Уроки 25 - 29
Таблицы. Основные понятия. Реляционные базы данных
(§13. Таблицы. §15. Реляционная модель данных. §16. Работа с таблицей. §17. Создание однотабличной базы данных)
Содержание урока
§13. Таблицы
§15. Реляционная модель данных
Математическое описание базы данных
Нормализация
§16. Работа с таблицей
§17. Создание однотабличной базы данных
§15. Реляционная модель данных
Нормализация
Представим себе, что все данные о рейсах авиакомпании «ZX-Аэро» собраны в одной таблице:

Мы сразу видим, что в таблице есть избыточность (дублирование): многие данные (названия городов и типов самолётов) хранятся несколько раз. При этом для хранения данных-дубликатов расходуется дополнительное место на диске, что может привести к его преждевременному заполнению и выходу из строя всей информационной системы.
Есть и другая проблема: при вводе всех данных вручную оператор может сделать опечатку и, например, вместо «Санкт-Петербург» ввести «СанктПетербург». В этом случае нарушается целостность базы данных, потому что в ней хранится название несуществующего города.
Чтобы избежать этих проблем, при проектировании базы данных обычно выполняют её нормализацию.
 Нормализация — это изменение структуры базы данных, которое устраняет избыточность и предотвращает возможные нарушения целостности.
Нормализация — это изменение структуры базы данных, которое устраняет избыточность и предотвращает возможные нарушения целостности.
В теории реляционных баз данных существует несколько уровней нормализации (так называемых нормальных форм). Мы покажем некоторые принципы нормализации на примерах.
1. Любое поле должно быть неделимым. Это значит, что таблицу вида, показанного на рис. 3.18, необходимо переделывать.

Рис. 3.18
Здесь поле Сотрудник нужно разделить на три: Фамилия, Имя и Отчество. Поле Телефоны содержит два телефона: домашний и мобильный. Поэтому нужно изменить таблицу, по крайней мере, так (рис. 3.19).

Рис. 3.19
2. Любое неключевое поле должно зависеть от ключа таблицы. Например, в таблице на рис. 3.20 ключ — это регистрационный номер автомобиля.

Рис. 3.20
Понятно, что телефон зависит не от регистрационного номера, а от владельца. Поэтому его нужно выносить в другую таблицу (рис. 3.21).
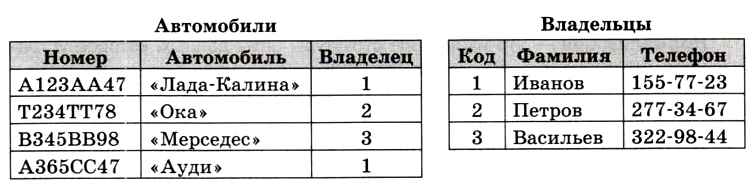
Рис. 3.21
Заметим, что здесь мы присвоили каждому владельцу уникальный числовой код и ввели в таблицу Владельцы суррогатный (искусственный) ключ.
3. Не должно быть одинаковых по смыслу полей. Например, фирма торгует бананами, апельсинами и яблоками и хранит данные о ежедневных продажах этих товаров (в килограммах) в такой таблице (рис. 3.22).
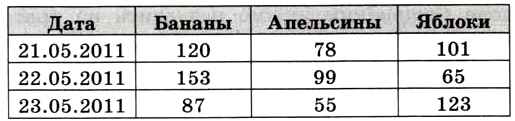
Рис. 3.22
Недостаток этой таблицы в том, что поля Бананы, Апельсины и Яблоки — одинаковые по смыслу, это товары. Если фирма начнёт работать с новым видом товара, придется добавлять новый столбец, т. е. менять структуру таблицы (это делает уже не пользователь, а администратор базы данных). Поэтому нужно выделить все товары в отдельную таблицу (рис. 3.23).
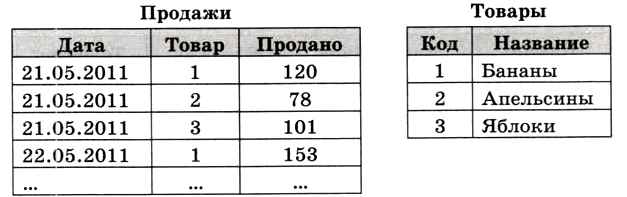
Рис. 3.23
С одной стороны, число строк в таблице увеличилось, но с другой — организация данных улучшилась. Теперь для добавления в базу нового товара достаточно добавить одну запись в таблицу Товары, структуру таблиц переделывать не нужно.
4. Не нужно хранить данные, которые могут быть вычислены. Предположим, что бухгалтер фирмы вводит в таблицу доходы и расходы фирмы за каждый месяц (в тысячах рублей), а также прибыль — разницу между доходом и расходом (рис. 3.24).
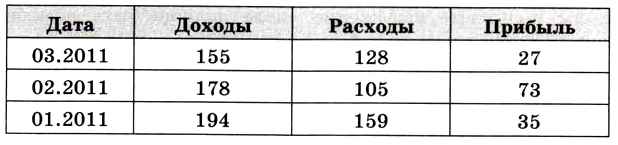
Рис. 3.24
В самом деле, поле Прибыль нужно удалить из таблицы, поскольку это значение можно рассчитать как разность двух других. Во-первых, оно занимает лишнее место на диске, во-вторых, появляется возможность нарушения целостности — при ошибке ввода может оказаться, что прибыль не равна разности доходов и расходов, и данные станут противоречивыми. Позже вы узнаете, что все вычисления в базах данных можно делать с помощью запросов, которые СУБД выполняет по требованию пользователя, т. е. тогда, когда результаты этих вычислений действительно нужны.
Нужно понимать, что нормализация имеет свои недостатки. Например, выборка данных из нескольких таблиц может выполняться очень долго, и для ускорения работы иногда приходится применять денормализацию — специально вводить избыточность, нарушая требования нормализации. Например, в предельном случае можно все данные свести в одну таблицу. Однако при этом необходимо принимать меры для поддержки целостности базы данных.
Следующая страница  Вопросы и задания
Вопросы и задания
Cкачать материалы урока
