Урок 13
Представление текстов в памяти компьютера. Кодировочные таблицы
§13. Тексты в компьютерной памяти
Основные темы параграфа:
- преимущества компьютерного документа по сравнению с бумажным;
- как представляются тексты в памяти компьютера;
- что такое гипертекст.
Изучаемые вопросы:
- Преимущества компьютерного хранения документов.
- Кодировочная таблица, международный стандарт ASCII.
- Текстовые файлы
- Понятие гипертекста.
Преимущества компьютерного документа по сравнению с бумажным
А теперь от обсуждения вопроса о том, что представляет собой компьютер, перейдем к ответу на вопрос, что умеет делать компьютер. Начиная с этой главы, мы будем знакомиться с применением компьютеров.
Первая область применения, которую мы рассмотрим, — работа с текстами. При ручной записи часто неприятную проблему составляет необходимость исправлять ошибки или вносить какие-то изменения в текст. При этом приходится зачеркивать, стирать, заклеивать, что портит вид текста. Необходимость переписывать текст ведет к потере времени и лишнему расходу бумаги.
Имея компьютер, можно создавать тексты, не тратя на это лишнее время и бумагу. Носителем текста становится память компьютера. Конечно, для длительного его сохранения это должна быть внешняя память.
 Тексты на внешних носителях сохраняются в файлах.
Тексты на внешних носителях сохраняются в файлах.
Есть еще ряд преимуществ сохранения текстов в файлах на компьютерных носителях по сравнению с бумагой.
Во-первых, это компактное размещение. Например, на компакт-диске (700 Мб) можно разместить тексты более сотни книг объемом в 500 страниц каждая. А если использовать специальные методы сжатия, то это количество можно увеличить в несколько раз.
Во-вторых, если данный текст становится ненужным, то с помощью компьютера его легко удалить с носителя, поместив на это место другой файл.
В-третьих, с помощью компьютера легко скопировать файлы в любом количестве на другие носители.
В-четвертых, файл с текстом можно быстро переслать другому человеку по электронной почте. Для этого ваш компьютер и компьютер адресата должны иметь связь через компьютерную сеть.
Главное неудобство хранения текстов в файлах состоит в том, что прочитать их можно только с помощью компьютера. Человек может просмотреть текст на экране монитора или напечатать на бумаге, используя принтер.
Уже сейчас существуют издания, которые не печатаются на бумаге, а хранятся и распространяются в форме файлов. С распространением компьютеров число таких безбумажных изданий с каждым годом увеличивается. Представьте себе, что вся ваша личная библиотека разместится в коробке с дисками. Причем по объему информации она будет не меньше, чем сотни книг, собранных родителями. А экономя бумагу, Д1Ы сохраняем леса на нашей планете.
Как представляются тексты в памяти компьютера
А теперь «заглянем» в память компьютера и разберемся, как же представлена в нем текстовая информация.
Текстовая информация состоит из символов: букв, цифр, знаков препинания, скобок и др. Мы уже говорили, что множество всех символов, с помощью которых записывается текст, называется алфавитом, а число символов в алфавите — его мощностью.
Широко распространенным способом представления текстовой информации в компьютере является использование алфавита мощностью 256 символов. Один символ такого алфавита несет 8 битов информации: 28 = 256. 8 битов = 1 байт, следовательно (см. § 6):
Двоичный код каждого символа занимает 1 байт памяти компьютера.
Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие тому или иному символу. (Понятно, что это дело условное, можно придумать множество способов кодирования.)
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код — порядковый номер символа в двоичной системе счисления.
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
На ЭВМ первых поколений для разных типов машин использовались различные таблицы кодировки. С распространением персональных компьютеров типа IBM PC международным стандартом стала таблица кодировки под названием ASCII (American Standart Code for Information Interchange — американский стандартный код для обмена информацией). Точнее говоря, стандартной в этой таблице является только первая половина, т. е. символы с номерами от нуля (двоичный код 00000000) до 127(01111111). Сюда входят буквы латинского алфавита, цифры, знаки препинания, скобки и некоторые другие символы. Остальные 128 кодов, ОТ 10000000 до 11111111, составляют так называемую кодовую страницу. Например, кодовая страница номер 1251 (СР1251) содержит русский алфавит и используется в операционной системе Windows и ее приложениях. Таблицу кодировки, используемую в Windows, называют ANSI (American National Standart Institute -^Американский национальный институт стандартов). Первые половины таблиц ASCII и ANSI полностью совпадают.
В таблице 3.1 приведена стандартная часть кода ANSI (коды от 0 до 31 имеют особое назначение, не отражаются какими-либо знаками и в данную таблицу не включены). Здесь приведены десятичные номера символов, символы, двоичные коды.
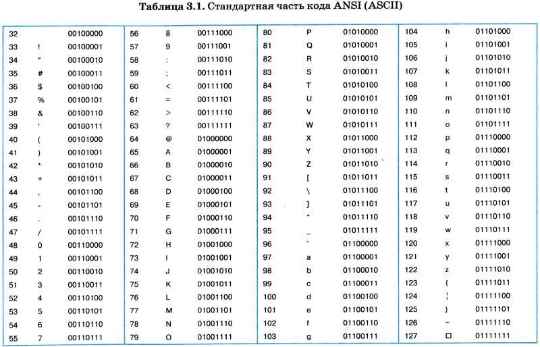
Обратите внимание на то, что в этой таблице латинские буквы (прописные и строчные) располагаются в алфавитном порядке. Расположение цифр также упорядочено по возрастанию значений. Это правило соблюдается и в других таблицах кодировки и называется принципом последовательного кодирования алфавитов. Благодаря этому понятие «алфавитный порядок» сохраняется и в машинном представлении символьной информации. Для русского алфавита принцип последовательного кодирования соблюдается не всегда.
Запишем, например, внутреннее представление слова «file». В памяти компьютера оно займет 4 байта со следующим содержанием:
01100110 01101001 01101100 01100101.
А теперь попробуйте решить обратную задачу. Какое слово записано следующим двоичным кодом:
01100100 01101001 01110011 01101011?
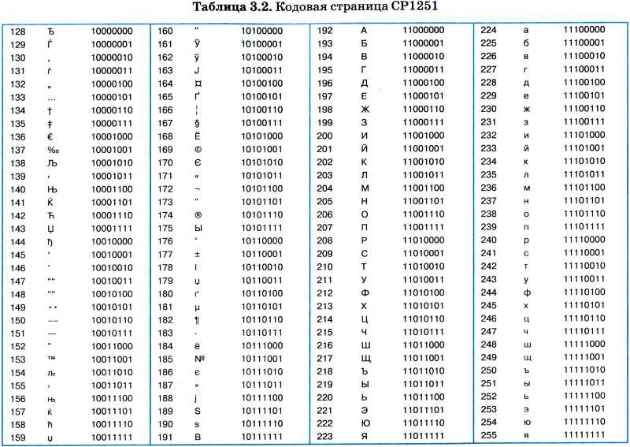
В таблице 3.2 приведена кодовая страница СР1251. Видно, что в ней для букв русского алфавита соблюдается принцип последовательного кодирования. Однако это правило действует не во всех существующих кодовых страницах с русским алфавитом.
Помимо восьмиразрядной кодировки символов все большее распространение получает шестнадцатиразрядная — двухбайтовая кодировка. Международный стандарт такой кодировки носит название UNICODE.
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в форме двоичного кода.
Из памяти компьютера текст может быть выведен на экран или на печать в символьной форме. Но для долговременного хранения его следует записать на внешний носитель в виде файла.
Что такое гипертекст
Наиболее существенное отличие компьютерного текста от бумажного вы почувствуете, если встретитесь с текстом, информация в котором организована по принципу гипертекста.
Гипертекст — это текст, организованный так, что его можно просматривать в последовательности смысловых связей между его отдельными фрагментами. Такие связи называются гиперсвязями (гиперссылками).
Чаще всего по принципу гипертекста организованы компьютерные справочники, энциклопедии, учебники. Такую «книгу» можно читать не только в обычном порядке, «листая страницы» на экране, но и перемещаясь по смысловым связям в произвольном порядке. Например, при изучении на уроке физики темы «Второй закон Ньютона» с помощью компьютерного учебника ученик прочитал определение закона «Сила равна произведению массы на ускорение». Ему захотелось вспомнить определение массы. Указав в тексте на слово «масса» (связанные понятия обычно выделяются цветом или подчеркиванием, а указывать на них удобно с помощью мыши), он быстро перейдет к разделу учебника, где рассказывается о массе тел. Прочитав определение «Масса — мера инертности тела», ученик может пожелать уточнить, что такое инертность. По гиперссылке он быстро выйдет на нужный раздел.
После такой экскурсии вглубь материала ученик может вернуться в исходную точку, щелкнув мышью на кнопке «Назад», так как система запоминает весь маршрут продвижения по гиперссылкам.
Коротко о главном
С помощью компьютера можно создавать текстовые документы и хранить их на носителях внешней памяти в виде файлов.
Преимущества файлового хранения текстов: возможность редактирования, быстрого копирования на другие носители, передачи текста по линиям компьютерной связи.
Для кодирования текстов используется 8-разрядный или 16-разрядный двоичный код. При 8-разрядном кодировании используемый алфавит содержит 256 символов.
В таблице кодировки каждому символу алфавита поставлен в соответствие порядковый номер и восьмиразрядный двоичный код. ANSI — международный стандарт кодирования символов, используемый в операционной системе Windows.
Гипертекст — это текст, организованный так, что его можно просматривать в последовательности смысловых связей между его отдельными фрагментами. Такие связи называются гиперсвязями (гиперссылками). Гиперссылка позволяет быстро перейти к просмотру того раздела, на который она указывает.
Вопросы и задания
1. В чем преимущества хранения текстов в файлах по сравнению с бумажным способом хранения?
2. Что такое гипертекст? Какие возможности предоставляет гипертекст пользователю?
3. Каков размер алфавита, используемого в компьютерах для представления текстов?
4. Сколько места в памяти компьютера занимает код одного символа?
5. Что такое таблица кодировки? Как называется таблица кодировки, используемая в большинстве современных персональных компьютеров?
6. Закодируйте в двоичной форме свою фамилию, записанную латинскими буквами, используя табл. 3.1.
7. Познакомьтесь с кодовой страницей, используемой в школьных компьютерах. Выясните, соблюдается ли принцип последовательного кодирования алфавита из русских букв (их называют кириллицей).
8. Закодируйте короткую фразу на русском языке. Обменяйтесь с соседом по парте полученными кодами и декодируйте тексты друг друга.
Электронное приложение к уроку

|
|
Вернуться к материалам урока |
|
|
|
 |
 |
 |
|
|
|
|
|
Презентации, плакаты, текстовые файлы |
 |
Ресурсы ЕК ЦОР |
|
|
|
Видео к уроку |
|
|
Cкачать материалы урока

