Урок 17
§14. Кодирование текстовой информации
Содержание урока:
Кодирование текстовой информации
14.1. Кодировка ASCII и её расширения
14.3. Информационный объём текстового сообщения
 |
САМОЕ ГЛАВНОЕ Вопросы и задания |
 |
||
| 14.3. Информационный объём текстового сообщения |  |
Материалы к уроку |

САМОЕ ГЛАВНОЕ
Текстовая информация по своей природе дискретна, т. к. представляется последовательностью отдельных символов.
В памяти компьютера хранятся специальные кодовые таблицы, в которых для каждого символа указан его двоичный код. Все кодовые таблицы, используемые в любых компьютерах и любых операционных системах, подчиняются международным стандартам кодирования символов.
Основой для компьютерных стандартов кодирования символов послужил код ASCII, рассчитанный на передачу только английского текста. Расширения ASCII — кодировки, в которых первые 128 символов кодовой таблицы совпадают с кодировкой ASCII, а остальные (со 128-го по 255-й) используются для кодирования букв национального алфавита, символов национальной валюты и т. п.
В 1991 году был разработан новый стандарт кодирования символов, получивший название Unicode (Юникод), позволяющий использовать в текстах любые символы любых языков мира. Кодировки Unicode позволяют включать в один документ символы самых разных языков, но их использование ведёт к увеличению размеров текстовых файлов.
Вопросы и задания
1. Какова основная идея представления текстовой информации в компьютере?
2. Что представляет собой кодировка ASCII? Сколько символов она включает? Какие это символы?
3. Как известно, кодовые таблицы каждому символу алфавита ставят в соответствие его двоичный код. Как, в таком случае, вы можете объяснить вид таблицы 3.8 «Кодировка ASCII»?
4. С помощью таблицы 3.8:
1) декодируйте сообщение 64 65 73 6В 74 6F 70;
2) запишите в двоичном коде сообщение TOWER;
3) декодируйте сообщение
01101100 01100001 01110000 01110100 01101111 01110000
5. Что представляют собой расширения ASCII-кодировки? Назовите основные расширения ASCII-кодировки, содержащие русские буквы.
6. Сравните подходы к расположению русских букв в кодировках Windows-1251 и КОИ-8.
7. Представьте в кодировке Windows-1251 текст «Знание — сила!»:
1) шестнадцатеричным кодом;
2) двоичным кодом;
3) десятичным кодом.
8. Представьте в кодировке КОИ-8 текст «Дело в шляпе!»:
1) шестнадцатеричным кодом;
2) двоичным кодом;
3) десятичным кодом.
9. Что является содержимым файла, созданного в современном текстовом процессоре?
10. В кодировке Unicode на каждый символ отводится 2 байта. Определите в этой кодировке информационный объём следующей строки:
Где родился, там и сгодился.
11. Набранный на компьютере текст содержит 2 страницы. На каждой странице 32 строки, в каждой строке 64 символа. Определите информационный объём текста в кодировке Unicode, в которой каждый символ кодируется 16 битами.
12. Текст на русском языке, первоначально записанный в 8-битовом коде Windows, был перекодирован в 16-битную кодировку Unicode. Известно, что этот текст был распечатан на 128 страницах, каждая из которых содержала 32 строки по 64 символа в каждой строке. Каков информационный объём этого текста?
13. В текстовом процессоре MS Word откройте таблицу символов (вкладка Вставка ⇒ Символ ⇒ Другие символы):
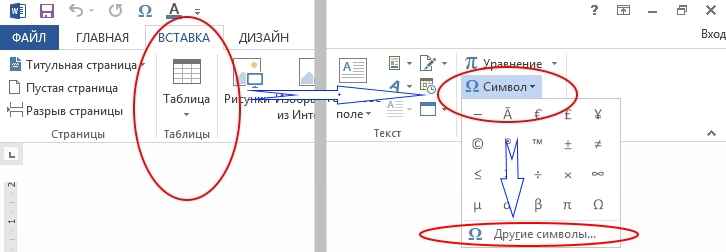
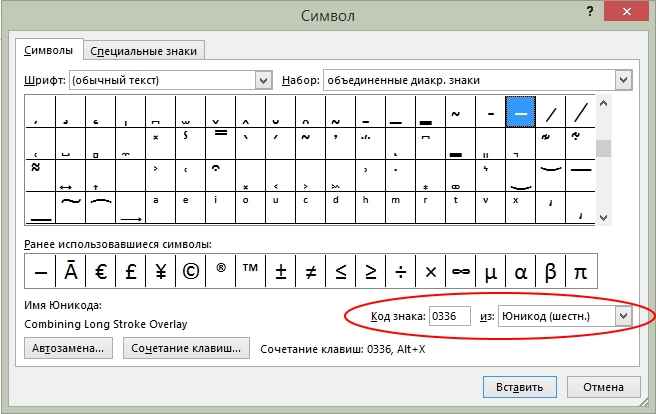
В поле Шрифт установите Times New Roman, в поле из — кириллица (дес.).
Вводя в поле Код знака десятичные коды символов, декодируйте сообщение:
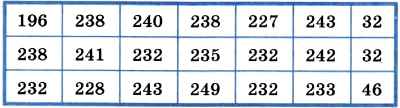
Cкачать материалы урока
