Уроки 6 - 9
Сжатие данных без потерь
(§3. Сжатие данных)
Содержание урока
Основные понятия
Основные понятия
Для того чтобы сэкономить место на внешних носителях (жёстких дисках, флэш-дисках) и ускорить передачу данных по компьютерным сетям, нужно сжать данные — уменьшить информационный объём, сократить длину двоичного кода. Это можно сделать, устранив избыточность использованного кода.
Например, пусть текстовый файл объёмом 10 Кбайт содержит всего четырех различных символа: латинские буквы «А», «В», «С» и пробел. Вы знаете, что для кодирования одного из четырёх возможных вариантов достаточно 2 битов, поэтому использовать для его передачи обычное 8-битное кодирование символов невыгодно. Можно присвоить каждому из четырёх символов двухбитные коды, например, так:
А — 00, В — 01, С — 10, пробел — 11.
Тогда последовательность «АВА САВАВА», занимающая 10 байтов в однобайтной кодировке, может быть представлена как цепочка из 20 битов:
00010011100001000100
Таким образом, нам удалось уменьшить информационный объём текста в 4 раза, и передаваться он будет в 4 раза быстрее. Однако непонятно, как раскодировать это сообщение, ведь получатель не знает, какой код был использован. Выход состоит в том, чтобы включить в сообщение служебную информацию — заголовок, в котором каждому коду будет сопоставлен ASCII-код символа. Условимся, что первый байт заголовка — это количество используемых символов N, а следующие N байтов — это ASCII-коды этих символов.
В данном случае заголовок занимает 5 байтов и выглядит так:
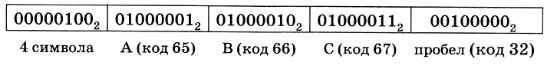
Файл, занимающий 10 Кбайт в 8-битной кодировке, содержит 10 240 символов. В сжатом виде каждый символ кодируется двумя битами, кроме того, есть 5-байтный заголовок. Поэтому сжатый файл будет иметь объём
5 + 10240 • 2/8 байтов = 2565 байтов.
 Коэффициент сжатия — это отношение размеров исходного и сжатого файлов.
Коэффициент сжатия — это отношение размеров исходного и сжатого файлов.
В данном случае удалось сжать файл почти в 4 раза, коэффициент сжатия равен
k = 10 240/2565 ≈ 4.
Если принимающая сторона «знает» формат файла (заголовок + закодированные данные), она сможет восстановить в точности его исходный вид. Такое сжатие называют сжатием без потерь. Оно используется для упаковки текстов, программ, данных, которые ни в коем случае нельзя искажать.
Сжатие без потерь — это такое уменьшение объёма закодированных данных, при котором можно восстановить их исходный вид из кода без искажений.
За счёт чего удалось сжать файл? Только за счёт того, что в файле была некоторая закономерность, избыточность — использовались только 4 символа вместо полного набора.
Следующая страница  Алгоритм RLE
Алгоритм RLE
Cкачать материалы урока
