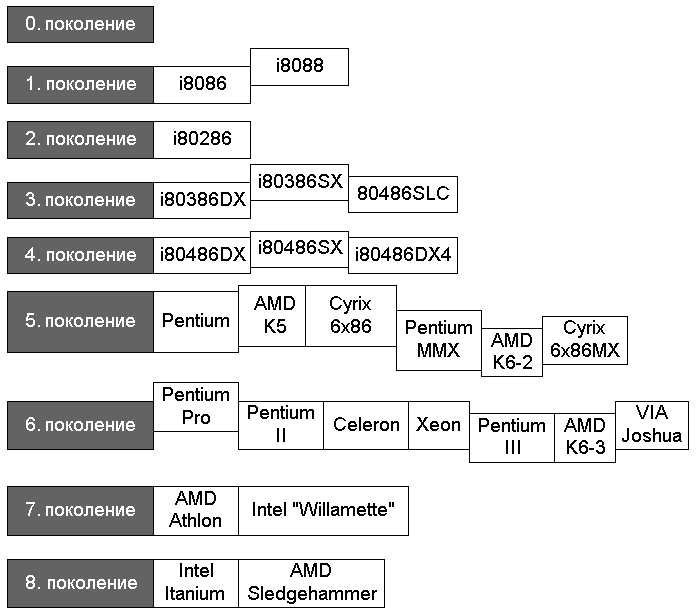
Следующий рисунок показывает более общую диаграмму поколений процессоров, в которой
приведены сведения по всем процессорам для РС. Отметим, что наряду с фирмой Intel процессоры
производят и другие крупные компании, например Cyrix и AMD. Иногда они выпускают модели,
которые перекрывают два поколения.
Процессор второго поколения 80286, выпущенный в 1982 г. также был 16-битовым процессором, но явился крупным шагом вперед по сравнению с процессорами первого поколения. Частота синхронизации была повышена, но основное улучшение было связано с оптимизацией обработки команд - на такт синхронизации процессор 80286 выполнял больше действий, чем процессоры 8088/8086. На частоте 6 МГц его производительность была в четыре раза больше, чем у процессора 8086 с рабочей частотой 4.77 МГц. Впоследствии частота синхронизации процессора 80286 была повышена до 8, 10 и 12 МГц и он применялся в компьютере IBM PC/AT с 1984 г. Еще одной новинкой процессора 80286 была возможность работы в так называемом защищенном режиме (protected mode), в котором он мог адресовать память 16 МБ. В последующем именно защищенный режим обеспечил переход с MS-DOS на Windows и мультизадачность (multitasking).
Процессоры третьего поколения Intel 80386DX и SX, освоенные в 1985 г., были первыми 32-битовыми процессорами в мире РС. Они определили 32-битовую архитектуру IA-32 (Intel Architecture), которая характерна для всех последующих процессоров. Основное отличие между 80386SX и DX состояло в том, что процессор 386SX был 32-битовым процессором только внутри, а его внешний интерфейс был представлен 16-битовой шиной данных. Поэтому данные передавались между процессором SX и остальными компонентами системы с половинной скоростью процессора 386DX. В процессоре 386 наряду с реальным (real mode) и защищенным (protected mode) процессора 286 введен режим виртуального 8086 (virtual 8086 mode), который открыл перспективы мультизадачности (multitasking). Процессор 386 мог "образовать" несколько процессоров 8086, каждый из которых работал в своем пространстве памяти. Процессор 386 был первым процессором, который хорошо работал с первыми версиями операционной системы Windows. Он мог адресовать память емкостью 4 ГБ и работал на частоте 16, 20 и 33 МГц.
Процессоры четвертого поколения 486, выпущенные в 1989 г., также были 32-битовыми, но в них было реализовано несколько новинок. Во-первых, благодаря схемным улучшениям производительность процессоров была повышена более чем в два раза. Во-вторых, все они имели внутренний кэш (internal cache) емкостью 8 КБ непосредственно на кристалле процессора. Кэширование передач данных из основной памяти означало, что процессор должен был ожидать данных с материнской платы только 4% времени, так как обычно он мог получать нужную информацию из кэша.
Модель 486DX отличалась от 486SX только тем, что она имела внутренний математический сопроцессор (math coprocessor). Этот отдельный процессор был предназначен для производства вычислений с плавающей точкой, поэтому его часто называют устройством с плавающей точкой (Floating-Point Unit - FPU). Наличие этого сопроцессора значительно повышает производительность РС в статическом анализе, автоматизированном проектировании, работе с электронными таблицами и т.д. Отметим, что для предыдущих процессоров математический сопроцессор выпускался в виде отдельной микросхемы: 8087, 80287 и 80387.
Важным новшеством стало удвоение частоты (clock doubling), введенное в процессоре 486DX2: внутренние схемы процессора работают с удвоенной скоростью по сравнению с внешними компонентами. Данные передаются между процессором, внутренним кэшем и математическим сопроцессором с удвоенной скоростью, что значительно повышает производительность РС. Этот способ был улучшен в процессоре 486DX4, который утраивал внешнюю синхронизацию и работал на частоте 75 МГц или 100 МГц; в этом же процессоре емкость внутреннего кэша удвоена до 16 КБ. Принцип повышения внутренней частоты синхронизации сохранен и усовершенствован в последующих процессорах. Например, в процессоре Pentium и аналогичных процессорах множители частоты (clock factors) составляют от 2 до 5. Процессоры Pentium II, Celeron и Pentium III могут работать с множителями частоты до 8 и даже 12.
Процессор Pentium является определяющим процессором пятого поколения и его производительность значительно выше процессоров 486 благодаря нескольким архитектурным усовершенствованиям, включая удвоение ширины шины данных до 64 битов. В процессоре P55C MMX также реализовано несколько новинок, включая увеличение емкости внутреннего кэша до 32 КБ и расширение системы команд для оптимизации выполнения мультимедийных функций.
Выпущенный в 1995 г. процессор Pentium Pro был первым процессором шестого поколения и в нем реализовано несколько уникальных архитектурных возможностей, которые раньше в процессорах РС не встречались. Pentium Pro стал первым процессором, в котором радикально изменено выполнение команд - команды транслируются в RISC-образные микрокоманды, которые выполняет мощное внутреннее ядро. В нем также впервые применен очень высокопроизводительный вторичный кэш (secondary cache - L2-кэш) по сравнению с прежними процессорами. Вместо L2-кэша на материнской плате, работающего со скоростью шины памяти, в Pentium Pro реализован интегрированный L2-кэш со своей шиной, работающий с полной скоростью процессора, обычно в три раза выше скорости L2-кэша в процессоре Pentium.
Новый процессор Pentium II фирмы Intel появился примерно через полтора года после Pentium Pro
и оказался эволюционным развитием процессора Pentium Pro. Поговаривали даже о том, что
главной целью фирмы Intel при разработке Pentium II было удаление дорогого и сложного в
производстве интегрированного L2-кэша. Архитектурно процессор Pentium II не сильно отличался от
процессора Pentium Pro; он имел аналогичное ядро эмуляции х86 и большинство прежних
возможностей.

Pentium II архитектурно улучшил Pentium Pro путем удвоения L1-кэша до 32 КБ, применения специальных
кэшей для повышения эффективности выполнения 16-битового кода (процессор Pentium Pro был
оптимизирован на выполнение 32-битового кода) и увеличения размера буферов записи. Однако
главной новинкой Pentium II стало новое конструктивное оформление. Интегрированный L2-кэш
процессора Pentium Pro, работающий с полной скоростью процессора), был заменен в Pentium II
специальной небольшой схемной платой, содержащей процессор и L2-кэш емкостью 512 КБ, работающий
с половинной скоростью процессора. Такая сборка, названная картриджем с одним краевым разъемом
(Single-Edge Cartridge - SEC), вставлялась в 242-контактный слот на новой материнской
плате, разработанной для Pentium II.
Архитектурные новинки
В соответствии с законом Мура (его сформулировал в 1965 г. Gordon Moore, основатель фирмы Intel) процессоры удваивают скорость и возможности через каждые 18-24 месяца. В прошлом фирма Intel следовала этому закону и опережала конкурентов, выпуская более мощные процессоры для РС раньше других компаний. В 1978 г. процессор 8086 работал на частоте 4.77 МГц и имел 30 000 транзисторов. К концу 1995 г. процессор Pentium Pro имел 21 млн транзисторов и работал на частоте 200 МГц, а процессор Pentium 4, выпущенный в 2000 г., содержит 42 млн транзисторов и работает на частоте 1.4 ГГц.
Физические законы препятствуют бесконечному повышению частоты синхронизации и хотя частота синхронизации каждый год повышается одно это не дает существенного увеличения производительности. Именно поэтому разработчики постоянно ищут способы для того, чтобы заставить процессор выполнять больше работы на каждый такт (tick) синхронизации. Одним из таких способов состоит в расширении шины данных и регистров. Даже 4-битовый процессор способен сложить два 32-битовых числа, но для этого потребуется множество команд, а 32-битовый процессор может произвести сложение одной командой. Большинство современных процессоров имеют 32-битовую архитектуру (IA-32), но уже планируется выпуск 64-битовых процессоров (IA-64). Постоянно совершенствуются внутренние схемы процессоров. Например, процессору 80386 требуется шесть тактов синхронизации для добавления числа к итоговой сумме, а в процессоре 80486 эта операция выполняется за два такта благодаря более эффективному декодированию команд.
В прошлом процессоры могли оперировать только целыми числами (integer, whole numbers). Можно написать программу из простых команд для обработки дробных чисел, но операции будут выполняться медленно. Почти все современные процессоры имеют команды для непосредственной обработки чисел с плавающей точкой.
Фраза "действия производятся на каждый такт синхронизации" недооценивает, как долго фактически выполняется команда. Традиционно на это требуется пять тактов: загрузить команду, декодировать ее, получить данные, выполнить команду и записать результат. В этом случае очевидно, что процессор со скоростью 100 МГц способен выполнить только 20 млн команд в секунду.
Все современные процессоры имеют суперскалярную (superscalar) архитектуру, т.е. имеют несколько операционных устройств, что позволяет выполнять несколько команд одновременно. Например, процессор Pentium Pro может выполнять до пяти команд в такте синхронизации. Можно считать суперскалярную архитектуру разновидностью внутренней мультиобработки (internal multiprocessing), поскольку фактически внутри центрального процессора имеется несколько процессоров.
Сейчас в большинстве процессоров применяется конвейеризация (pipelining), которая похожа на производственный конвейер. Для каждого этапа, необходимого для выполнения команды, выделяется одна ступень конвейера и по окончании своей операции каждая ступень передает команду следующей ступени. Это означает, что в любой момент времени одна команда загружается, другая декодируется, для третьей считываются данные, четвертая команда фактически выполняется, а для пятой записывается результат. С помощью современной технологии можно выполнить одну команду в каждом такте синхронизации.
Суперконвейеризация (superpipelining) означает конвейеризацию, в которой используется
более длинный конвейер (с большим числом ступеней) по сравнению с "обычной" конвейеризацией.
Теоретически схема с большим числом ступеней, каждый из которых выполняет меньше работы
(и, следовательно, имеет меньшую задержку), может работать на повышенной частоте. Однако это
зависит от многих других факторов, поэтому нельзя априори утверждать, что процессор с
суперконвейеризацией "лучше" процессора, не имеющего ее.
Рискованное выполнение и предсказание разветвления
Ранее показано, что большинство процессоров могут выполнять несколько команд одновременно. Иногда будут использоваться не все результаты выполнения, так как изменения в ходе программы могут быть такими, что некоторые команды никогда не выполняются. Особенно это относится к разветвлениям (branches), или условным переходам, где проверяется некоторое условие и в зависимости от результата проверки ход программы изменяется.
Разветвления очень часто встречаются в коде x86 и представляют серьезную проблему для конвейеризации, так как не всегда можно опираться на линейную последовательность команд. Конвейеризация подразумевает начало выполнения следующей команды до завершения текущей. При выполнении команды условной проверки типа if.. then до окончания ее выполнения невозможно узнать, какая команда будет выполняться следующей, т.е. не ясно, что вводить в конвейер.
Простой процессор остановит конвейер до получения результата проверки, что, разумеется, снижает производительность. Более сложный процессор будет рискованно выполнять (speculatively execute) выполнять следующую команду в надежде, что ее результат можно будет использовать, если разветвление "пойдет" по выбранному им пути. Еще более совершенный процессор объединяет это с предсказанием разветвления (branch prediction), т.е. с учетом прошлой истории процессор может довольно точно предсказать, по какому пути произойдет разветвление.
Рассмотрим для примера следующий фрагмент кода:
- IF A = B THEN
- C = C + 1
- ELSE
- C = C - 1
- END IF
Оператор IF...THEN представляет собой разветвление. До его полного выполнения невозможно узнать, будет следующей командой сложение или вычитание. Процессор с рискованным выполнением может одновременно начать выполнять сложение и вычитание, а затем просто уничтожить ненужный результат. В другом варианте процессор может использовать предсказание перехода, чтобы начать выполнять только одну операцию, которая с большей вероятностью (конечно, по мнению процессора) должна выполняться по результату оператора IF.
Предсказание разветвлений улучшает их обработку с помощью небольшого кэша, который называется
буфером цели перехода (Branch Target Buffer - BTB). Когда процессор выполняет разветвление,
он сохраняет в BTB необходимую информацию о разветвлении. Когда процессор в следующий раз
встречает это же самое разветвление, он сможет сделать обоснованное предположение о том,
по какому пути пойдет разветвление. Разумеется, чем больше емкость BTB, тем о большем числе
разветвлений он может хранить информацию. В результате конвейер работает почти без простоев,
что повышает производительность процессора.
Изменение последовательности команд
Процессоры с несколькими операционными устройствами теоретически могут закончить обработку команд
в ошибочном порядке - команда 2 может быть выполнена до завершения команды 1. Такая гибкость
повышает производительность, поскольку процессор работает, расходуя меньше времени на ожидание.
Однако необходимо обеспечить, чтобы результаты выполнения были "собраны" в правильном порядке,
чтобы вся программа выполнялась правильно.
Переименование регистров
Переименование регистров (register renaming) представляет собой способ организации
нескольких путей выполнения без конфликтов между операционными устройствами, которые пытаются
использовать одни и те же регистры. Вместо только одного набора регистров в процессоре
предусматриваются несколько наборов. Этот способ позволяет различным операционным устройствам
работать одновременно без ненужных простоев конвейеров.
Буферы записи
Буферы записи (write buffers) применяются для хранения результатов выполнения команд до
тех пор, когда их будет можно записать в регистры или ячейки памяти. Большее число буферов записи
позволяет организовать выполнение программы без простоя конвейеров.
Конвейеризация в современных процессорах
Процессор Pentium 4 (ранее называвшийся Willamette) фирмы Intel сейчас является самым производительным
процессором в мире РС и, возможно, вернет Intel мировое лидерство, которое пошатнулось при выпуске
процессора Athlon компании AMD. Повышенная производительности процессора Pentium 4 достигнута
введением нескольких архитектурных новинок, одной из которых стала усовершенствованная
конвейеризация (pipelinng). Далее рассмотрены основные положения конвейеризации.
Основные положения
Напомним, что любой современный процессор, в общем, похож на очень быстрый калькулятор. Он выполняет несложные арифметические операции и способен принимать простые логические решения. Например, он может взять значение 'a' и прибавить его к значению 'b' или определить, является ли 'a' больше 'b'. Конечно, чтобы процессор мог оперировать этими значениями, он должен знать, где хранятся эти значения и что делать с ними, например складывать, умножать и т.д. После локализации команд и данных, их интерпретации и выполнения необходимо сохранить результат в памяти для последующего использования. Таким образом, для выполнения команды процессор должен:
- Локализовать и считать данные из памяти; обычно этот этап называется выборкой (Fetching).
- Интерпретировать (транслировать) команду программы; этот этап называется декодированием (Decoding), или дешифрированием, команды.
- Выполнить заданную команду над заданными данными - этап выполнения (Executing).
- Поместить результат в ячейку памяти - этап сохранения (Store) результата.
Конечно, приведенные этапы являются очень упрощенным описанием работы процессора, но пока
нам этого вполне достаточно. Следовательно, для выполнения каждой команды процессор должен
выбрать (Fetch) данные, декодировать (Decode) команду, выполнить (Execute) команду и сохранить
(Store) результат.
Процессоры без конвейеризации
Рассмотрим вначале процессор без конвейеризации (unpipelined processor).

На диаграмме приведен пример одного такта синхронизации. Предполагается, что процессор имеет только одну ступень - команды выбираются, декодируются, выполняются и сохраняют результат на одном этапе. Другими словами, этот гипотетический процессор выполняет все действия (выборку, декодирование, выполнение и сохранение) в одном такте синхронизации. Предположим, ради простоты, что процессор работает на частоте 1 Гц, т.е. с одним такт синхронизации в секунду.
Нетрудно заметить, что для приведенного гипотетического процессора показатель числа команд на такт
синхронизации (Instructions-Per-Clock - IPC) равен 1. Рассмотренный процессор имеет IPC = 1 и работает
с частотой 1 Гц. Следовательно, за десять секунд, имея IPC = 1 и работая на частоте 1 Гц,
процессор выполнит десять команд.
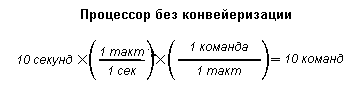
Теперь можно перейти к исследованию конвейеризации. Ее можно использовать для повышения
частоты синхронизации и общей производительности процессора. Напомним, что повышение частоты
синхронизации не всегда прямо трансформируется в повышенную производительность.
Повышение частоты синхронизации
Рассмотрим вначале, как с помощью конвейеризации можно повысить рабочую частоту синхронизации процессора. Предположим, что мы хотим повысить частоту синхронизации процессора с 1 Гц до 2 Гц. Как же это сделать? Очевидно, процессор должен выполнять свои операции быстрее.
Для этого можно, например, уменьшить размеры кристалла (die size) процессора, что обеспечит более быстрое переключение транзисторов в процессоре и позволит ему быстрее выполнять цикл "выборки-декодирования-выполнения-сохранения". Такой способ применяется на практике, но, к сожалению, современный уровень технологии допускает уменьшать размеры кристалла только до определенной точки. Поэтому "простое" уменьшение размеров кристалла для повышения частоты синхронизации не всегда практически возможно.
Но если невозможно заставить процессор выполнять полные задачи быстрее, почему не
уменьшить объем этих задач? Вместо выполнения всех операций выборки, декодирования,
выполнения и сохранения в одном такте синхронизации разобьем их на два этапа: пусть процессор
производит выборку и декодирование на первом этапе, а выполнение и сохранение - на втором.
Фактически мы только что преобразовали наш процессор в двухступенчатый конвейер!
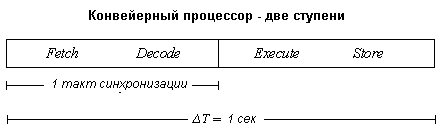
Теперь вместо выборки, декодирования, выполнения и сохранения в одном такте синхронизации процессор выбирает и декодирует команду в одном такте синхронизации, а затем выполняет команду и сохраняет результат во втором такте. Поскольку выполнение половины операций требует вдвое меньше времени, процессор может работать с удвоенной частотой синхронизации, причем для этого не нужно уменьшать размеры кристалла или вводить какие-то дополнительные модификации. (Еще раз напомним, что сильно упрощаем ситуацию, например выборка и декодирование не всегда требуют одного и того же времени, но мы полагаем, что временные интервалы одинаковы.)
Аналогичным образом можно подразделить процессор на 4-ступенчатый
конвейер. В этом случае каждая операция (выборка, декодирование,
выполнение и сохранение) будут выполняться в отдельном такте
синхронизации, что позволяет довести рабочую частоту процессора до 4
Гц.

В процессорах семейства x86 конвейеризация применяется уже много
лет. Для сравнения укажем, что в процессорах Pentium III и Athlon
используются конвейеры из десяти ступеней, а в процессоре Pentium 4
конвейер содержит 20 ступеней. Однако, как уже отмечалось, увеличение
частоты синхронизации не всегда повышает общую производительность.
Учетверенная частота синхронизации
Рассмотрим подробнее процессор с 4-ступенчатым конвейером.
Благодаря 4-ступенчатому конвейеру процессор может теперь работать на частоте 4 Гц. Казалось бы, что и весь процессор должен работать в четыре раза быстрее, но это не так.
Рассмотрим внимательнее приведенную диаграмму. Действительно,
процессор работает на частоте 4 Гц, но в каждом такте синхронизации
выполняется только 1/4 работы. Например, в первом такте производится
только выборка данных и ничего больше. Напомним, что процессор без
конвейеризации производит выборку, декодирование, выполнение и
сохранение в одном такте синхронизации. По-прежнему полагая, что
все операции выборки, декодирования, выполнения и сохранения занимают
один и тот же временной интервал, получается, что наш 4-ступенчатый
процессор при работе на учетверенной частоте имеет намного меньший
показатель IPC, а точнее - в четыре раза меньше. При рассмотрении
временного интервала в 10 секунд получается такая картина:
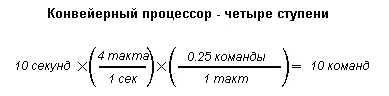
Таким образом, 4-ступенчатый конвейер выполняет точно такое же
число команд, как и процессор без конвейеризации, за любой временной
интервал. Он работает на учетверенной частоте синхронизации, но в
каждом такте синхронизации производит только 1/4 часть работы. Не
получая от рассмотренной конвейеризации никакого выигрыша, зачем же
вообще связываться с ней? Однако конвейеризация может на самом деле
повысить производительность процессора ...
Сборочная линия
Рассмотри сборочную линию на автозаводе. Первое, что нужно сделать - сварить стальной корпус автомобиля. После этого к нему можно присоединить задний бампер. Затем корпус можно передать на другое рабочее место, где к нему присоединяется другая деталь, например фары.
Вернемся теперь к нашей упрощенной модели 4-ступенчатого процессора и попробуем соотнести ее со сборочной линией. Наша ошибка заключалась в следующем: мы полагали, что процессор в любой момент времени может производить только выборку, декодирование, выполнение ИЛИ сохранение. Другими словами, он вначале производит выборку, затем декодирование, после этого выполнение и т.д. Ситуация похожа на сборочную линию, где один работник вначале сваривает корпус, затем устанавливает задний бампер, после этого монтирует фары и т.д.
Но фактически процессор способен производить выборку, декодирование, выполнение И сохранение одновременно, аналогично тому, как на сборочной линии несколько работников постоянно варят, прикручивают, монтируют - все одновременно. После того, как первый работник сварил корпус (команда выбрана), он не простаивает, а сразу же начинает сваривать следующий корпус.
В процессоре ступени конвейера похожи на работников, т.е. в нем есть устройство выборки (Fetching Unit), устройство декодирования (Decoding Unit), устройство выполнения (Execution Unit) и т.д., причем каждое работает на частоте синхронизации процессора. Ранее мы полагали, что устройство выборки (Fetching Unit) выбирало команду за один такт синхронизации (1/4 секунды), а затем ничего не делало, пока работали остальные устройства. Но, как и сварщик на сборочной линии, устройство выборки может не простаивать до завершения операций устройств декодирования, выполнения и сохранения, а сразу же может выбирать следующую команду. Рассмотрим следующую диаграмму:
| Устройство выборки | Устройство декодирования | Операционное устройство | Устройство сохранения | |
| Такт синхр. 1 | Команда 1 | |||
| Такт синхр. 2 | Команда 2 | Команда 1 | ||
| Такт синхр. 3 | Команда 3 | Команда 2 | Команда 1 | |
| Такт синхр. 4 | Команда 4 | Команда 3 | Команда 2 | Команда 1 |
| Такт синхр. 5 | Команда 5 | Команда 4 | Команда 3 | Команда 2 |
После первого такта синхронизации (1/4 секунды при 4 Гц) устройство выборки закончило выборку первой команды, которая затем передается в устройство декодирования (Decode Unit). Теперь вместо ожидания устройство выборки сразу же начинает считывать вторую команду. В результате, несмотря на то, что первой команде для полного выполнения требуются четыре такта синхронизации, последующие команды будут заканчиваться в каждом такте синхронизации.
Таким образом, за десять секунд (40 тактов синхронизации)
4-ступенчатый конвейер на частоте 4 Гц фактически выполнит 37 команд
(4 такта на первую команду, а затем по одной команде для последующих
36 тактов), а не десять команд, как мы полагали ранее. В результате
для 4-ступенчатого конвейера показатель IPC составит 0.9 команды на
такт синхронизации. Хотя показатель IPC конвейерного процессора на
10% меньше аналогичного показателя для процессора без конвейеризации,
его рабочая частота в четыре раза выше, поэтому производительность
конвейерного процессора намного выше.
Зависимость
Если конвейеризация так сильно повышает производительность, почему бы не сделать 500-ступенчатый конвейер и резко поднять производительность процессора? К сожалению, имеется несколько моментов, которые препятствуют этому. Главный из них - стоимость и сложность; для современной технологии реализация 500-ступенчатого конвейера просто невозможна. Но есть и другие проблемы ...
Часто в программах одна команда зависит от результата предыдущей команды. Например, команда 2 может быть другой в зависимости от результата команды 1. Рассмотрим следующий пример:
Команда 1 1 - Определить значение 'c', равное c = a + b.
Команда 2 2 - Если 'c' больше 4, умножить значение 'c' на 2.
d = 2c.
ИЛИ
Команда 2 - Если 'c'меньше 4, умножить значение 'c' на -2. d = -2c.
По средним оценкам примерно 10-20% типичного кода процессоров семейства x86 приходится на разветвления (условные переходы), аналогичные приведенным. В этой ситуации нельзя выполнять команду 2, не зная результата команды 1. Поэтому устройство выборки (Fetch Unit), например, должно ожидать несколько тактов окончания команды 1 прежде, начать выборку команды 2. Это приводит к потерянным тактам синхронизации и снижению производительности, что недопустимо. Как же поступать в таких ситуациях?
Одно из возможных решений называется предсказанием
разветвления (Branch Prediction). Здесь процессор делает
обоснованное предположение о том, каким будет результат, и продолжает
действия в соответствии со сделанным предположением. Например, для
приведенного примера процессор может, например, предсказать, что
результатом команды 1 будет c = 3 и переходит к команде 2,
предполагая, что 'c' меньше 4. Поскольку во многих программах часто
применяются повторяющиеся циклы, реализовать предсказание
разветвления несложно. Современные устройства предсказания
"угадывают" правильный маршрут в 90% случаев. А что же происходит в
оставшихся 10% случаев, когда предсказание оказывается неверным?
Неверные предсказания
Вернемся к ранее рассмотренному примеру.
| Устройство выборки | Устройство декодирования | Операционное устройство | Устройство сохранения | |
| Такт синхр. 1 | Команда 1 | |||
| Такт синхр. 2 | Команда 2 | Команда 1 | ||
| Такт синхр. 3 | Команда 3 | Команда 2 | Команда 1 | |
| Такт синхр. 4 | Команда 4 | Команда 3 | Команда 2 | Команда 1 |
| Такт синхр. 5 | Команда 5 | Команда 4 | Команда 3 | Команда 2 |
Предположим, что команды 2, 3, 4 и т.д. зависели от результата команды 1 и были выполнены в соответствии с предсказанным результатом. Предположим, далее, что предсказание оказалось неверным. Следовательно, команда 2 работала с неверными данными и ее необходимо повторно выполнить с правильными данными. Так же придется поступить и с командами 3, 4 и т.д. Это действие называется очисткой конвейера (Flushing Pipeline). Фактически процессор должен уничтожить все данные в конвейере и начать заново, так как все находящиеся в конвейере данные получены на основе ложного предположения. Такты синхронизации, израсходованные на выполнение таких команд, оказались пропавшими.
В двухстепенчатом конвейере только половина следующей команды была выполнена неверно и уничтожается, поэтому число пропавших тактов невелико. А теперь рассмотрим 10-ступенчатый конвейер. Так как до завершения команды 1 проходит 10 тактов синхронизации, процессор при ложном предположении израсходует 9 тактов синхронизации и все они окажутся пропавшими. В случае неверного предположения в 20-ступенчатом конвейере процессора Pentium 4 пропадут 19 тактов синхронизации.
По средним оценкам 10% неверных разветвлений ухудшают производительность процессора Pentium III примерно на 20-40%. Полагая, что только примерно 10-20% разветвлений заставляют начинать работу конвейера заново, получается, что в среднем неверные предположения возникают примерно на каждые 50-100 команд (10% от 10-20% команд разветвления). Если из этих 50-100 команд только одна команда будет предсказана правильно, процессор будет работать на 20-40% быстрее. Отсюда вытекает важность хороших алгоритмов предсказания.
Из приведенного материала становится очевидным, что при попытке
реализовать 500-ступенчатый конвейер снижение производительности
из-за относительно небольшого числа неверных предсказаний будет
весьма значительным.
Заключение
Еще раз напомним, что здесь приведен очень упрощенный материал. При разработке современного процессора приходится учитывать гораздо больше особенностей и ситуаций. Но все общие принципы правильны и должны помочь в понимании конвейеризации.
Конвейеры применяются для повышения не только производительности, но и рабочей частоты процессора. Для этого недостаточно просто сделать конвейер как можно длиннее - увеличение длины конвейера ставит особенные проблемы, например приходится увеличивать размер кристалла процессора (физические размеры кристалла процессора Pentium 4 примерно в два раза больше по сравнению с процессором Pentium III). Кроме того, при увеличении длины конвейера производительность снижается из-за неверных предположений разветвлений.
Возможно, в процессоре Pentium 4 с его 20-ступенчатым конвейером
несмотря на повышенную частоту синхронизации, производительность
может понизиться. Потери на неверные предположения окажутся слишком
большими, хотя фирма Intel приложила значительные усилия на улучшение
алгоритмов предсказания. По имеющимся оценкам производительность
Pentium 4 из-за более длинного конвейера будет ниже на 20%
производительности Pentoum III при одинаковой частоте синхронизации.
Однако в Pentium 4 реализовано и несколько других архитектурных
новинок, поэтому приведенная оценка может оказаться неправильной.
Не следует забывать и то, что благодаря 20-ступенчатому конвейеру
частота синхронизации Pentium 4 буде значительно выше, чем в Pentium
III. В частности, в начале 2001 г. фирма Intel объявила о выпуске
процессора Pentium 4 на рабочую частоту 1.7 ГГц.
Изменение последовательности команд
Основные положения
Под изменением последовательности команд, или внеочередным выполнением (out of order execution), понимают способность конвейерного процессора (pipelined processor) выполнять команды в более эффективном порядке по сравнению с тем порядком, в каком команды подаются в процессор. Такая способность позволяет избежать простоя ступеней конвейера и обеспечить пиковую производительность процессора. Рассмотрим следующий пример простых вычислений:
A = 5
B = 3
C = A + B
D = 4
Нетрудно заметить, что для вычисления C = A + B необходимо вначале полностью выполнить две операции
присваивания и оставить результаты в конвейере. Предположим, что команды присваивания требуют
для выполнения два такта синхронизации. Результирующее стандартное выполнение операций представлено на
следующем рисунке.

Как видно, команда C = A + B должна ожидать такт синхронизации. Этого можно избежать, выполняя
присваивание D = 4 до выполнения суммирования C = A + B. Конечно, предусматривать такие
ситуации программисту довольно сложно. Однако большинство современных процессоров могут
автоматически распознавать подобные ситуации. Поэтому они будут выполнять команду D = 4 раньше
команды C = A + B несмотря на то, что команда C = A + B находится в программе и попадает в
процессор раньше команды D = 4.
В результате получается такая картина выполнения операций:
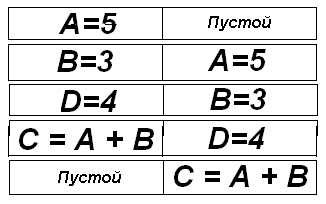
Сравнение этого рисунка с предыдущим показывает, что благодаря изменению порядка выполнения команд удалось сэкономить один такт синхронизации. Конечно, приведенный пример является очень простым, но он показывает общую идею изменения порядка выполнения команд.
На практике встречаются два типа изменения порядка выполнения команд. К типу 1 относятся ситуации, когда, например, устройство FPU очень занято и тогда процессор начнет выдавать другие типы команд, например команд целочисленных сложений, чтобы загрузить устройства процессора.
К типу 2 относятся ситуации изменения порядка выполнения команд одного вида. Если,
например, команда сложения зависит от результатов некоторых других команд, процессор может
выдать команду сложения, которая находится в программе после команды сложения, зависящей
от результатов других команд.
Изменение порядка выполнения команд в процессорах Р6
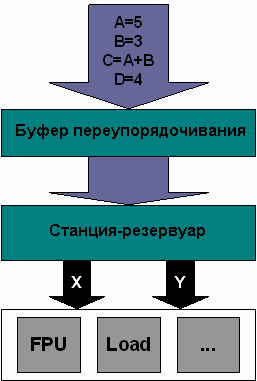
В процессорах шестого поколения фирмы Intel (Pentium Pro, Pentium II, Pentium II Xeon, Celeron, Pentium III и Pentium III Xeon) реализованы возможности изменения порядка выполнения команд. На рисунке слева показано, как работает ядро этих процессоров.
Команды вначале помещаются в буфер переупорядочивания (re-order buffer), который может содержать до 40 команд. (На самом деле команды прежде проходят через несколько других компонентов процессора и фактически в буфер переупорядочивания помещаются микрокоманды. Они представляют собой команды, преобразованные во внутренний формат процессора. Но ради простоты мы будем полагать, что в буфер переупорядочивания поступают команды.) После этого команды передаются в станцию-резервуар (reservation station); чаще это устройство называется планировщиком или диспетчером (scheduler). Диспетчер выдает команды в соответствующие устройства процессора. На рисунке показаны три устройства, но в реальном процессоре их гораздо больше.
Отметим два обстоятельства. Во-первых, все команды от диспетчера должны пройти через один из двух конвейеров X или Y. Во-вторых, устройство с плавающей точкой (Floating Point Unit - FPU) считается обычным устройством процессора и ничем особенным не выделяется. В других типах процессоров, как показано далее, к FPU используется другой подход.
Нетрудно догадаться, что изменение порядка команд происходит в буфере переупорядочивания.
Однако переупорядочивание реализует и диспетчер. Диспетчер в каждом такте синхронизации выдает
команды в соответствующие устройства процессора. В результате изменение порядка команд типа 1
происходит в диспетчере, а типа 2 - в буфере переупорядочивания.
Изменение порядка выполнения команд в процессорах K6
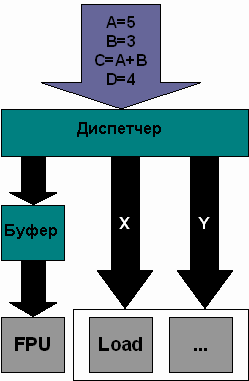
В процессорах семейства К6 (в том числе - K6-2 и K6-III) компании AMD также реализованы средства изменения порядка выполнения команд, что показано на рисунке слева. Здесь сразу же привлекает внимание то обстоятельство, что устройство с плавающей точкой FPU считается особенным устройством в составе процессора.
В процессорах семейства К6 функции буфера переупорядочивания и станции-резервуара реализованы в одном устройстве, которое называется диспетчером (scheduler). (Напомним, что в процессорах семейства Р6 станция-резервуар часто также называется диспетчером.) Диспетчер процессоров К6 может содержать 24 команды.
Когда диспетчер получает команды, предназначенные для FPU, он сразу же помещает их в специальный буфер FPU и никакого переупорядочивания не производится. Таким образом, в процессорах К6 изменения порядка выполнения команд с плавающей точкой не производится. Вместе с тем это частично компенсируется тем, что устройство FPU имеет отдельный конвейер и для него не используются конвейеры X и Y.
Ко всем остальным командам (MMX/3DNow! и целочисленным) применяется изменение порядка выполнения команд. Диспетчер может выдавать команды в операционные устройства не в том порядке, в каком они поступают в диспетчер. Однако он может применять только изменение порядка команд типа 1. Другими словами, он может выдавать только команды различных типов.
Однако в процессорах семейства К6 реализована еще одна возможность, напоминающая изменение порядка выполнения команд. Несмотря на то, что устройство FPU не обладает возможностями изменения порядка команд, оно может сигнализировать о завершении выполнения некоторых команд до того, как они фактически завершены.
Таким образом, процессоры семейства К6 обладают меньшими возможностями изменения порядка
выполнения команд по сравнению с процессорами семейства Р6. Но вместе с тем, необходимо
отчетливо понимать, что и необходимость изменения порядка команд в процессорах К6 меньше.
Целочисленные конвейеры процессоров К6 гораздо короче, чем в процессорах Р6, поэтому простой
конвейера влияет на производительность процессора гораздо слабее. Например, конвейер устройства
для команд MMX/3DNow! состоит всего из двух ступеней. Поскольку устройство FPU вообще не
имеет конвейера, понятие простоя конвейера для него отсутствует.
Изменение порядка выполнения команд в процессоре K7 (Athlon)
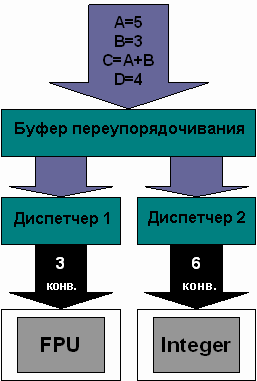
Процессор K7 обладает усовершенствованными возможностями изменения порядка выполнения команд. Как и процессоры семейства Р6, он имеет отдельные буфер переупорядочивания и станции-резервуары (диспетчеры). В процессоре К7 есть две станции-резервуара (два диспетчера), одна из которых предназначена для целочисленных команд, а вторая для команд FPU/MMX/3DNow!, Буфер переупорядочивания может содержать 72 операции.
Отметим, что блок FPU/MMX/3DNow! содержит три операционных устройства (конвейера), а целочисленное устройство - шесть конвейеров. Станция-резервуар FPU/MMX/3DNow! (диспетчер 1) может содержать 36 операций, а целочисленная станция-резервуар (диспетчер 2) - 15 операций.
Таким образом, в процессоре K7 изменение порядка выполнения применяется ко всем командам. Кроме того, он реализует изменение порядка команд обоих типов - типа 1 и типа 2. Всего имеется девять конвейеров, в которые можно выдавать команды.
В процессоре K7 требуются все средства изменения порядка выполнения команд для того, чтобы
все его девять конвейеров всегда оставались максимально заполненными. Совместно с большим
L1-кэшем 128 КБ, буфером предсказания перехода с 2048 элементами и очень быстрой шиной
EV-6 эти средства обеспечивают минимальный простой конвейеров процессора, т.е. его работу
с максимальной производительностью.
Программная совместимость
В прошлом многие люди писали собственные программы, поэтому точная система команд, которые мог
выполнять процессор, не играла существенной роли. Однако сейчас люди предпочитают пользоваться
готовыми программными продуктами, поэтому система команд приобрела первостепенное значение.
Несмотря на то, что с технической точки зрения ничего магического в архитектуре Intel 80x86 нет,
все же она превратилась в промышленный стандарт.
Самая сложная задача для процессора заключается в декодировании команд и локализации данных. Собственно вычисления особой сложности не представляют. Декодирование состоит в "понимании" команд программы, которые подаются в процессор. Процессоры всех РС являются "8086-совместимыми". Это означает, что программы взаимодействуют с процессором конкретным набором команд. Эти команды, в самом начале разработанные для процессора 8086, стали основой понятия "IBM-совместимый PC". Команды для процессора 8086 имели определенный формат.
В дальнейшем в связи с огромным объемом накопленного программного обеспечения оказалось необходимым, чтобы процессоры последующих поколений могли выполнять команды процессора 8086, чтобы сделать системы команд совместимыми. Новые процессоры должны понимать те же самые команды. С тех пор такая обратная совместимость (backwards compatibility) стала промышленным стандартом. Все новые процессоры, независимо от того, насколько они усовершенствованы, должны понимать формат команд процессора 8086. Таким образом, новые процессоры должны преобразовывать формат команд процессора 8086 в коды внутренних команд.
Если третья компания выпускает процессор с другой системой команд, он не сможет выполнять стандартные программы, поэтому его никто не купит. Поэтому в эпоху процессоров 386 и 486 некоторые компании, например AMD и Cyrix, клонировали процессоры фирмы Intel, а это приводило к тому, что они всегда оказывались на поколение позади. Процессоры Cyrix 6x86 и AMD K5 были конкурентами процессору Pentium, но они не были сделаны "под копирку". Процессор К5 имеет свою естественную систему команд и преобразует команды 80x86 в свои команды при загрузке, поэтому компания AMD не должна была ожидать Pentium до разработки К5. Многие схемы разрабатывались параллельно и только схемы преобразования отставали. Когда появился процессор К5, по производительности он превышал Pentium при одинаковой частоте синхронизации.
Еще одним способом придания процессорам с разными архитектурами определенного единообразия
для "внешнего мира" являются стандартные шины. Наиболее важным стандартом в этом отношении
является шина PCI (Peripheral Component Interconnect), которая появилась в 1994 г. Шина PCI
определяет совокупность сигналов, которые обеспечивают взаимодействие процессора с остальными
компонентами РС. Она включает в себя шины адреса и данных, а также много управляющих сигналов.
Процессоры имеют свои собственные шины, поэтому для преобразования этих "частных" шин в
"общественную" шину PCI используется чипсет (chipset).
Процессор Pentium

Слово pentium само по себе ничего не обозначает, но оно содержит слог pent, который на греческом языке обозначает пять. Первоначально фирма Intel хотела назвать Pentium как 80586, сохраняя преемственность с предыдущими процессорами. Однако ей не понравилось, что компании AMD, Cyrix с другие производители клонов (clone makers) могут также использовать название 80x86. В результате фирма Intel остановилась на названии Pentium и зарегистрировала его как торговую марку.
Появление процессора Pentium в 1993 г. коренным образом изменило рынок РС, предоставив в компактном корпусе большую вычислительную мощность, чем могучие компьютеры НАСА 60-х годов прошлого века, которым требовались вычислительные залы с кондиционерами. CISC-архитектура процессора Pentium представляла собой крупный шаг вперед по сравнению с процессором 486. Версии процессора на частоту 120 МГц и выше содержали более 3.3 млн транзисторов и производились по технологии 0.35 мкм. Внутри процессор использует 32-битовую шину, но внешняя шина данных имеет 64 бита. Внешняя системная шина потребовала спроектировать другую материнскую плату и для поддержки ее фирма Intel разработала специальный чипсет для соединения Pentium с 64-битовым кэшем и шиной PCI.
Производительность процессора Pentium благодаря нескольким архитектурным улучшениям была значительно выше его предшественника процессора 486. Фактически он удвоил производительность при работе с одинаковой частотой синхронизации. Кроме того, рабочие частоты процессора Pentium были выше, чем у процессора 486. Приведем самые важные архитектурные новинки процессора Pentium:
- Суперскалярная архитектура: Pentium является первым суперскалярным процессором - в нем имеются два параллельных операционных устройства. Фактически он был частично суперскалярным, так как второе операционное устройство не обладало всеми возможностями первого и некоторые команды не выполнялись во втором конвейере. Чтобы использовать достоинства наличия двух конвейеров, код требовалось оптимизировать для упорядочивания команд таким образом, чтобы оба конвейера работали одновременно. Вот почему для программных продуктов появилась ссылка на оптимизацию под Pentium.
- Более широкая шина данных: Шина данных Pentium была удвоена до 64 битов, что позволило удвоить пропускную способность при обращениях к памяти.
- Более быстрая шина памяти:Большинство процессоров Pentiums работало с системной шиной 60 или 66 МГц, а у процессора 486 частота системной шины составляла 33 МГц. На материнских платах для процессора Pentium появился пакетно-конвейерный L2-кэш. Наконец, процессор Pentium был первым процессором, рассчитанным на шину PCI.
- Предсказание разветвления: Pentium использует предсказание перехода для предотвращения простоев конвейера при выполнении команд разветвлений.
- Интегрированное управление мощностью: Все процессоры Pentium имели встроенный режим SMM (System Management Mode) для управления мощностью.
- Разделенный L1-кэш: Pentium использует L1-кэш, в котором имеется 8 КБ для данных и 8 КБ для команд. Оба кэша можно отдельно настроить в соответствии с их целевым использованием.
- Улучшенное устройство с плавающей точкой (Floating Point Unit - FPU): Устройство с плавающей точкой процессора Pentium было значительно быстрее FPU процессора 486.
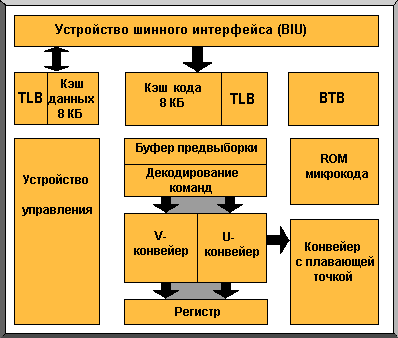
Большинство процессоров Pentium (75 МГц и выше) работало с напряжением питания +3.3 В, а для схем ввода-вывода использовалось напряжение +5 В. Процессор Pentium имеет двухконвейерную суперскалярную архитектуру, позволяющую в такте синхронизации выполнять несколько команд. Для выполнения целочисленных команд, как и в процессоре 486, имеется пять ступеней: предвыборка (prefetch), декодирование команды (instruction decode), формирование адреса (address generate), выполнение (execute) и запись (write back). Однако Pentium имеет два параллельных целочисленных конвейера, позволяющие считывать, интерпретировать, выполнять и диспетчировать две операции одновременно. Эти конвейеры производят только целочисленные вычисления, а для работы с вещественными числами имеется отдельное устройство с плавающей точкой (Floating-Point Unit - FPU).
В процессоре Pentium имеются два двунаправленных ассоциативных буфера емкостью по 8 КБ, которые называются первичным кэшем (primary cache), или L1-кэшем, и предназначены для команд и данных. Емкость L1-кэша увеличена вдвое по сравнению с процессором 486. Оба кэша значительно повышают производительность, так как они действуют как быстрое временное хранилище для команд и данных, полученных из более медленной основной памяти. Фирма Intel называет внутренний кэш ассоциативным буфером преобразования адреса (Translation Lookaside Buffer - TLB).
Буфер цели перехода (Branch Target Buffer - BTB) обеспечивает динамическое предсказание разветвления. Буфер BTB ускоряет выполнение команд, "запоминая" способ разветвления команды и применяя аналогичное разветвление при последующем выполнении команды. Когда буфер BTB делает правильное предсказание, производительность повышается. 80-битовое устройство с плавающей точкой оперирует вещественными числами. В процессоре предусмотрен режим управления системой (System Management Mode - SMM) для управления мощностью, потребляемой процессором и периферийным оборудованием.
В следующей таблице приведены различные модификации процессора Pentium с момента его выпуска в 1993 г. до появления Pentium MMX:
| Дата | Кодовое имя | Транзисторов | Технология (мкм) | Скорость (МГц) |
| 1993 г. | P5 | 3 100 000 | 0.80 | 60/66 |
| 1994 г. | P54 | 3 200 000 | 0.50 | 75/90/100/120 |
| 1995 г. | P54 | 3 300 000 | 0.35 | 120/133 |
| 1996 г. | P54 | 3 300 000 | 0.35 | 150/166/200 |
Процессор Pentium Pro


Процессор Pentium Pro, выпущенный в конце 1995 г., имел ядро из 5.6 млн транзисторов и L2-кэш из 15.5 млн транзисторов. Первоначально он предназначался для серверов и мощных рабочих станций, причем допускалась организация 4-процессорных систем. Его суперскалярная архитектура включала в себя новейшие возможности и была оптимизирована для работы в 32-битовом режиме. Для этого процессора были разработаны новые 242-контактный сокет Socket 8 и материнская плата.
Pentium Pro отличается от Pentium наличием внутреннего L2-кэша емкостью от 256 КБ до 1 МБ, который работает со скоростью процессора. Размещение L2-кэша рядом с процессором, а не на материнской плате позволяет передавать информацию по двум 64-битовым шинам, а не по одной 32-битовой шине, как в процессоре Pentium. Физическая близость процессора и L2-кэша также повышает производительность. Такая комбинация оказалась настолько мощной, что по сообщению фирмы Intel кэш емкостью 256 КБ на кристалле эквивалентен кэшу емкостью 2 МБ на материнской плате.
Дальнейшее значительное повышение производительности Pentium Pro достигнуто применением нескольких технологий, называемых динамическим выполнением (dynamic execution). Оно включает в себя предсказание разветвления, анализ потока данных и рискованное выполнение (speculative execution). Динамическое выполнение позволяет процессору использовать бесполезные в ином случае такты синхронизации, делая предположения о ходе программы для выполнения команд заранее.
Pentium Pro был первым процессором семейства x86, в котором использовалась суперконвейеризация (superpipelining). Конвейер состоит из 14 ступеней (по сравнению с пятью ступенями Pentium), разделенных на три секции. Входная секция, которая выполняет декодирование и выдачу команд, состоит из восьми ступеней. Среднее ядро, состоящее из трех секций, выполняет команды. Выходная секция состоит из трех заключительных ступеней.
Еще одной важнейшей отличительной чертой процессора Pentium Pro является способ обработки команд. Он воспринимает CICS-команды х86 и преобразует их во внутренние RISC-микрооперации. Такое преобразование призвано избежать некоторых ограничений системы команд х86, например нерегулярного кодирования команд и арифметических операций регистр-память. Микрооперации затем передаются в процессор с изменением последовательности команд, который определяет, готовы ли команды к выполнению; если команды не готовы, они пропускаются, чтобы предотвратить простой конвейера.
Применение RISC-подхода имеет некоторые недостатки. Во-первых, на преобразование команд
расходуется время. В результате производительность при обработке команд снижается. Во-вторых,
применение изменения последовательности команд приводит к простоям при выполнении 16-битового
кода. Они вызываются частичными обновлениями регистров, которые происходят до считывания полного
регистра и приводят к потерям до семи тактов синхронизации.
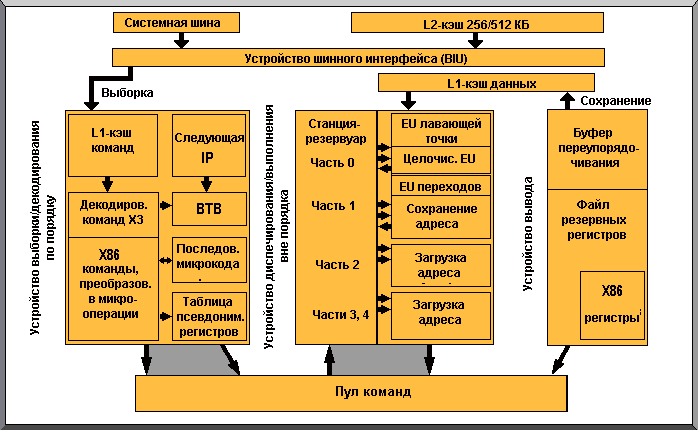
Производительность Pentium Pro примерно на 50% выше, чем у процессора Pentium при одинаковой частоте синхронизации. Наряду с новым способом обработки команд в Pentium Pro реализовано несколько технических новинок:
- Интегрированный L2-кэш: В Pentium Pro резко повышена скорость L2-кэша, который интегрирован с процессором и работает с полной скоростью процессора; традиционный L2-кэш размещается на материнской плате и работает со скоростью шины памяти, которая примерно в три раза ниже скорости работы L2-кэша процессора Pentium Pro. Кроме того, в процессоре реализован неблокирующий кэш, что позволяет процессору при промахе в кэше продолжать без ожидания.
- 32-битовая оптимизация: Pentium Pro оптимизирован на выполнение 32-битового кода, который использует большинство современных операционных систем и приложений. Это повышает его производительность при работе с новейшим программным обеспечением.
- Более широкая шина адреса: Шина адреса процессора Pentium Pro расширена до 36 битов, что позволяет ему адресовать память емкостью 64 ГБ.
- Организация мультипроцессорных систем: Процессор Pentium Pro допускает реализацию 4-процессорных систем, а не только двухпроцессорных систем, что обеспечивает Pentium.
- Улучшенное устройство предсказания разветвления: Размер буфера цели перехода по сравнению Pentium удвоен и точность предсказания повышена.
- Переименование регистров: Возможность переименования регистров улучшает параллелизм конвейеров.
- Рискованное выполнение: Процессор Pentium Pro использует рискованное выполнение для уменьшения времени простоя конвейеров RISC-ядра.
Следующая таблица содержит различные модификации процессора Pentium Pro, появившиеся после его выпуска в 1995 г.:
| Дата | Кодовое имя | Транзисторы | L2-кэш | Технология (мкм) | Скорость (МГц) |
| 1995 г. | P6 | 5 500 000 | 256/512 КБ | 0.50 | 150 |
| 1995 г. | P6 | 5 500 000 | 256/512 КБ | 0.35 | 160/180/200 |
| 1997 г. | P6 | 5 500 000 | 1 МБ | 0.35 | 200 |
После выпуска процессора Pentium II интерес в процессору Pentium Pro угас и в конце 1998 г.
он был снят с производства.
Процессор Pentium MMX
Процессор P55C MMX с мультимедийными расширениями (MultiMedia eXtensions) был выпущен в начале 1997 г. В нем реализовано наиболее значительное изменение базовой архитектуры процессора РС за десять лет, которое свелось к следующим основным усовершенствованиям:
- Емкость внутреннего L1-кэша стандартного процессора Pentium удвоена до 32 КБ (по 16 КБ для команд и данных). Кроме того, L1-кэш реализован как 4-направленный, а не двунаправленный, как в процессоре Pentium.
- Число ступеней в обоих внутренних целочисленных операционных устройствах увеличено с пяти до шести.
- Больше типов команд можно параллельно выполнять двумя операционными устройствами, что улучшает эффективность второго конвейера.
- Добавлено 47 новых команд, которые специально предназначены для более эффективной обработки видео-, аудио- и графических данных.
- Устройство предсказания разветвлений имеет более высокую точность предсказаний по сравнению с классическим Pentium.
- Разработан новый процесс один поток команд - много потоков данных (Single Instruction Multiple Data - SIMD), который позволяет одной команде одновременно выполнять операцию над многими фрагментами данных.

Большой L1-кэш обеспечивает наличие нужной процессору информации "под рукой", без необходимости обращения к L2-кэшу. Новые команды, используемые совместно с SIMD и восемью 64-битовыми регистрами, обеспечивают высокий параллелизм, например обработку восьми байтов в одном такте, а не одному байту в такте. Такой параллелизм особенно эффективен в мультимедийных и графических приложениях, например кодирования и декодирования видео и аудио, масштабирования изображений и интерполяции. Вместо передачи восьми пикселов графических данных в процессор и отдельной их обработки эти восемь пикселов можно передать как одно упакованное 64-битовое значение и обработать одной командой. По оценкам фирмы Intel этим достигается повышение производительности на 10-20% в не-MMX программах и до 60% в интенсивных MMX-приложениях.
Для процессора Pentium MMX потребовалась новая материнская плата, но не из-за MMX, поскольку это чисто программное средство, а потому что в этом процессоре для снижения выделения тепла использовались два напряжения питания: +2.8 В для ядра и +3.3 В для секции ввода-вывода. Классический процессор Pentium работал с одним напряжением питания +3.3 В.
В следующей таблице приведены различные модификации процессора Pentium MMX с момента его выпуска в 1997 г. до появления процессора Pentium II:
| Дата | Кодовое имя | Транзисторы | Технология (мкм) | Скорость (МГц) |
| 1997 г. | P55 | 4 500 000 | 0.28 | 166/200/233 |
| 1998 г. | P55 | 4 500 000 | 0.25 | 266 |
Процессор Pentium II
Выпущенный в середине 1997 г. процессор Pentium II имел несколько новинок. Во-первых, процессор и L2-кэш соединены специальной шиной, которая могла работать параллельно с системной шиной процессора. Во-вторых, L2-кэш и теплоотвод с вентилятором монтировались на небольшой плате, которая вставлялась в слот Slot 1 на материнской плате, что напоминало подключение дополнительной платы. Такая конструкция называется картриджем с одним краевым разъемом (Single-Edge Cartridge - SEC). Вес сборки составляет 380 Г. Третье изменение фактически является синтетическим, так как Pentium II объединяет сдвоенную независимую шину (Dual Independent Bus - DIB) процессора Pentium Pro и MMX-улучшения процессора Pentium MMX, образуя своеобразный гибрид Pentium Pro/MMX.
В отличии от процессора Pentium Pro, имеющего питание +3.3 В, процессор Pentium II работает с питанием +2.8 В, что позволяет повысить его рабочую частоту без чрезмерного увеличения потребляемой мощности. Например, процессор 200 МГц Pentium Pro с кэшем 512 КБ потребляет около 37.9 Вт, а процессор 266 МГц Pentium II с кэшем 512 КБ потребляет 37.0 Вт.
Как и Pentium Pro, процессор Pentium II использует технологию динамического выполнения (Dynamic Execution Technology). Когда команды программы считываются в процессор и декодируются, они помещаются в пул выполнения (execution pool). Технология динамического выполнения использует три подхода для оптимизации выполнения кода процессором. Несколько схем предсказания разветвления (Branch Prediction) анализируют ход программы по нескольким разветвлениям и предсказывают, где в памяти находится следующая команда.
В процессе считывания процессор также проверяет команды в конвейере, что ускоряет выполнение программы. Анализ потока данных (Data Flow Analysis) оптимизирует последовательность, в которой выполняются команды, анализируя декодированные команды и определяя, готовы ли они для выполнения или зависят от других команд. Рискованное выполнение, или выполнение по предположению (Speculative Execution), повышает скорость выполнения команд, "заглядывая вперед" текущей команды и выполняя последующие команды, которые, по всей вероятности, вскоре потребуются. Результаты этих команд сохраняются как результаты по предположению до тех пор, пока процессор не узнает, какие их них нужны, а какие нет. В этой точке команды преобразуются в обычный порядок и добавляются в поток команд программы.
У технологии динамического выполнения имеются два основных преимущества: команды выполняются
быстрее и эффективнее, чем обычно, и в отличие от процессоров, использующих RISC-архитектуру,
программы не нужно рекомпилировать, чтобы "выжать" максимум из процессора. Процессор выполняет
всю эту работу на лету.
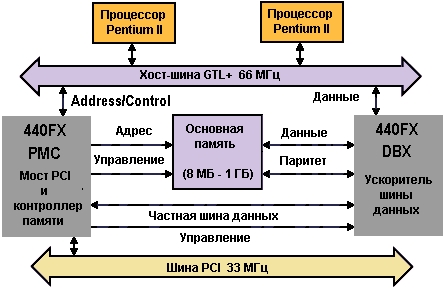
В процессоре Pentium II применяется основная шина gunning-transceiver-logic (GTL+), которая обеспечивает поддержку двух процессоров. Во время выпуска процессора этот прием позволил разрабатывать экономичные двухпроцессорные системы для симметричной мультиообработки (Symmetric MultiProcessing - SMP). Ограничение двумя процессорами диктовалось не самим Pentium II, а поддерживающим чипсетом. Однако и поддержка чипсетом двухпроцессорной конфигурации позволила фирме Intel и поставщикам рабочих станций быстрее и экономичнее разрабатывать двухпроцессорные системы. Ограничение двумя процессорами было преодолено в середине 1998 г., когда был выпущен чипсет 450NX, поддерживающий от одного до четырех процессоров. Чипсет 440FX, состоящий из микросхем PMC и DBX, не обеспечивал расслоения памяти, но поддерживал память EDO DRAM с повышенной производительностью.
При разработке процессора Pentium II фирма Intel постаралась устранить плохую 16-битовую производительность его предшественника. Процессор Pentium великолепно выполняет полностью 32-битовые приложения, например Windows NT, но уступает даже стандартному Pentium при выполнении 16-битового кода, например Windows 95, большие части которой оставались 16-битовыми. Фирма Intel решила эту проблему, используя в процессоре Pentium II кэш дескрипторов сегментов процессора Pentium.
Как и Pentium Pro, процессор Pentium II очень быстро выполняет арифметику с плавающей точкой.
Это обстоятельство совместно ускоренным графическим портом (Accelerated Graphics Port - AGP)
позволяет достичь высокой производительности в приложениях трехмерной графики.
Картридж SEC

Конструктив картриджа с одним краевым разъемом (Single Edge Contact cartridge - SEC) процессора Pentium II позволяет разместить ядро и L2-кэш в пластиковом и металлическом картридже. Эти субкомпоненты по технологии поверхностного монтажа размещаются прямо на подложке, что обеспечивает работу на высокой частоте. Картридж позволяет использовать для L2-кэша широко распространенные кристаллы памяти пакетных SRAM (Burst SRAM), что снижает стоимость процессора.
На подложке картриджа SEC находятся шесть отдельных устройств: процессор, четыре микросхемы
статических пакетных RAM и и одна тэговая память RAM. Картридж SEC обеспечивает также важные
конструктивные преимущества. Корпус PGA процессора Pentium Pro имеет 387 штырьков, а картридж
SEC использует только 242 контакта. Такте уменьшение числа контактов на треть объясняется тем,
что картридж SEC содержит такие дискретные компоненты, как резисторы-терминаторы и конденсаторы.
Эти компоненты обеспечивают развязку сигналов, поэтому требуется намного меньше контактов
питания. Слот для картриджа SEC называется Slot 1 и обычно он размещается там, где находился
прежний сокет Socket 7.
Архитектура сдвоенной независимой шины
Архитектура сдвоенной независимой шины (Dual Independent Bus - DIB), впервые реализованная в процессоре Pentium Pro, была разработана для повышения пропускной способности шины процессора. Наличие двух независимых шин позволяет процессору Pentium II обращаться к данным по обеим шинам независимо и параллельно, а не последовательно, как в системе с одной шиной.
Процессор выполняет операции считывания и записи данных в L2-кэше, используя специальную скоростную шину. Эта шина, называемая задней шиной (BackSide Bus - BSB), отделена от шины процессора и основной памяти, которая стала называться передней шиной (FrontSide Bus - FSB). Архитектура DIB позволяет процессору использовать обе шины одновременно, что обеспечивает и другие преимущества.
Несмотря на то, что шина между процессором и L2-кэшем работает медленнее, чем в обычном процессоре Pentium Pro (с половиной частоты синхронизации процессора), она оказывается масштабируемой. Если процессор работает быстрее, так же быстрее работает и L2-кэш независимо от передней шины. Кроме того, скорость передней шины можно повышать, не влияя на шину L2-кэша. Размещение L2-кэша на одном и том же кристалле с процессором ухудшало коэффициент выхода процессоров Pentium Pro с памятью 512 КБ, что вынуждало повышать его стоимость. Конвейерная передняя шина допускает также выполнение нескольких транзакций одновременно (вместо последовательных транзакций), ускоряя передачи информации в системе и повышая этим общую производительность.
Все улучшения архитектуры DIB обеспечивают трехкратное повышение пропускной способности по
сравнению с одношинной архитектурой, а также поддерживают переход к системной шине с частотой
100 МГц.
Процессор Deschutes
В начале 1998 г. была объявлена разновидность 333 МГц Pentium II с кодовым именем Deschutes. Начальная рабочая частота составляла 400 МГц, а впоследствии она была повышена. Фактически название Deschutes относится к двум разным процессорам.
Версия для Slot 1 представляла собой несколько улучшенный процессор Pentium II. Архитектурные и физические принципы идентичны, но процессор Deschutes Slot 1 выпускался по технологии 0.25 мкм, которую фирма Intel освоила осенью 1997 г. при выпуске процессора Tillamook для портативных компьютеров, а не технология 0.35 мкм, которая использовалась для процессоров с частотой от 233 МГц до 300 МГц. Переход на технологию 0.25 мкм позволил снизить потребляемую мощность и уменьшить выделение тепла, а это допускает работу ядра на более высокой частоте.
Все остальное в процессоре Slot 1 Deschutes аналогично обычному процессору Pentium II. Он поддерживает систему команд MMX и взаимодействует с L2-кэшем емкостью 512 КБ с половинной частотой ядра. Процессор имеет такой же разъем и работает на тех же материнских платах с теми же чипсетами. Он мог работать с чипсетами 440FX или 440LX при частоте внешней шины 66 МГц.
В начале 1998 г. достигнуто более значительное повышение производительности в следующей версии процессора Deschutes, когда новый чипсет 440BX обеспечил работу с системной шиной на частоте 100 МГц. К началу 1999 г. самый быстрый процессор Pentium II работал на частоте 450 МГц.
Вторым процессором, к которому относится название Deschutes, была версия для Slot 2, которая была выпущена в середине 1998 г. как процессор Pentium II Xeon. Фирма Intel организовала выпуск процессоров Slot 1 и Slot 2 Deschutes, ориентируясь на Slot 1 для массового производства и на Slot 2 для мощных серверов, где стоимость имеет вторичное значение по сравнению с производительностью.
В следующей таблице приведены разновидности процессора Pentium II от момента его выпуска в 1997 г. до появления процессора Pentium Xeon:
| Дата | Кодовое имя | Транзисторы | Технология (мкм) | Скорость (МГц) |
| 1997 г. | Klamath | 7 500 000 | 0.28 | 233/266/300 |
| 1998 г. | Deschutes | 4 500 000 | 0.25 | 333/350/400 |
Процессор Celeron
В попытке освоения рынка дешевых РС, занятого компаниями AMD и Cyrix, которые продолжали продвигать устаревшую архитектуру Socket 7, фирма Intel в апреле 1998 г. выпустила семейство процессоров Celeron.
Основанные на той же микроархитектуре P6, как и процессор Pentium II, и производимые по технологии 0.25 мкм, процессоры Celeron обладали полным комплектом новейших технологий, включая поддержку графики AGP, накопителей на жестких дисках ATA-33, памяти SDRAM и спецификации экономии мощности ACPI. Процессор Celeron работает с любым чипсетом для Pentium II, который поддерживает системную шину 66 МГц, включая 440LX, 440BX и новый чипсет 440EX, который специально разработан для рынка "Базового РС". В отличие от Pentium II в корпусе SEC процессор Celeron не имеет защитного пластикового чехла вокруг процессорной карты, который фирма Intel называет корпус процессора с одним краевым разъемом (Single Edge Processor Package - SEPP). Он совместим с разъемом Slot 1, позволяя использовать существующие материнские платы, но механизм фиксации карты процессора необходимо адаптировать для форм-фактора SEPP.
Первые процессоры Celeron на частоты 266 МГц и 300 МГц без L2-кэша были встречены более
чем прохладно, так как не обеспечивали серьезных преимуществ по сравнению с системами для
Socket 7. В августе 1998 г. фирма Intel улучшила процессоры Celeron семейством, которое ранее
имело кодовое имя Mendocino. Начиная с модели 300A, все процессоры Celeron имеют на кристалле
L2-кэш емкостью 128 КБ, который работает с полной скоростью процессора и взаимодействует с
"внешним миром" по шине 66 МГц. Это значительно повысило производительность новых процессоров
Celeron по сравнению с их предшественниками.

Все процессоры Celeron с модели 300A до частоты 466 МГц выпускались в двух версиях - с форм-фактором SEPP и пластиковом корпусе с матрицей штырьковых выводов (Plastic Pin Grid Array - PPGA). Первые из них совместимы с архитектурой Slot 1, а вторые должны размещаться в специальном сокете PGA370, который не совместим с Socket 7 и Slot 1 (см. рисунок слева). Использование сокета вместо слота предоставляет разработчикам материнских плат больше свободы, так как сокет занимает меньше места и лучше рассеивает тепло. Версия процессора на 500 МГц выпускалась только в корпусе PPGA.
Весной 2000 г. ситуация с корпусами еще более запуталась в связи с появлением первых процессоров Celeron, произведенных по технологии 0.18 мкм. Для этих процессоров был разработан дешевый корпус FC-PGA (flip-chip pin grid array), который означал снижение интереса к корпусам PPGA и Slot 1, так как последующие процессоры Pentium III также выпускались под форм-фактор FC-PGA. Материнские платы с 370-контактным сокетом не поддерживают процессор Pentium III с форм-фактором FC-PGA. Процессоры Pentium III в корпусе FC-PGA имеют два контакта RESET и требуют соответствия спецификации VRM 8.4. Существующие материнские платы считаются RESET и VRM 8.4 называются гибкими (flexible) материнскими платами.
В следующей таблице приведены разновидности процессора Pentium II Celeron от момента его выпуска в 1998 г.:
| Дата | Кодовое имя | Транзисторы | Технология (мкм) | Скорость (МГц) |
| 1998 г. | Covington | 7 500 000 | 0.25 | 266/300 |
| 1998 г. | Mendocino | 19 000 000 | 0.25 | 300/333 |
| 1999 г. | Mendocino | 19 000 000 | 0.25 | От 366 до 500 |
| 2000 г. | Mendocino | 19 000 000 | 0.18 | От 566 до 700 |
Процессор Pentium II Xeon
В июне 1998 г. фирма Intel объявила о выпуске процессора Pentium II Xeon с рабочей частотой 400 МГц. В техническом смысле процессор Xeon представляет собой комбинацию процессоров Pentium Pro и Pentium II и обеспечивает очень высокую производительность в критических приложениях для рабочих станций и серверов. Он использует новый интерфейс Slot 2 и по размерам почти в два раза больше процессора Pentium II, в основном, за счет L2-кэша повышенной емкости. Система кэша аналогична кэшу процессора Pentium, что и объясняет высокую стоимость процессора Xeon. Кроме того, стандартной для всех процессоров Xeon стала память ECC SRAM. В начале выпуска процессор Xeon для рабочих станций имел L2-кэш емкостью 512 КБ, а для серверов - 1 МБ. Позже в 1999 г. был выпущен процессор Xeon с L2-кэшем емкостью 2 МБ.
Как и в процессорах Pentium II с рабочими частотами 350 МГц и 400 МГц, передняя шина
(FrontSide Bus - FSB) работает на частоте 100 МГц для повышения системной производительности.
Наиболее важным достижением по сравнению со стандартным процессором Pentium II было то, что
L2-кэш работает с такой же скоростью, как и ядро процессора, хотя конструкция Slot 1
ограничивает скорость L2-кэша половиной скорости ядра, позволяя использовать для L2-кэша
дешевую пакетную память, а не применять специальную память SRAM. Наличие намного более дорогого
L2-кэша стало основной причиной большой разности в стоимости систем для Slot 1 и Slot 2.

Slot 2 снимает и еще одно ограничение - предел сдвоенного-SMP (симметричный мультипроцессор - Symmetric MultiProcessor). Невозможность создания мультипроцессорных систем на базе Pentium II с более чем двумя процессорами была основной причиной того, что в мощных серверах, требующих мультипроцессорных конфигураций, применялся процессор Pentium Pro. Системы на базе процессора Pentium II Xeon можно конфигурировать с объединением от четырех до восьми процессоров.
Несмотря на то, что фирма Intel ориентировала процессор Xeon на оба рынка рабочих станций и серверов, она разработала для них различные чипсеты. Чипсет 440GX опирается на ядро чипсета 440BC и предназначен для рабочих станций. С другой стороны, чипсет был 450NX разработан специально для рынка серверов.
Следующая таблица показывает основные модификации процессора Pentium II Xeon с момента его выпуска в 1998 г.:
| Дата | Транзисторы | L2-кэш | Технология (мкм) | Скорость (МГц) |
| 1998 г. | 7 500 000 (PII) | 512 КБ/1 МБ | 0.25 | 400/450 |
| 1999 г. | 9 500 000 (PIII) | 2 МБ | 0.25 | 450 |
Процессор Pentium III

Преемник процессора Pentium II, который разрабатывался под кодовым именем Katmai, был выпущен весной 1999 г. С введением расширений MMX реализован новый процесс один поток команд - много потоков данных (Single Instruction Multiple Data - SIMD). Он позволяет одной команде выполнить одну и ту же функцию над несколькими элементами данных одновременно, что повышает скорость обработки наборов данных, требующих выполнения одних и тех же операций. В новом процессоре введено 70 новых потоковых расширений SIMD (Streaming SIMD Extensions) без других архитектурных усовершенствований.
Пятьдесят из новых расширений SIMD ориентированы на повышение производительности операций с плавающей точкой. Чтобы ускорить обработку данных, введено восемь новых 128-битовых регистров. Все нововведения привели к тому, что в каждом такте синхронизации процессора могут возвращаться до четырех результатов с плавающей точкой. Имеются также 12 команд New Media, которые дополняют существующие 57 целочисленных MMX-команд, обеспечивающих дальнейшую поддержку обработки мультимедийных данных. Остальные восемь команд фирма Intel называет командами новой кэшируемости New Cacheability. Они улучшают эффективность L1-кэша процессора и позволяют знающим программистам-профессионалам повысить производительность разрабатываемых приложений или игр.
Кроме рассмотренных архитектурных усовершенствований в процессоре Pentium III больше ничего не реализовано. Он по-прежнему рассчитан на материнские платы со слотом Slot 1 с более упрощенным конструктивом. Новый картридж SECC2 позволяет смонтировать теплоотвод прямо на карте процессора, а в корпусе используется меньше пластика. Процессор по-прежнему имел L1-кэш емкостью 32 КБ и вначале выпускался на рабочие частоты 450 МГц и 500 МГц, а частота передней шины составляла 100 МГц. L2-кэш емкостью 512 КБ работал с половинной скоростью процессора, как и в процессоре Pentium II. Это означает, что выигрыш в производительности по сравнению с Pentium II заметен только при выполнении приложений трехмерной графики или игр, которые написаны с использованием новых команд Streaming SIMD Extensions.
Вскоре после выпуска Pentium III появился процессор Pentium III Xeon, разрабатывавшийся под кодовым именем Tanner. Практически он представлял собой процессор Pentium Xeon с добавленными новыми командами Streaming SIMD Extensions. Процессор Pentium III Xeon был ориентирован на рынок серверов и рабочих станций и вначале выпускался с рабочей частотой 500 МГц и имел L2-кэш емкостью 512 КБ, 1 МБ или 2 МБ.
В октябре 1999 г. были выпущены процессоры Pentium III под кодовым именем Coppermine, которые производились по технологии 0.18 мкм. Переход на эту технологию позволил уменьшить размеры кристалла, снизить напряжение питания и повысить рабочую частоту до 1 ГГц и более. Выпускалось две модели процессоров, рассчитанные на частоту передней шины 100 МГц и 133 МГц. Частота синхронизации процессоров составляла 500 МГц и 700 МГц.
Несмотря на то, что емкость L2-кэша Pentium III была уменьшена до 256 КБ, он размещался на кристалле процессора и работал с полной скоростью процессора. Новый кэш фирма Intel назвала кэшем с улучшенной передачей (Advanced Transfer Cache - ATC). Практически это означает, что кэш соединен с процессором 256-битовой шиной, которая в четыре раза шире 64-битовой шины процессора Katmai. Общая производительность системы повышена также применением технологии улучшенного системного буферирования (Advanced System Buffering - ASB), которая увеличивает число буферов между процессором и системной шиной.
Весной 2000 г. были выпущены процессоры Pentium III на рабочие частоты 850 МГц и 866 МГц, которые производились в корпусах SECC2 и FC-PGA.
В следующей таблице приведены разновидности процессора Pentium III:
| Дата | Кодовое имя | Транзисторы | L2-кэш | Технология (мкм) | Скорость (МГц) |
| 1999 г. | Katmai | 9 500 000 | 512 КБ | 0.25 | 450/500/550 |
| 1999 г. | Tanner | 9 500 000 | 512 КБ/1 МБ/2 МБ | 0.25 | 500/550 |
| 1999 г. | Coppermine | 28 100 000 | 256 КБ (на кристалле) | 0.18 | 500 - 800 |
| 2000 г. | Coppermine | 28 100 000 | 256 КБ (на кристалле) | 0.18 | 850 - 1130 |
В июле 2000 г. фирма Intel была вынуждена отозвать все поставленные процессоры с рабочей
частотой 1.13 ГГц после того, как было обнаружено, что при выполнении некоторых приложений
они вызывали зависание системы. Многие специалисты считали, что это вызвано конкуренцией с
компанией AMD, которая превзошла барьер в 1 ГГц на несколько недель раньше, и что первоначальные
планы фирмы Intel по выпуску все более быстрых процессоров будут отодвинуты.
Процессор Itanium
Еще в 1994 г. фирмы Intel и Hewlett-Packard объявили о своих совместных планах разработать к концу тысячелетия мощный процессор для рабочих станций и серверов, а в 1997 г. опубликовали подробности архитектуры 64-битового компьютера. В то время выпуск первого процессора нового 64-битового процессора под кодовым именем Merced планировался на 1999 г. с использованием технологии 0.18 мкм. Программа разработки Merced продвигалась с опозданием почти на год и в октябре 1999 г. фирма Intel объявила о выборе для процессора нового имени Itanium.
Основным преимуществом 64-битовой архитектуры является емкость адресуемой памяти. В середине 80-х годов прошлого века адресуемой памяти 4 ГБ в 32-битовых процессорах было более чем достаточно. Однако в конце тысячелетия огромные базы данных превысили этот предел. Время на обращение к запоминающим устройствам и загрузку данных в виртуальную память стало сильно влиять на производительность. 64-битовый процессор может адресовать память емкостью 16 ТБ, что в 4 млрд раз больше по сравнению с 32-битовым процессором. Однако наряду с расширением адресуемой памяти важнейшим технологическим достижением процессора Itanium является явно параллельное выполнение команд (Explicitly Parallel Instruction Computing - EPIC), служащее основой новой 64-битовой архитектуры системы команд (Instruction Set Architecture - ISA).
Технология EPIC, включающая в себя новационное объединение рискованного выполнения, предсказания и явного параллелизма, улучшает современные технологии процессоров, преодолевая характерные для RISC- и CISC-технологий ограничения. Несмотря на то, что обе эти технологии используют разнообразные внутренние приемы выполнения более одной команды там, где это возможно, степень параллелизма в коде определяется только во время выполнения компонентами процессора, которые пытаются проанализировать и переупорядочить команды на лету. При таком подходе требуется время и расходуется площадь кристалла, которые можно было бы использовать на выполнение, а не на организацию команд. Технология EPIC превосходит последовательную природу обычных архитектур процессоров, позволяя программе явно взаимодействовать с процессором, когда операции можно выполнять параллельно.
В результате процессор может просто "захватить" максимально большой блок команд и выполнять их одновременно с минимальной предварительной обработкой. Повышенная производительность достигается сокращением числа разветвлений и неверных предсказаний разветвлений, а также уменьшением задержек ожидания процессором памяти. Архитектура системы команд (Instruction Set Architecture - ISA) IA-64, опубликованная в мае 1999 г. привлекает технологию EPIC для доставки множества ресурсов с присущей масштабируемостью, что было невозможно в архитектурах предыдущих процессоров. Например, можно спроектировать системы, в которые можно вставлять новые операционные устройства там, где требуется модернизация, аналогично вставке дополнительных модулей памяти в существующих системах. По мнению специалистов фирмы Intel архитектура IA-64 ISA представляет собой самое значительное усовершенствование в архитектуре микропроцессоров с момента выпуска процессора 386 в 1985 г.
Процессоры IA-64 будут иметь мощные вычислительные ресурсы, включающие в себя 129 целочисленных регистров, 128 регистров с плавающей точкой и 64 регистра предикации, а также множество регистров специального назначения. Команды будут объединяться в группы для параллельного выполнения различными функциональными устройствами. Система команд оптимизирована на решение задач криптографии, кодирования видео и другие функции, которые все больше требуются в серверах и рабочих станциях следующего поколения. В процессорах IA-64 реализуется и расширяется поддержка технологии MMX и Internet Streaming SIMD Extensions.
Несмотря на то, что IA-64 не является ни 64-битовой версией 32-битовой архитектуры x86 фирмы Intel, ни адаптацией 64-битовой архитектуры PA-RISC компании Hewlett-Packard, она обеспечивает защиту вложений в современные существующие приложения и программную инфраструктуру, обеспечивая совместимость с первыми в аппаратных средствах процессора и со вторыми с помощью преобразования программ. Однако одним из следствий IA-64 является та степень, с которой компиляторы смогут оптимизировать командные потоки, - возможно, старые программы не будут выполняться с оптимальной скоростью без рекомпилирования. Способ обработки 32-битовых программ в IA-64 вызвал критику компании AMD, которая имеет собственные предложения по поддержке 64-битовых кода и адресации памяти под кодовым именем Sledgehammer и эти предложения не накладывают ограничений на старые программы.
Далее рисунки показывают повышенную нагрузку на оптимизацию компилятором двух новых возможностей IA-64:
- Предикация (predication), которая заменяет предсказание разветвления, позволяя процессору выполнять все возможные пути разветвления параллельно.
- Рискованная загрузка (speculative loading), которая позволяет процессорам IA-64 считывать данные до того, как они потребуются программе, даже после разветвления, которое не выполнялось.
Предикация является главным средством архитектуры IA-64 для устранения разветвлений и параллельного
планирования команд. Обычно компилятор преобразует оператор разветвления исходного кода, например
IF-THEN-ELSE, в альтернативные блоки машинного кода, выстроенные в последовательный поток. В
зависимости от результата разветвления процессор будет выполнять один их этих базовых
блоков, переходя ("прыгая" через другие). Современные процессоры пытаются предсказать результат
разветвления и с опережением ("рискованно") выполнить целевой блок, что при неправильном
предположении приводит к потере многих тактов. Базовые блоки обычно небольшие, часто всего
две-три команды, а разветвления приходятся примерно на каждые шесть команд. Последовательная
природа такого кода затрудняет параллельное выполнение.
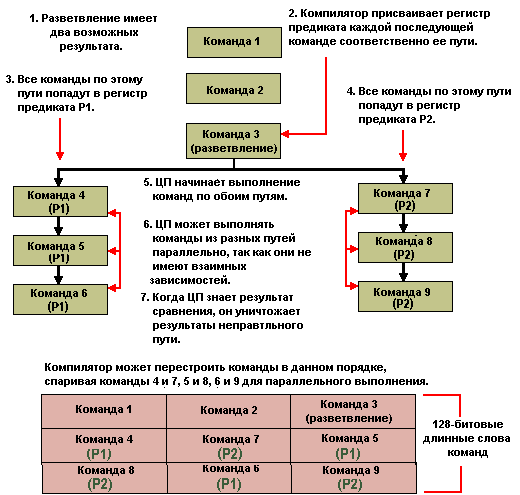
Когда компилятор IA-64 встречает в исходном коде оператор разветвления, он анализирует его, проверяя, имеется ли другой кандидат для предикции, и отмечая все команды, представляющие собой каждый путь в разветвлении уникальным идентификатором, который называется предикатом (predicate). После отметки команд предикатами компилятор определяет, какие команды процессор может выполнить параллельно, например спаривая команды из разных результатов разветвления, так как они представляют независимые пути в программе.
Затем компилятор собирает команды машинного кода в 128-битовые блоки (связки - bundles) по три команды в каждом. Поле шаблона в блоке не только идентифицирует, какие команды в блоке можно выполнять независимо, но также и то, какие команды в следующих блоках являются независимыми. Поэтому если компилятор обнаруживает 16 команд, не имеющих взаимных зависимостей, он может упаковать их в шесть разных блоков (по три в первых пяти блоках и одна в шестом) и отметить их в шаблонах. Во время выполнения процессор сканирует шаблоны, выбирает команды, не имеющие взаимных зависимостей, а затем диспетчирует их параллельно функциональным устройствам. Затем процессор планирует команды, являющиеся зависимыми, в соответствии с их требованиями.
Когда процессор встречает предикатное разветвление, он не пытается предсказать, по какому пути произойдет разветвление, и не переходит через блоки кода для рискованного выполнения предсказанного пути. Вместо этого процессор начинает выполнение кода для каждого возможного результата разветвления. По существу, на машинном уровне разветвления нет. Имеется только один неразрывный поток кода, который компилятор должен перестроить в максимально параллельном порядке.
Конечно, в некоторой точке процессор, в конце концов, выполнит операцию сравнения, которая соответствует оператору IF-THEN. К этому моменту процессор, вероятно, выполнил некоторые команды из обоих возможных путей - но пока не сохранял результаты. Только в этой точке процессор и осуществляет это, сохраняя результаты из правильного пути, и уничтожая результаты от неверного пути.
Рискованная загрузка пытается отделить загрузку от использования этих данных, пытаясь этим
избежать ситуаций, когда процессор должен ожидать данных до их обработки. Как и предсказание,
фактически это представляет собой комбинацию оптимизаций времени компилирования и времени
выполнения.
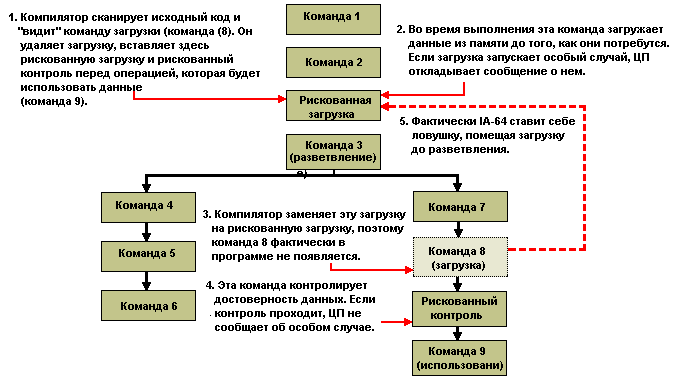
Во-первых, компилятор анализирует программный код, отыскивая любые команды, которые потребуют данные из памяти. При возможности компилятор вставляет команду рискованной загрузки в ранней точке командного потока задолго до той операции, которой действительно потребуются данные. Он также вставляет соответствующую рискованную команду контроля непосредственно перед рассматриваемой операцией. Одновременно компилятор перестраивает соседние команды таким образом, чтобы процессор мог диспетчировать их параллельно.
Во время выполнения процессор первой встречает команду рискованной загрузки и пытается считать данные из памяти. Именно в этом процессор IA-64 отличается от обычного процессора. Иногда загрузка окажется неправильной - она может принадлежать блоку кода за разветвлением, которое пока не выполнено. Традиционный процессор немедленно запускает особый случай и, если программа не может обработать особый случай, по всей вероятности, возникает авария (crash). Однако процессор IA-64 не должен немедленно сообщать об особом случае, если загрузка оказалась недостоверной. Вместо этого процессор откладывает особый случай до встречи рискованной команды контроля, которая соответствует рискованной загрузке. Только после этого процессор сообщает об особом случае. Однако к этому времени процессор определился с разветвлением, которое и привело к особому случаю. Если путь, к которому принадлежит загрузка, исключает недостоверность, то загрузка недостоверна и поэтому процессор сообщает об особом случае. Но если загрузка достоверна, особый случай не регистрируется.
В августе 1999 г. прототип процессора Merced, выполненный по технологии 0.18 мкм и работающий
на частоте 800 МГц, продемонстрировал возможность работы с первой 64-битовой версией
операционной системы Windows. При массовом выпуске процессоров Itanium будет использоваться
архитектура трехуровневого кэша, причем кэши двух уровней будут размещаться на кристалле,
а внешний L3-кэш будет подключен к шине, обеспечивающей полную скорость. Первые производственные
модели будут иметь L3-кэш емкостью 2 МБ или 4 МБ, а начальная рабочая частота составит 800
МГц, а затем будет повышена до 1 ГГц и более.
Процессор Pentium 4
В начале 2000 г. фирма Intel объявила подробные сведения о первом новом ядре архитектуры IA-32, разработанном после процессора Pentium Pro, который был выпущен в 1995 г. Новый процессор создавался под кодовым именем Willamette и был объявлен под именем Pentium 4 через несколько месяцев после поставки нового поколения процессоров; этот процессор ориентирован на рынок мощных настольных РС, а не на рынок серверов.
Повышение производительности Pentium 4 было достигнуто, в основном, благодаря архитектурным усовершенствованиям, которые позволили процессору работать на более высоких скоростях, и логическим изменениям, которые позволили выполнять больше команд на такт синхронизации. Самой важной новинкой стал внутренний конвейер процессора Pentium 4 (он называется Hyper Pipeline), которые имеет 20 ступеней вместо десяти ступеней микроархитектуры P6.
Типичный конвейер имеет фиксированный объем работы, которая требуется для декодирования и выполнения команды. Эта работа выполняется отдельными логическими элементами (gates). Каждый логический элемент состоит из нескольких транзисторов. При увеличении числа ступеней в конвейере для каждой ступени требуется меньше элементов. Поскольку каждому элементу требуется определенное время для формирования результата (задержка распространения), уменьшение числа элементов в каждой ступени позволяет повысить частоту синхронизации. Это позволяет большему числу команд находиться в конвейере на различных этапах декодирования и выполнения. Несмотря на то, что эти преимущества несколько ухудшаются необходимостью введения дополнительных служебных элементов для управления добавленными ступенями, общий эффект увеличения числа ступеней в конвейере приводит к уменьшению числа элементов в ступени, а это позволяет повысить рабочую частоту ядра.
В абсолютных терминах максимальная частота, которую может достичь конвейер с учетом времени работы одной ступени и числа ступеней, равна:
макс. частота = 1/(время ступени в нс/число ступеней) * 1000 (в МГц)
Например, максимальная частота, достижимая в 5-ступенчатом конвейере с временем работы одной ступени 10 нс составляет 1/(10/5) * 1000 = 500 МГц.
С другой стороны, 15-ступенчатый конвейер с временем работы ступени 12 нс обеспечивает максимальную частоту 1/(12/15) * 1000 = 1250 МГц или 1.25 ГГц.
Для дополнительного повышения частоты необходимо снижать время работы каждой ступени, что требует совершенствования технологии, и/или увеличивать число ступеней.
Отметим также и другие новинки, реализованные в новой микроархитектуре процессора Pentium 4, которую обычно называют NetBurst:
- Новая реализация L1-кэша, который наряду с кэшем данных емкостью 8 КБ имеет кэш слежения за выполнением (Execution Trace Cache), который содержит 12 000 декодированных команд x86 (микроопераций). Наличие этого кэша устраняет из основных циклов выполнения задержку, вызываемую декодером команд.
- Быстрая машина выполнения (Rapid Execution Engine), которая обеспечивает работу ALU процессора на удвоенной частоте ядра, что повышает скорость выполнения операций. Процессор фактически использует три частоты синхронизации: частота ядра, частота ALU и частота шины.
- Очень глубокая машина рискованного выполнения (speculative execution engine), которая называется улучшенной машиной динамического выполнения (Advanced Dynamic Execution engine). Она позволяет избежать простоев, которые могут возникать из-за ожидания командами устранения зависимостей, обеспечивая очень большое окно команд, из которых могут выбирать операционные устройства.
- L2-кэш с улучшенной передачей (Advanced Transfer Cache) емкостью 256 КБ, предоставляющий 256-битовый (32-байтовый) интерфейс. Данные по этому интерфейсу передаются в каждом такте ядра, обеспечивая канал с очень высокой пропускной способностью. Например, в процессоре Pentium 4 с рабочей частотой 1.4 ГГц пропускная способность составляет 44.8 ГБ/с (32 байта * 1 передача данных в такте * 1.4 ГГц).
- Streaming SIMD Extensions 2 (SSE2) - новейшая разработка технологии один поток команд - много потоков данных (Single Instruction Multiple Data - SIMD). В этой технологии интегрированы 76 новых SIMD-команд и усовершенствованы 68 целочисленных SIMD-команд, что позволяет процессору одновременно обрабатывать 128 битов данных в операциях с плавающий точкой и целочисленных операциях. Этот ускоряет выполнение сложных операций кодирования и декодирования, например потокового видео, речи, трехмерного приведения и других мультимедийных процедур.
- Первая системная шина на 400 МГц, которая обеспечивает трехкратное повышение производительности по сравнению с современной шиной 133 МГц.
Производимый по хорошо освоенной технологии 0.18 мкм новый процессор содержит 42 млн транзисторов. Однако для первоначальной схемы процессора требовался слишком большой кристалл, который было неэкономично производить по технологии 0.18 мкм. Поэтому из оригинальной схемы процессора Willamette были удалены такие компоненты, как больший L1-кэш, два полномасштабных устройства с плавающей точкой FPU и внешний L3-кэш емкостью 1 МБ. Это говорит о том, что для процессора Pentium 4 фактически требуется технология 0.13 мкм, которую фирма Intel планирует освоить в 2001 г.
В ноябре 2000 г. начались первые поставки процессора Pentium 4 с рабочими частотами 1.4 ГГц и 1.5 ГГц. Сообщалось, что новый процессор значительно производительнее прежних процессоров в приложениях трехмерной графики, например в играх, и кодировании видео. В повседневных офисных приложениях, например при обработке текстов, работе с электронными таблицами, "блуждании" по Web, выигрыш в производительности гораздо меньше.
На первую половину 2001 г. планируется выпуск процессора Pentium 4 с рабочей частотой
1.7 ГГц, а к середине этого года должен появиться процессор с рабочей частотой 2 ГГц.
Медные межсоединения
Каждая микросхема процессора имеет базовый слой транзисторов, поверх которых располагаются слои межсоединений для соединения транзисторов между собой и, в конце концов, с остальными компонентами компьютера. Транзисторы на первом уровне микросхемы представляют собой очень сложное и точное образование из кремния, металла и примесей, которое образует миллионы крошечных переключателей "вкл-выкл", составляющих "мозг" процессора. Крупные технологические достижения наиболее часто связаны с формированием транзисторов. По мере формирования все более быстрых и малых транзисторов, располагаемых все более ближе друг к другу, возникают проблемы межсоединений.
Очень долгое время проводником служил алюминий, но в современных технологиях стали
сказываться технологические и физические ограничения алюминия. Стало труднее "проталкивать"
электроны по все более меньшим и меньшим проводникам - алюминий просто обладает недостаточной
электропроводностью для этого. За годы исследований ученые нашли три металла, которые проводят
электричество лучше и могут заменить алюминий - медь, серебро и золото. Однако до недавнего
времени не удавалось выпускать микросхемы с медными межсоединениями.
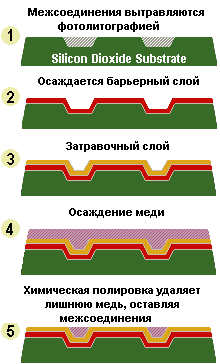
Ситуация изменилась в сентябре 1998 г., когда компания IBM использовала свою революционную технологию медных межсоединений для выпуска микросхемы, в которой для соединения транзисторов применялись медные проводники, а не традиционные алюминиевые межсоединения. Это, на первый взгляд, незначительное изменение должно оказать значительное влияние на разработку и производство процессоров. Медные межсоединения обещают уменьшить размеры кристаллов и снизить потребляемую мощность, позволяя создать более быстрые процессоры даже при одной и той же базовой схеме.
В 1999 г. компания IBM предложила лицензировать технологический процесс 7SF с медными межсоединениями производителям микросхем.
Одной из проблем, которая делала безуспешными прежние попытки использовать медь для электрических межсоединений, была диффузия меди в подложку из двуокиси кремния, что приводило к тому, что кристалл становился бесполезным. Секрет новой технологии компании IBM заключается в тонком барьерном слое, который обычно состоит из очищенного титана или нитрида вольфрама. Этот слой наносится после фотолитографического травления каналов в подложке. Поверх барьерного слоя осаждается микроскопический затравочный слой, а затем на весь кристалл наносится слой меди, который приклеивается к затравочному слою. Излишняя медь удаляется с помощью химической полировки.
Несмотря на то, что компании IBM и Motorola освоили производство микросхем с медными
межсоединениями в 1999 г., фирма Intel решила не переходить на них до выпуска своего первого
процессора по технологии 0.13 мкм, который ожидается не раньше 2002 г.
Перспективы
В следующей таблице представлены перспективные процессоры, разрабатываемые фирмой Intel:
| 2001 г. | 2002 г. | 2003 г. | |
| IA-64 | |||
| McKinley - 0.13 мкм, кэш 2 МБ на кристалле | 1/1.6 ГГц | ||
| Madison - 0.13 мкм, медные межсоединения | > 1 ГГц | ||
| Deerfield - IA-64 для серверов и рабочих станций | > 1 ГГц |
Приведем некоторые дополнительные сведения об этих процессорах:
- McKinley: Преемник Merced будет производиться по технологии 0.13 мкм с использованием медных межсоединений и выпуск планируется на конец 2001 г. Рабочая частота составит 1 ГГЦ. Процессор McKinley должен удвоить производительность процессора Merced благодаря усовершенствованию микроархитектуры и использованию "очень больших" внутренних кэшей. В нем будет реализовано надмножество шины процессора Merced с целью трехкратного повышения полосы пропускания.
- Madison: Преемник процессора McKinley представляет собой процессор, производимый по технологии 0.13 мкм с использованием медных межсоединений. Будет иметь большой L3-кэш.
- Deerfield: Процессор с архитектурой IA-64, предназначенный для серверов и рабочих станций.
