Уроки 25 - 29
Таблицы. Основные понятия. Реляционные базы данных
(§13. Таблицы. §15. Реляционная модель данных. §16. Работа с таблицей. §17. Создание однотабличной базы данных)
Содержание урока
§13. Таблицы
Индексы
§15. Реляционная модель данных
§16. Работа с таблицей
§17. Создание однотабличной базы данных
§13. Таблицы
Индексы
Представим себе, что в таблице с адресами и телефонами, о которой мы говорили выше, записаны данные большого количества людей (в реальных базах данных могут быть миллионы записей). Как найти всех Ивановых?
Учтём, что записи расположены в таблице в том порядке, в котором они вводились (возможно, без всякого порядка). Если эту задачу решает человек, он, скорее всего, будет просматривать поле Фамилия с первой до последней записи, отмечая всех с фамилией Иванов. Такой поиск называется линейным — он требует просмотра всех записей (вспомните линейный поиск элемента в массиве). Если в таблице 1024 записи, придётся сделать 1024 сравнения, в больших базах линейный поиск будет работать очень медленно.
Теперь представим себе, что записи отсортированы по фамилии в алфавитном порядке. Возьмём запись, стоящую в середине таблицы (если в таблице 1024 записи, возьмём 512-ю) и сравним фамилию с нужной. Допустим, в 512-й записи фамилия — Конюхов. Поскольку нам нужны Ивановы, все они заведомо находятся в верхней половине таблицы, поэтому всю вторую половину можно вообще не смотреть. Таким образом, мы в два раза уменьшили область поиска. Далее проверяем среднюю из оставшихся записей (256-ю) и повторяем процесс до тех пор, пока не найдём Иванова или в области поиска не останется больше записей. Как вы знаете, такой поиск называется двоичным (вспомните материал учебника 10 класса). Он позволяет искать очень быстро: если в базе N записей, то придется сделать всего около log2N сравнений. Например, для N = 1024 получаем 11 сравнений вместо 1024, т. е. мы смогли ускорить поиск почти в 100 раз! Для больших N ускорение будет еще более значительным.
Однако у двоичного поиска есть и недостатки:
• записи должны быть предварительно отсортированы по нужному полю;
• можно искать только по одному полю.
На практике искать нужно по нескольким полям в каждой таблице и нет возможности каждый раз сортировать записи (это очень долго для больших баз). Как же в такой ситуации обеспечить быстрый поиск? Как часто бывает в программировании, можно увеличить скорость работы алгоритма за счёт расхода дополнительной памяти.
Наверное, вы видели, что для ускорения поиска во многие книги включают индекс — список ключевых слов с указанием страниц, где они встречаются. В базах данных специально для поиска создаются дополнительные таблицы, которые также называются индексами.
 Индекс — это вспомогательная таблица, которая служит для ускорения поиска в основной таблице.
Индекс — это вспомогательная таблица, которая служит для ускорения поиска в основной таблице.
Простейший индекс — это таблица, в которой хранится значение интересующего нас поля основной таблицы (например, Фамилия) и список номеров записей, где такое значение встречается. Записи в индексе упорядочены (отсортированы) по нужному полю, т. е. для приведённой на рис. 3.6 таблицы индекс по полю Фамилия выглядит так, как на рис. 3.7.
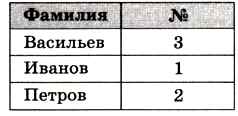
Рис. 3.7
Теперь, если нам нужны люди с фамилией Иванов, мы можем искать номера Ивановых в индексе, используя быстрый двоичный поиск (там фамилии стоят по алфавиту!). Затем, когда номера нужных записей определены, данные Ивановых можно взять из основной таблицы. Заметим, что искать что-то в основной таблице уже не нужно. Таким образом, можно использовать двоичный поиск по разным полям (даже по комбинациям нескольких полей). Однако нужно учитывать, что:
• для каждого типа поиска приходится строить новый индекс, он будет занимать дополнительное место во внешней памяти (например, на жёстком диске);
• при любом изменении таблицы (добавлении, изменении и удалении записей) необходимо перестраивать индексы так, чтобы сохранить требуемый порядок сортировки; к счастью, современные СУБД делают это автоматически без участия пользователя, но это может занимать достаточно много времени.
Для тренировки самостоятельно постройте вручную индексы по полям Имя, Адрес и Телефон.
Следующая страница  Целостность базы данных
Целостность базы данных
Cкачать материалы урока
